
![]() Recently my colleague (by Percona) Yves Trudeau and colleague (by industry) Marco Tusa
Recently my colleague (by Percona) Yves Trudeau and colleague (by industry) Marco Tusa
published their materials on Amazon Aurora. Indeed, Amazon Aurora is a hot topic these days, and we have a stream of customer inquiries regarding this technology. I’ve decided to form my own opinion, and nothing is better than a personal, hands-on experience, which I am going to share.
The materials I will refer to:
Presentation [1] gives a good general initial overview. However, there is one statement the presenter made I’d like to highlight. It is “Amazon Aurora is a MySQL-compatible relational database engine that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases.”
This does not claim that Amazon Aurora is an open source database, but certainly the goal is to make Amazon look comparable to open source.
I would like to make clear that Amazon Aurora is not open source. Amazon Aurora is based on the Open Source MySQL Edition, but is not open source by itself; it is a proprietary, closed-source database.
By choosing Amazon Aurora you are fully dependent on Amazon for bug fixes or upgrades. In this regard you are locked-in to Amazon RDS. Though it is not the same lock-in as to a commercial database like Oracle or MS-SQL. You should still be able to relatively easily migrate your application to a community MySQL.
Amazon uses a GPLv2 hole, which allows it to not publish source code in a cloud model. How is Amazon Aurora different from Percona Server or MariaDB? Both of these projects are required to publish their sources. It comes to the distribution model. GPLv2 makes a restriction on a traditional distribution model: if you download software or receive a hard copy of software binaries, you also have rights to request corresponding source code. This is not the case with cloud computing: there you do not download anything, just launch an instance. GPLv2 does not make any restrictions for this case, so Amazon is in compliance with GPLv2.
Bug fixes
Speaking of bug fixes, Amazon Aurora exposes itself as "version: 5.6.10, version_comment: MySQL Community Server (GPL)". MySQL 5.6.10 was released on 2013-02-05. That was 2.5 year ago. It is not clear if Aurora includes 2.5 years worth of bug fixes and just did not update the version, or if this is really binaries based on a 2.5 year old code base.
For example, let’s take the MySQL bug http://bugs.mysql.com/bug.php?id=70577, which was fixed in 5.6.15. I do not see the bug fix present in Amazon Aurora 5.6.10.
Another bug, http://bugs.mysql.com/bug.php?id=68041, which was fixed in MySQL 5.6.13, but is still present in Amazon Aurora.
What about InnoDB’s code base? The bug, http://bugs.mysql.com/bug.php?id=72548, with InnoDB fulltext search, was fixed in MySQL 5.6.20 (released more than a year ago, on 2014-07-31) and is still present in Amazon Aurora.
This leaves me with the impression that the general Aurora codebase was not updated recently.
Although it seems Amazon changed the innodb_version. Right now it is 1.2.10. A couple of weeks ago it was innodb_version: 1.2.8
My question here, does Amazon have the ability to keep up with MySQL bug fixes and regularly update their software? So far it does not seem so.
Amazon Aurora architecture:
My understanding of Amazon Aurora in simplified form is the following:
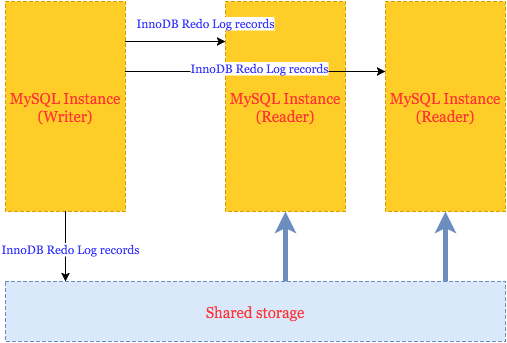
That is, all Aurora instances share the same storage, and makes it very easy to start new “Reader” instances over the same data.
Communication between Writer (only 1 Writer allowed) and Readers is done by transferring records similar to InnoDB redo log records. And this really limits how many Writers you can have (only one). I do not believe it is possible to implement a proper transactional coordinator between two Writers based on redo records.
A similar way is used to update data stored on shared storage: Aurora just applies redo log records to data.
So, updating data this way, Aurora is able to:
Aurora makes claims about significant performance improvements, but we need to keep in mind that EACH WRITE goes directly to storage and it has to be acknowledged by 4 out of 6 copies (synchronous writes). Aurora Writer works in some kind of “write through” mode – this is needed, as I understand, to make Reader see changes immediately. I expect it also comes with a performance penalty, so whether the performance gain is bigger than the performance penalty will depend on the workload.
