
Section I: Fractal Tree and Optimization Overview
Tokutek’s Fractal Tree® technology provides fast performance by injecting small messages into buffers inside the Fractal Tree index. This allows writes to be batched, thus eliminating I/O that is required in traditional B-tree indexes for every operation. Additional background information on how Fractal Trees operate can be found in Zardosht Kasheff’s blog entitled, TokuMX Fractal Tree Indexes, What Are They? Don’t be thrown off by the title, Fractal Tree Indexes access data in the same way for TokuDB as they do for TokuMX.
For tables whose workload pattern is a high number of sequential deletes, some operational maintenance is required to ensure consistently fast performance. If this is not done, delete messages and garbage can exist in the Fractal Tree resulting in slower queries. Running the optimize command on these tables will clean the tables up and restore performance, but can be intrusive in the time it takes to execute and the resources it consumes while running. 7.5.5 addresses these issues.
To understand the 7.5.5 improvements, it would be good to review what occurs in the tree to require maintenance at all. The following diagram can be used to visualize what occurs when deleting a high number of sequential rows on the left side of a Fractal Tree index.
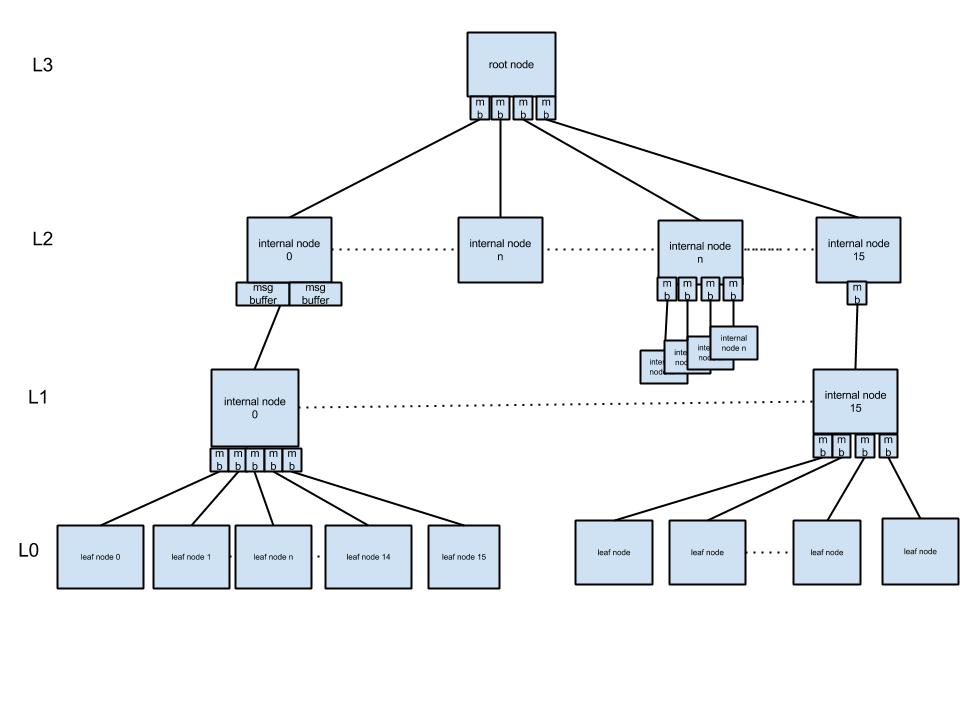
When a table is created, a tree is built and all the rows are located in the leaves at level 0 (L0). A delete operation does not delete the actual rows in the leaf, the operation results in putting delete messages into buffers on nodes in the tree. These are denoted as msg buffer or mb in the diagram. The delete message may be promoted to the leaf node depending on depth and applied immediately. However, if the tree is deep, then the delete message is buffered and could be located higher up the tree, ie, in L1 or L2.
The following can occur after a high volume of sequentially increasing deletes have taken place. Assume a table has an index, col1, of type int whose starting value is 0 and incremented sequentially. A select min(col1) from table command will traverse down to the leftmost leaf node, find a row where col1=0, look for delete messages, find one, go back to the leaf node to find col1=1, find another delete message in a buffer, and continue searching until it finds a row where docid has no associated delete message. In the case where the first 100 million rows of the table have been deleted, there will be 100 million delete messages that have been injected on the left side of the tree in a 200 million row table. In this case, the process of finding a row and an associated delete message can occur a maximum of 100 million times.
To flush these messages down the tree to the basement nodes and remove the deleted rows from the leaves, a cleaner thread runs in the background. On a busy system this may not keep up with the workload and the optimize command will need to be issued. Optimizing the table will then result in a measurable difference in performance.
