

Please note, a more up-to-date follow-up post is here: Storing UUID and Generated Columns
A few years ago Peter Zaitsev, in a post titled ““There is timestamp based part in UUID which has similar properties to auto_increment and which could be used to have values generated at the same point in time physically local in BTREE index.”
For this post, I’ve rearranged the timestamp part of UUID (Universal Unique Identifier) and did some benchmarks.
Many people store UUID as char (36) and use as row identity value (PRIMARY KEY) because it is unique across every table, every database and every server and allow easy merging of records from different databases. But here comes the problem, using it as PRIMARY KEY causes the problems described below.
Despite the problems with UUID, people still prefer it because it is UNIQUE across every table, can be generated anywhere. In this blog, I will explain how to store UUID in an efficient way by re-arranging timestamp part of UUID.
MySQL uses UUID version 1 which is a 128-bit number represented by a utf8 string of five hexadecimal numbers
The timestamp is mapped as follows:
When the timestamp has the (60 bit) hexadecimal value: 1d8eebc58e0a7d7. The following parts of the UUID are set:: 58e0a7d7–eebc–11d8-9669-0800200c9a66. The 1 before the most significant digits (in 11d8) of the timestamp indicates the UUID version, for time-based UUIDs this is 1.
Fourth and Fifth parts would be mostly constant if it is generated from a single server. First three numbers are based on timestamp, so they will be monotonically increasing. Let’s rearrange the total sequence making the UUID closer to sequential. This makes the inserts and recent data lookup faster. Dashes (‘-‘) make no sense, so let’s remove them.
58e0a7d7-eebc-11d8-9669-0800200c9a66 => 11d8eebc58e0a7d796690800200c9a66
I created three tables
I created three stored procedures which insert 25K random rows at a time into the respective tables. There are three more stored procedures which call the random insert-stored procedures in a loop and also calculate the time taken to insert 25K rows and data and index size after each loop. Totally I have inserted 25M records.