Now, I should give credit to the Amazon engineering team for a proper implementation of shipping and applying transactional redo logs. It must have required a lot of work to change the InnoDB engine, and as we see it took probably a year (from the announcement to the general availability) for Amazon to stabilize Aurora. Too bad Amazon keeps their changes closed, even when the main codebase is an open source database.
Work with transactional isolation
Distributed computing is especially complicated from a transactional processing point of view (see for example a story), so I also wanted to check how Amazon Aurora handles transactional isolation levels on different instances.
Fortunately for Aurora, they have an easy way out, allowing only read statements on Readers, but we still check isolation in some cases.
It seems that the only TRANSACTION ISOLATION level supported is REPEATABLE-READ. When I try to change to SERIALIZABLE or READ-COMMITTED, Aurora accepts this without an error, but silently ignores it. tx_isolation stays REPEATABLE-READ.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
mysql> SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; Query OK, 0 rows affected (0.00 sec) mysql> SELECT @@GLOBAL.tx_isolation, @@tx_isolation; +-----------------------+-----------------+ | @@GLOBAL.tx_isolation | @@tx_isolation | +-----------------------+-----------------+ | REPEATABLE-READ | REPEATABLE-READ | +-----------------------+-----------------+ 1 row in set (0.00 sec) mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; Query OK, 0 rows affected (0.00 sec) mysql> SELECT @@GLOBAL.tx_isolation, @@tx_isolation; +-----------------------+-----------------+ | @@GLOBAL.tx_isolation | @@tx_isolation | +-----------------------+-----------------+ | REPEATABLE-READ | REPEATABLE-READ | +-----------------------+-----------------+ 1 row in set (0.00 sec) |
Actually, there I face another worrisome behaviour: silent changes in Aurora without notification.
I am pretty sure, that when a couple of weeks ago I tried to use SERIALIZABLE level, it failed with an error: "SERIALIZABLE is not supported". Now it just silently ignores it. So I assume Amazon continues to make changes. I guess this is one of the changes from innodb_version 1.2.8 to 1.2.10. Is there a full Changelog we can see?
The lack of SERIALIZABLE level is not a big problem in my opinion. In the end, we know that Percona XtraDB Cluster does not support it either.
But not being able to use READ-COMMITTED might be an issue for some applications; you need to check if your application is working properly with READ-COMMITTED silently set as REPEATABLE-READ.
I found another unusual behaviour between the reader and writer when I tried to execute ALTER TABLE statement on the Writer (this is another hard area for clusters: to keep a data dictionary synchronized).
Scenario:
READER:
execute long SELECT col1 FROM tab1
WRITER:
while SELECT running, execute ALTER TABLE tab1 ADD COLUMN col2 ;
Effect: SELECT on READER fails immediately with an error: "ERROR 1866 (HY000): Query execution was interrupted on a read-only database because of a metadata change on the master"
So there again I think Aurora does its best given architectural limitations and one-directional communication: it just chooses to kill read statements on Readers.
Query cache
I should highlight improvements to query_cache as a good enhancement. Query cache is enabled by default and Amazon fixed the major issue with MySQL query cache, which is when update queries may stall for a long time waiting on invalidation of query cache entries. This problem does not exist in Amazon Aurora. Also Amazon adjusts query_cache to work properly on Writer-Reader pair. Query_cache on the Reader gets invalidated when data is changed on Writer.
Config review
Let’s make a quick review of the MySQL configuration that Aurora proposes.
These are variables which are set by default and you can’t change:
|
1 2 3 4 5 |
| innodb_change_buffering | none | | innodb_checksum_algorithm | none | | innodb_checksums | OFF | | innodb_doublewrite | OFF | | innodb_flush_log_at_trx_commit | 1 | |
Disabled doublewrite and checksums is not a surprise, I mentioned this above.
Also innodb_flush_log_at_trx_commit is strictly set to 1, I think it is also related to how Aurora deals with InnoDB redo log records.
Disabled innodb_change_buffering is also interesting, and it can’t be good for performance. I guess Amazon had to disable any buffering of updates so changes are immediately written to the shared storage.
Diagnostic
Traditionally RDS does not provide you with good access to system metrics like vmstat and iostat, and it makes troubleshooting quite challenging. MySQL slow-log is also not available, so it leaves us with only PERFORMANCE_SCHEMA (which is OFF by default)
One good thing is that we can access SHOW GLOBAL STATUS, and this can also be used for monitoring software.