In a production environment where multiple tables contain millions of rows and multiple indexes, the impact of running the optimize can be significant as the nodes are brought in from disk, messages flushed to the leaf nodes and rows deleted, followed by a flush back to disk. When this is done for every index on a large table, it can take hours to complete and can degrade performance.
Section II: 7.5.5 Optimization Improvements
Now we’re finally caught up to the title of the blog. In 7.5.5 three improvements have been made to the optimize functionality to improve the way to handle tree optimizations.
Hot Optimize Throttling
By default, table optimization will run with all available resources. To limit the amount of resources the optimize command consumes, it is possible to limit the speed of table optimization. The ‘tokudb_optimize_throttle’ session variable determines an upper bound on how many Fractal Tree leaf nodes per second are optimized. The default is 0 (no upper bound) with a valid range of [0,1000000]. To calculate the number of MB/sec, multiply the number of nodes times the size of the nodes. The size is defined by the tokudb_block_size variable whose default is 4194304.
Optimize a Single Index of a Table
To optimize a single index in a table, the ‘tokudb_optimize_index_name’ session variable can be set to select the index by name. If a query is slow when an explain plan shows that it leverages a specific index, this index can be optimized.
Optimize a Subset of a Fractal Tree Index
For patterns where the left side of the tree has many deletions, a common pattern with increasing id or date values where the oldest data is deleted, it may be useful to delete a percentage of the tree. In this case, it’s possible to optimize a subset of a Fractal Tree starting at the left side. The ‘tokudb_optimize_index_fraction’ session variable controls the size of the sub tree. Valid values are in the range 0.0 to 1.0 with default of 1.0 (optimize the whole tree).
Tying It All Together:
If a user wants to optimize the left half of the primary key on table t1 and throttle it to only optimize 100 nodes per second, the following sequence of commands would be issued:
set tokudb_optimize_throttle=100;
set tokudb_optimize_index_name=’primary’;
set tokudb_optimize_index_fraction=0.49;
optimize table t1;
These three improvements can make a signficant impact on the operational management of tables.
Section III: Validation
The following example was run with tokudb_cache_size=1073741824 in order to ensure the table will not fit in RAM.
Consider a table of the following format:
CREATE TABLE t1 (
docid int(11) NOT NULL DEFAULT ‘0’,
somevalue int(11) DEFAULT NULL,
PRIMARY KEY (docid)
) ENGINE=TokuDB DEFAULT CHARSET=latin1 ;
Using the t1 table as an example, the following stored procedure can be used to create rows in the table, then delete the lower half of those rows by primary key:
more popudelt1.sql
delimiter //
drop procedure popudelt1 //
create procedure popudelt1(p1 int)
/* Insert into table t1 until p1 rows have been inserted */
begin
set @x=0;
repeat
start transaction;
repeat
set @x = @x + 1;
insert into t1 (docid, somevalue) values (@x, @x) on duplicate key update somevalue=@x;
until mod(@x,100000)= 0
end repeat;
commit;
until @x >= p1
end repeat;
/* Now delete half of the rows from table t1 */
delete from t1 where docid <= p1/2;
end;
//
delimiter ;
To populate table t1 with 200 million rows then delete half of them, the following command can then be issued:
mysql> call popudelt1(200000000);
Query OK, 100000000 rows affected (1 hour 29 min 39.17 sec)
Now let’s find the minimum value of docid in the table:
mysql> select min(docid) from t1;
+————+
| min(docid) |
+————+
| 100000001 |
+————+
1 row in set (26.13 sec)
Then find the maximum value:
mysql> select max(docid) from t1;
+————+
| max(docid) |
+————+
| 200000000 |
+————+
1 row in set (0.00 sec)
The interesting thing is that it took 26.13 seconds to find the minimum value but 0 seconds for the maximum value. In order to flush the messages down the tree and delete the rows in the leaf nodes, run the optimize command.
mysql> optimize table t1;
+——————+———-+———-+———-+
| Table | Op | Msg_type | Msg_text |
+——————+———-+———-+———-+
| optimizetests.t1 | optimize | status | OK |
+——————+———-+———-+———-+
1 row in set (1 min 40.36 sec)
Now reissue the select statement:
mysql> select min(docid) from t1;
+————+
| min(docid) |
+————+
| 100000001 |
+————+
1 row in set (0.01 sec)
Once the optimize operation was run, the select min command’s execution time was reduced to 0.01 seconds.
This is a simple example, in this scenario, a better approach would likely be to range partition the table by docid so the DBA can quickly drop the partition. Where tables frequently have multiple keys, a combination of partitioning and optimization may be a viable combination.