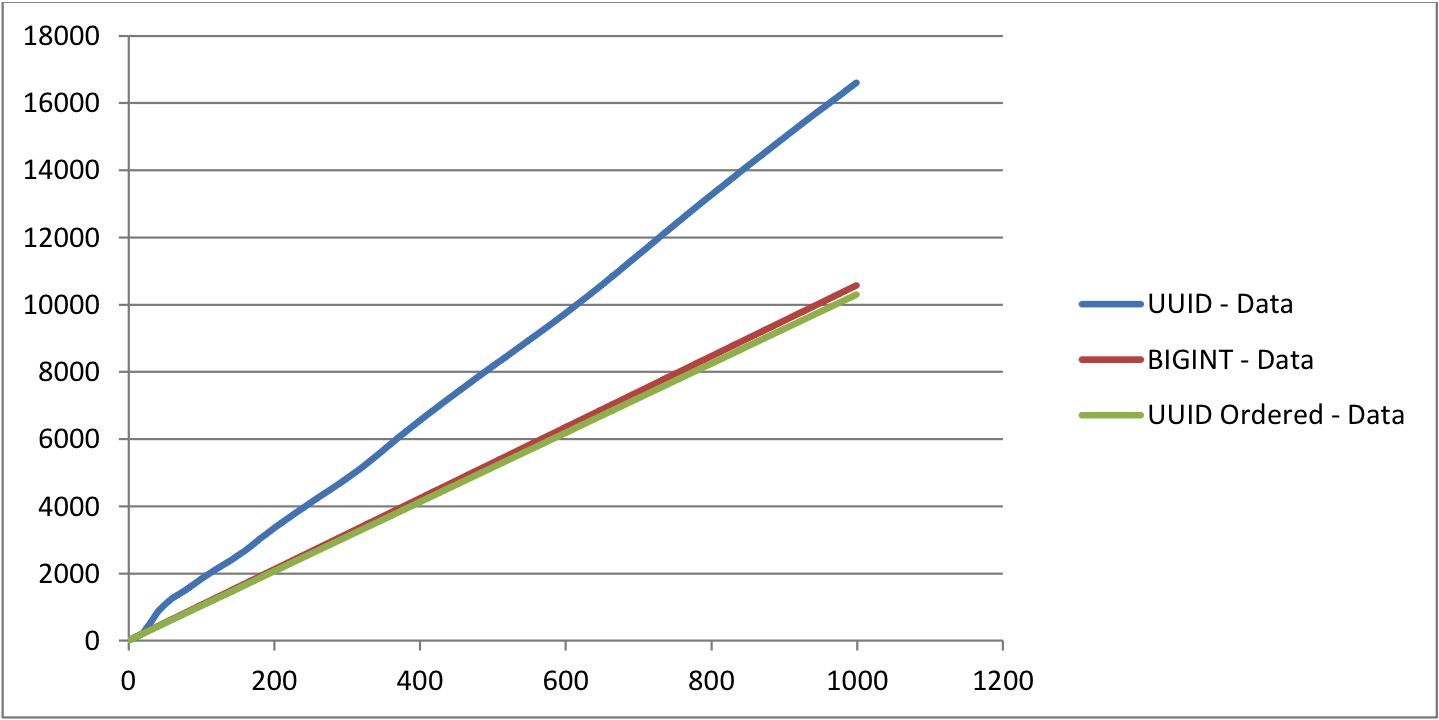
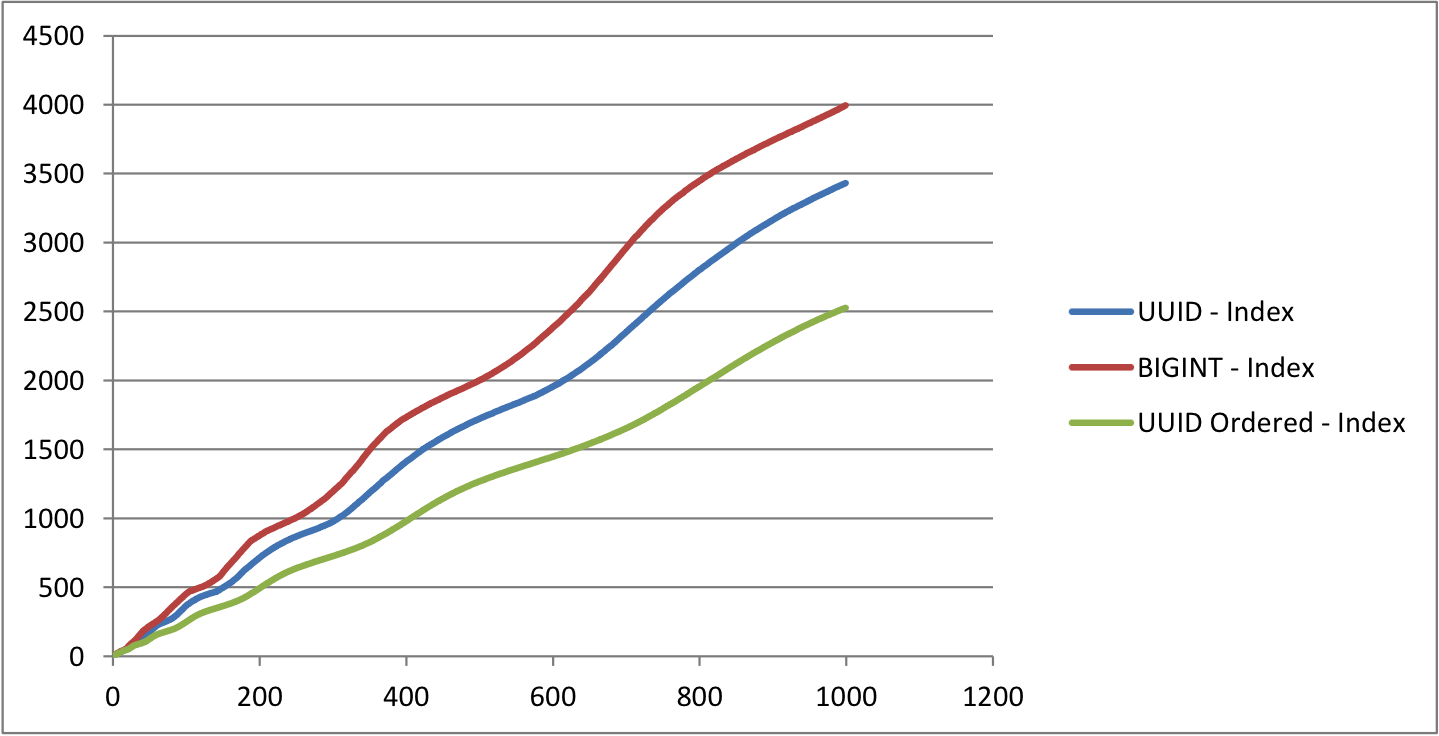
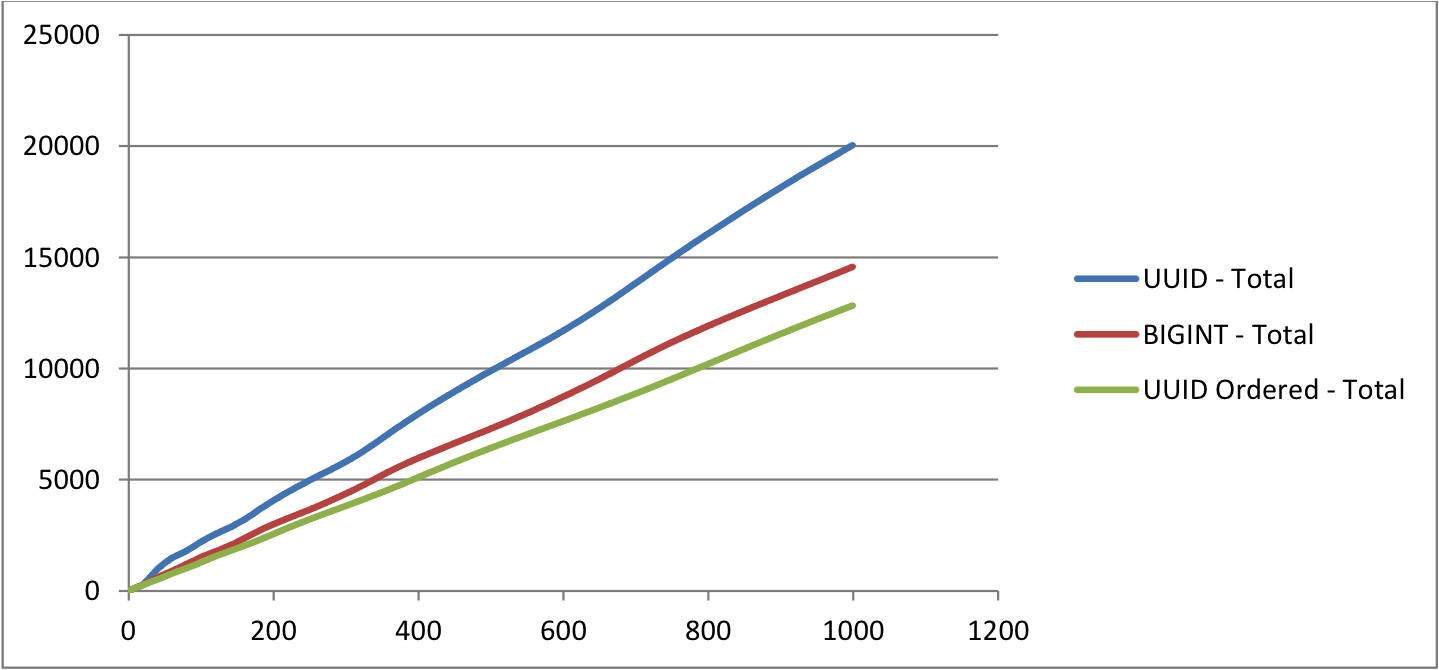
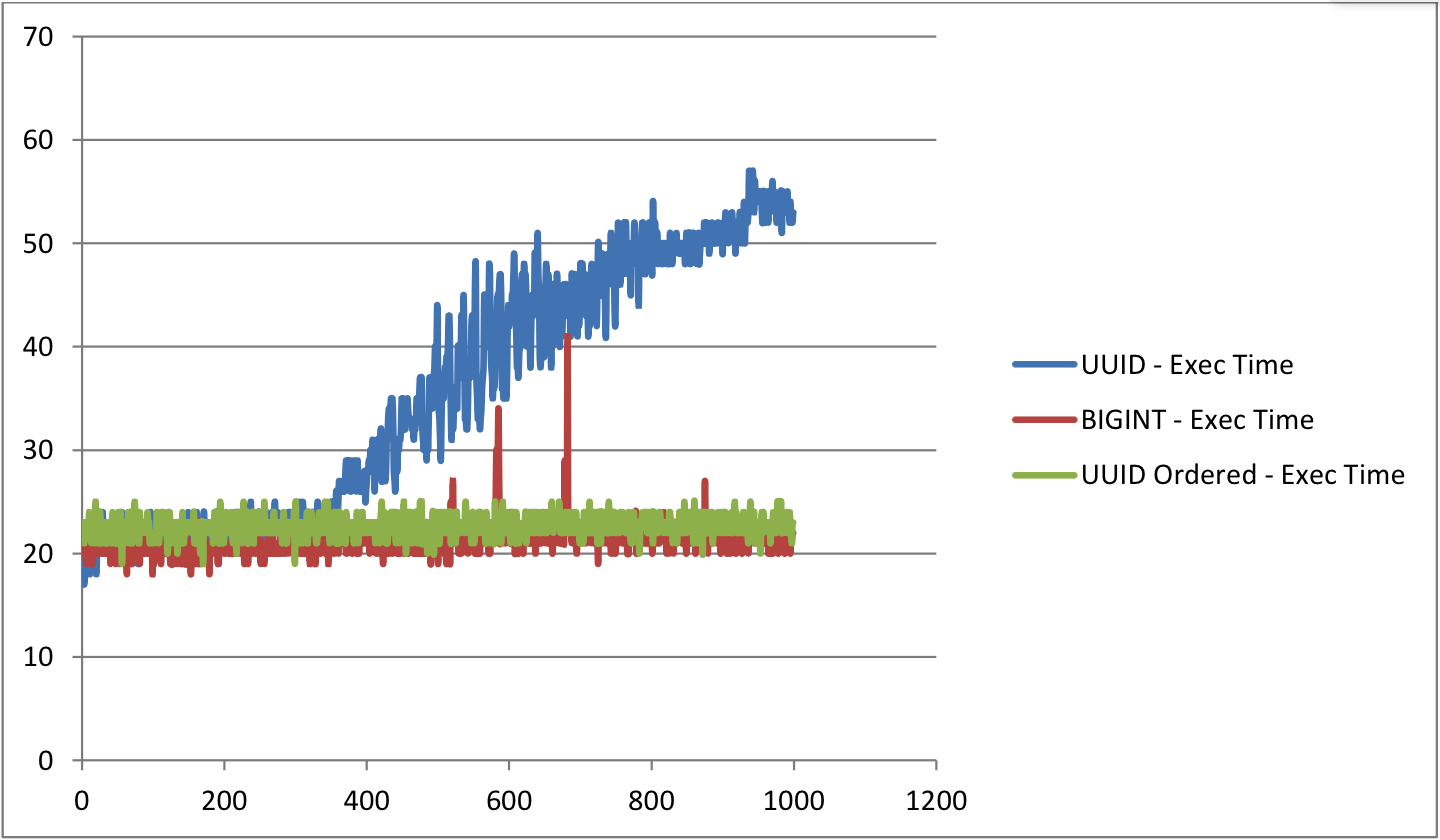
For the table with UUID as PRIMARY KEY, you can notice that as the table grows big, the time taken to insert rows is increasing almost linearly. Whereas for other tables, the time taken is almost constant.
The size of the UUID table is almost 50% bigger than Ordered UUID table and 30% bigger than the table with BIGINT as PRIMARY KEY. Comparing the Ordered UUID table BIGINT table, the time is taken to insert rows and the size are almost the same. But they may vary slightly based on the index structure.