Interesting status after a heavy write load, these counters always stay at 0:
|
1 2 3 4 |
| Innodb_buffer_pool_pages_dirty | 0 | | Innodb_buffer_pool_bytes_dirty | 0 | | Innodb_buffer_pool_pages_flushed | 0 | | Innodb_pages_written | 0 | |
I think this supports my guess about the architecture, that Aurora does not keep any changed pages in memory and just directly writes everything to storage.
Final thoughts
I will follow up this post with my benchmarks, as I expect the proposed architecture comes with serious performance penalties, although removing binary logs and eliminating doublewrites should show a positive improvement.
In general I think Amazon Aurora is a quite advanced proprietary version of MySQL. It is not revolutionary, however, and indeed not “reimagined relational databases” as Amazon presents it. This technology does not address a problem with scaling writes, sharding and does not handle cross-nodes transactions.
As for other shortcomings, I see there is no public bug database, no detailed user documentation and Aurora’s code is based on old MySQL source code.
Resources
RELATED POSTS





We were going through similar issue (with unexpected changes to database behaviour) when MySQL 5.6 was introduced. You may want to take a look at my colleague’s post on support forum: https://forums.aws.amazon.com/thread.jspa?messageID=474345
Yup, I noticed the lack of
performance_schemaon Aurora. I was attempting to help someone instrument their Aurora DB with Prometheus mysqld_exporter, but we could only get basic stats and none of the fun details you get out ofperformance_schema.events_statements_summary_by_digest. I wasn’t able to figure out a way to get it turned on. 🙁MyRocks (MySQL+RocksDB) doesn’t need a change buffer. Non-unique secondary index maintenance doesn’t require reads before the write. Maybe Aurora is the same.
There are at least 2 kinds of repeatable-read — Postgres-style and InnoDB-style. Which style do they provide?
https://github.com/MariaDB/webscalesql-5.6/wiki/Cursor-Isolation
Thanks Vadim. I am looking forward to your benchmark observations.
We’ve pulled back a hundred or so bug fixes. A number of the others aren’t applicable given the extensive changes to the code base. We’ll look into the specific ones you mention and pull them in if they’re not already in an upcoming patch.
Buffer page writes are zero because Aurora only writes log pages to the storage tier. That tier generates data block records on its own (similar to how log-structured storage systems work). No checkpointing or writing of dirty data blocks out of cache is required.
We disable flush_log_at_txn_commit modifications because it seemed like just a benchmark performance hack – it’s hard to believe a customer could really tolerate this in a real production system. It’s easy to reenable if it turns out that real customers want it.
We have our own CRC system which is pretty deeply integrated into how we write over the network, store data, scrub blocks etc. Which is why the MySQL checksum approach is disabled.
We’ll look into the other behavior anomalies you encountered.
Mark,
Aurora is heavily modified InnoDB, so on a Writer it should work InnoDB-like (I did not test this actually). And Reader does not support statements that change data, I do not think we can actually test this. Still it would make sense to make InnoDB-like snapshots…
Anurag,
Thank you for the comment.
As I understand there is no changelog and versions to understand what bugs where fixed in which version?
Interesting that they have invented InnoDB version 1.2.10. According to Chris Calendar’s nice blog post (http://www.chriscalender.com/innodb-plugin-versions/), such a version never existed. MySQL 5.6.10 started the practice of synchronized InnoDB versions.
Anurag – flush_log_at_txn_commit=0 is a benchmark special, but flush_log_at_txn_commit=2 is not and there are many deployments that benefit from it
I have been poking around for my queries on Amazon Aurora on varies platforms on internet but glad I got a more formal version of the answer right here. Looking forward to more improvements in future, good to see Aurora is addressing the bugs in real time.
a couple of other quick points.
Aurora does support performance schema – we just turn it off by default as it, as currently implemented, has significant overhead in MySQL (IMO).
On transaction isolation, you can change the isolation level on the write-master node and should see all the behavior you’d expect. The anomaly you’re seeing is on the read-replica, which 1) is read-only, and 2) inherits the write-ordering semantics of the write-master node. I would agree that the behavior is not intuitive, and we’ll put in a better error message.
I should add that writes are not synchronous as you assumed and would recommend you take a look at my talk from 2015 reInvent (you can find it on YouTube searching for DAT405), where I describe how write processing works in some detail. Basically, everything is async, including read replicas (which is where the lag comes from), but is all based on redo log records. We’re very focused on building a highly concurrent, high throughput system, and batching and asynchronous processing are basic techniques in doing so.
I also agree that we can do a better job with the version string, and will take a look at updating it.
Mark, I’ll take a look at my biases related to flush_log_at_txn_commit=2. I’ve seen a small number of customers leveraging it to improve write throughput and it is certainly an easy win for us if we were to enable it in Aurora. I have a niggling suspicion that it leaves open the possibility of metadata/data corruptions, but can explore whether that is true or not.
Mark, Aurora provides InnoDB-style repeatable reads.
Vadim, we provide release notes with each patch. I’ll ask my team to ensure they provide sufficient detail to understand which bugs we’ve fixed. And use a better version scheme.
Anurag,
Thank you for all followup comments.
I do not quite follow re: changing an isolation mode on Writer.
It is gives a great flexibility of you can change an isolation mode *per transaction*.
That is some *READ-ONLY* transactions on Reader I would like to run in Repeatable-Read, and some other in Read-Commited. Is it possible?
Anurag,
While performance schema can be enabled for Aurora the current advice from Amazon is to not do that – there appears to be a problem with erroneous failovers in cluster when it’s turned on. I hope you fix this one soon. Vadim, slow query logs are certainly available and were critical in helping us diagnose a problem with binary log purging on Aurora last week. Only FILE logging is supported.
Mark, turns out we _do_ support flush_log_at_txn_commit=2. It was a post-launch fix based on customer request. Apologies for the incorrect info.
Vadim, IMO, the first responsibility of a replication scheme is to ensure that the replica sees the same data as the master. That’s hard to do in any logical replication scheme (e.g. bin log replication), particularly so in MySQL where replication is not cognizant of ordering happening within the storage engine. For that reason (amongst others), I tend to favor physical (redo-based) replication for most customer use cases. Aurora does support bin log replication, both as source and as target, for customers who need the flexibility afforded by logical replication.
The specific example you provide isn’t currently supported by Aurora under physical replication, though of course you can set up bin log replication to accomplish this. There isn’t an intrinsic reason for this to be the case. The selects on the replica are implemented as you’d expect – setting a read view and applying undo to obtain the read view version of a block if the current version is in future of the view – so read committed vs repeatable read is a matter of not resetting the read view with a subsequent statement. We’ll consider it if we hear customer demand.
If I login to Aurora,status (that is s in command line client) indicates, that I’m using GPL licensed software:
Your MySQL connection id is 82422
Server version: 5.6.10 MySQL Community Server (GPL)
I’m not a lawyer, but I would expect that it is open source (no, I didn’t try to find source code).
Georg,
My read of GPLv2 (I am not a lawyer either, so this should not be taken as a legal advise in anyway, only as my personal opinion)
is that GPLv2 requires to open source code only if you distribute software as by downloads or by hard copies (USB drives, network routers, etc).
The model, where you launch software by a mouse click, does not fit into GPLv2 distribution requirement.
Thank you for your interesting article.
I translated this article for users in Japan
https://yakst.com/ja/posts/3550
If there is any problem, please contact me.
Thank you again.
Update queries seems super slow in Aurora. My table1 has 6 millions records and I’m executing this update table1 set comment=’rejected’ where id in (select id from table2) — it took almost 2hours to run.
table2 has 2000 records only.
Wow, that “running in the cloud” GPLv2 loophole is extremely sketchy and I hope they plug that in the next version of GPL. However, that won’t stop Amazon from using what they already have.
It feels very wrong how Amazon is using open-source code to create a closed-source system. While what they’re doing is legally ok, it certainly feels like it violates the spirit of the licensing agreement.
There is a license that would prevent this (AGPL), butone must also wonder how useful having the source code would be without having access to the proprietary infrastructure behind it.
Vadim, Anurag,
With innodb_doublewrite OFF, can it cause data corruption in Aurora.
Because we are currently doing MySQL 5.6.3* vs Aurora benchmark.
One of the test was record insertion (2 days ago) -> MySQL 5.6.3* without raid and innodb_doublewrite = 0 and innodb_flush_log_at_trx_commit = 0 performing better than Aurora (We have a SP that does those kind of inserts).
And https://bugs.mysql.com/bug.php?id=78853, is fixed in MySQL 5.6.30 and not in current version of Aurora (Which i myself have tested and verified).
So here we are still thinking between MySQL 5.6.3* vs Aurora.
what are the risk factors in Aurora having innodb_doublewrite = 0? Can it cause data corruption or result in any kind of data loss ?
It would be great if you could please suggest your thoughts on it.
Thanks in Advance,
Harish