|
1 2 3 4 |
root@localhost:~# ls -lhtr /media/data/test/ | grep ibd -rw-rw---- 1 mysql mysql 13G Jul 24 15:53 events_uuid_ordered.ibd -rw-rw---- 1 mysql mysql 20G Jul 25 02:27 events_uuid.ibd -rw-rw---- 1 mysql mysql 15G Jul 25 07:59 events_int.ibd |
Table Structure
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
#1 events_int CREATE TABLE `events_int` ( `count` bigint(20) NOT NULL AUTO_INCREMENT, `id` binary(16) NOT NULL, `unit_id` binary(16) DEFAULT NULL, `event` int(11) DEFAULT NULL, `ref_url` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `campaign_id` binary(16) COLLATE utf8_unicode_ci DEFAULT '', `unique_id` binary(16) COLLATE utf8_unicode_ci DEFAULT NULL, `user_agent` varchar(100) COLLATE utf8_unicode_ci DEFAULT NULL, `city` varchar(80) COLLATE utf8_unicode_ci DEFAULT NULL, `country` varchar(80) COLLATE utf8_unicode_ci DEFAULT NULL, `demand_partner_id` binary(16) DEFAULT NULL, `publisher_id` binary(16) DEFAULT NULL, `site_id` binary(16) DEFAULT NULL, `page_id` binary(16) DEFAULT NULL, `action_at` datetime DEFAULT NULL, `impression` smallint(6) DEFAULT NULL, `click` smallint(6) DEFAULT NULL, `sold_impression` smallint(6) DEFAULT NULL, `price` decimal(15,7) DEFAULT '0.0000000', `actioned_at` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', `unique_ads` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `notification_url` text COLLATE utf8_unicode_ci, PRIMARY KEY (`count`), KEY `id` (`id`), KEY `index_events_on_actioned_at` (`actioned_at`), KEY `index_events_unit_demand_partner` (`unit_id`,`demand_partner_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci; #2 events_uuid CREATE TABLE `events_uuid` ( `id` binary(16) NOT NULL, `unit_id` binary(16) DEFAULT NULL, ~ ~ PRIMARY KEY (`id`), KEY `index_events_on_actioned_at` (`actioned_at`), KEY `index_events_unit_demand_partner` (`unit_id`,`demand_partner_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci; #3 events_uuid_ordered CREATE TABLE `events_uuid_ordered` ( `id` binary(16) NOT NULL, `unit_id` binary(16) DEFAULT NULL, ~ ~ PRIMARY KEY (`id`), KEY `index_events_on_actioned_at` (`actioned_at`), KEY `index_events_unit_demand_partner` (`unit_id`,`demand_partner_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci; |
|
1 2 3 4 5 6 |
DELIMITER // CREATE DEFINER=`root`@`localhost` FUNCTION `ordered_uuid`(uuid BINARY(36)) RETURNS binary(16) DETERMINISTIC RETURN UNHEX(CONCAT(SUBSTR(uuid, 15, 4),SUBSTR(uuid, 10, 4),SUBSTR(uuid, 1, 8),SUBSTR(uuid, 20, 4),SUBSTR(uuid, 25))); // DELIMITER ; |
Inserts
|
1 |
INSERT INTO events_uuid_ordered VALUES (ordered_uuid(uuid()),'1','M',....); |
Selects
|
1 |
SELECT HEX(uuid),is_active,... FROM events_uuid_ordered ; |





Definitely an interesting method Karthik.
But, I think there’s a more efficient, performant and simple way of accomplishing the solution you’re trying to achieve. InnoDB tables, as you know use clustered indexes in the background, meaning the PRIMARY index is part of the actual row (even when no Primary Key is defined). It also supports a special column called ‘ai_col’ which when created as the first column in any table, set to an auto-incrementing unsigned integer, and flagged as the primary key will enable certain built in performance tweaks relating to the clustered index. All secondary indexes use the clustered index key (which is the important part)
The benefit of the clustered index is that it saves disk io because the complete page/row is returned rather than just the key which requires a second read operation on the specified page to retrieve the actual data.
In your solution the primary key would be a 16byte binary UUID, and all secondary indexes would be forced to use this meaning much larger index footprints, and I don’t know about you but most of our tables have multiple indexes. You’ve eliminated the IO overhead of inserting UUID’s and re-indexing, but you’ve increased the size of every index in the system as a side effect meaning both more physical and memory footprint.
By using the ‘ai_col’ first column and using it as the primary key, it solves both of those problems. You would then just create a second column with the true UUID’s, add a UNIQUE index on it. Your rows will have a slightly larger size, but your indexes will be MUCH smaller, resulting in less IO, and a smaller footprint overall.
You gain the benefits of an ordered insert key and thus low IO, you also gain the benefit of distributed UUID generation across all your app servers without any worry of collision in a cluster / multi-master environment, and you get to stick with standard UUID formatting which keeps things simple.
I completely agree on the hyphens though, useless 🙂
Kevin.
I’ve been using this version. Any comments on its rearranging compared to yours?
http://stackoverflow.com/a/7168916
UUIDs come from many sources. Many of them do not use “UUID version 1”, like MySQL.
Type 1 is recognizable by the “1” at the beginning of the third clump.
Do not jump to the conclusion that you can rearrange any UUID to benefit from temporal clustering.
Here is my blog on the topic:
http://mysql.rjweb.org/doc.php/uuid
@Kevin… Once the data, or index as you proposed, becomes too big to be cached, UUID lookups become I/O bound. Rearranging Type-1 UUIDs then becomes beneficial _if_ your accesses tend to be clustered in some time range, such as “recent events”.
The optimized/rearanged UUID could maybe be made even faster by using a UDF for it.
Also it seems like the mutex which is used for UUID (LOCK_uuid_generator) is not exposed with performance schema….
If you are worried about the index size of the UUID field you can always switch to using a BINARY field and use UNHEX() and HEX() to convert your UUID on its way into and out of the table. So a 16 byte UUID would only take 8 bytes in BINARY:
mysql> select HEX(UNHEX(‘1d8eebc58e0a7d7’));
+——————————-+
| HEX(UNHEX(‘1d8eebc58e0a7d7’)) |
+——————————-+
| 01D8EEBC58E0A7D7 |
+——————————-+
mysql> select LENGTH(UNHEX(‘1d8eebc58e0a7d7’));
+———————————-+
| LENGTH(UNHEX(‘1d8eebc58e0a7d7’)) |
+———————————-+
| 8 |
+———————————-+
Very interesting method !
However, do you know how different would be the results with TokuDB ?
Tokudb, with its “fractal” indexing strategy builds the indexes in stages. In contrast, InnoDB inserts index entries “immediately” — actually that indexing is buffered by most of the size of the buffer_pool. To elaborate…
When adding a record to an InnoDB table, here are (roughly) the steps performed to write the data (and PK) and secondary indexes to disk. (I leave out logging, provision for rollback, etc.) First the PRIMARY KEY and data:
* Check for UNIQUEness constraints
* Fetch the BTree block (normally 16KB) that should contain the row (based on the PRIMARY KEY).
* Insert the row (overflow typically occurs 1% of the time; this leads to a block split).
* Leave the page “dirty” in the buffer_pool, hoping that more rows are added before it is bumped out of cache (buffer_pool).. Note that for AUTO_INCREMENT and TIMESTAMP-based PKs, the “last” block in the data will be updated repeatedly before splitting; hence, this delayed write adds greatly to the efficiency. OTOH, a UUID will be very random; when the table is big enough, the block will almost always be flushed before a second insert occurs in that block. <– This is the inefficiency in UUIDs.
Now for any secondary keys:
* All the steps are the same, since an index is essentially a "table" except that the "data" is a copy of the PRIMARY KEY.
* UNIQUEness must be checked immediately — cannot delay the read.
* There are (I think) some other "delays" that avoid some I/O.
Tokudb, on the other hand, does something like
* Write data/index partially sorted records to disk before finding out exactly where it belongs.
* In the background, combine these partially digested blocks. Repeat as needed.
* Eventually move the info into the real table/indexes.
If you are familiar with how sort-merge works, consider the parallels to Tokudb. Each "sort" does some work of ordering things; each "merge" is quite efficient.
To summarize:
* In the extreme (data/index much larger than buffer_pool), InnoDB must read-modify-write one 16KB disk block for each UUID entry.
* Tokudb makes each I/O "count" by merging several UUIDs for each disk block. (Yeah, Toku rereads blocks, but it comes out ahead in the long run.)
* Tokudb excels when the table is really big, which implies high ingestion rate.
As for using a UDF instead of a Stored Function — CPU time is not the problem; it is I/O. Hence, the UDF won't help much.
Very clear!
Thanks Rick James
You can pre-generate these uuids in javascript using this library which was open sourced by my employer, Fisdap: https://github.com/fisdap/innodb-optimized-uuid
I implemented this uuid generation method for PHP and Doctrine users. Works great with Laravel too in case anyone is interested. https://github.com/mbbender/doctrine-ordered-uuid-generator
‘@François Schiettecatte — HEX(UNHEX()) is a noop other than leading zeros and case folding.
You can’t shrink a UUID to 8 bytes without losing information, and potentially causing “duplicate key”.
Is it possible to put the uuid() inside the function, instead of passing it as an argument?
Yes Joe, we can have uuid() inside the function.
I tested this procedure in a NodeJS Async Whilst loop and am immediately hitting duplicate IDs.
I cannot get past 100 inserts without this occurring with it sometimes occurring in as little as 2.
James, can you share a repo showing this?
Awesome write up!
If anyone needs a NodeJS / JavaScript class for creating and managing the binary(16) IDs rather than using the stored procedure checkout this repo:
https://github.com/gregl83/monotonic-id
very interesting article.
Do you know any performance difference in storing optimized UUID (11e5e1833a23ad4188733abca40787bc) hex to a decimal value (23790485847991417512368510810209093564)?
e.g.
3a23ad41-e183-11e5-8873-3abca40787bc => 11e5e1833a23ad4188733abca40787bc => 23790485847991417512368510810209093564
‘@psingh — I would expect the main difference to be a minor one… The field would need to be a different size. The bigger the data, the less cacheable it is, hence the more I/O, hence slower. There is essentially no difference if everything is cached; but it is a big difference in a table or index that is too big to be cached and indexed by UUID (hex or decimal). This difference is more noticeable in VARCHAR(36) vs BINARY(16), than for DECIMAL(40,0), which takes 18 bytes (barely more than 16). Storing the hex would be 32 bytes for CHAR(32) CHARSET ascii. (Or, big mistake, 96 for CHAR(32) CHARSET utf8.)
Great UUID perf improvement!
I was wondering if there is a shorter version of this optimized UUID.
MySQL has UUID_SHORT which is ordered but it is sequecial
http://dev.mysql.com/doc/refman/5.7/en/miscellaneous-functions.html#function_uuid-short
We could remove the Ethernet card number part UUID and use MySQL server number as UUID_SHORT does.
Would the restult save in DB still be binary(16) ?
Perhaps the main reason for UUIDs is to be able to generate unique numbers on multiple servers simultaneously. (I see little need to do so in a single server; there are other, safer, smaller, ways.) UUID_SHORT uses @@server_id, which is (potentially) unique only within a replication topology; UUID’s MAC or Ethernet address is aimed at unrelated computers (such as clients).
select unhex( replace( uuid(), ‘-‘, ” ) ) ;
Related: I put together a (slightly) more formalized version of a UUID (“Version 6”) which solves this same issue. https://bradleypeabody.github.io/uuidv6/ Could be useful in the cases described here.
Thanks, Brad. That was nicely explained. Now to figure out how to add it to the standard.
I do not get why data size is bigger in the events_uuid case than events_int. The differences in index size, total size, insert time, I get: but you’re storing 16 bytes/record for events_uuid vs 24 bytes for events_int. Seems like data size would be the same as events_uuid_ordered and less than events_int.
How COMB GUIDs compare to that?
In your example, what would the difference be between a BINARY and VARBINARY column in the table?
BINARY is better. The length is always 16, so there is no need for VARBINARY. VAR adds 1 or 2 bytes of length to the datatype.
I wonder a bit, why the fourth and fifth part of the original UUID are left untouched. Aren’t they pseudo-static, too? Why not move the changing parts over to the right? For example why not convert “AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEE” to “DDDDEEEEEEEEEEEECCCCBBBBAAAAAAAA”? If that’s bad for indexing again, maybe someone could explain.
Static for one server, but varies with server. That is the beauty of UUIDs — they can (in theory) be created by different servers not talking to each other, yet still be unique.
As to rearranging — That is what I do; see my Reply discussing “Type 1”. That is also what MySQL 8.0 has functions to do.
What about splitting the UUID across columns dedicated for each section ? Can’t be totally bad way.
I can imagine splitting each character into its own column would be pretty bad, though.
I have implemented this scheme. Running locally on an iMac on MySQL 5.6 and in a MySQL 5.7 QA environment, the code ran well. Today, when it was deployed to production, the code hammered the MySQL 5.6 server. In fact, it seems like an INSERT into a table with this binary UUID column crushed the machine. The code had to be rolled back because it was killing the client server and the DB server. I need some clues as to what might cause the DB server to suddenly get hammered trying to create UUIDs like this.
I am thinking this is responsible…
uuidvarbinary(16) DEFAULT NULL,…
UNIQUE KEY
index_fast_zids_on_uuid(uuid) USING BTREEYour schema above does not use BTREE… what does it default to?
Martin… You are sure they were Type 1? And rearranged? Did you look at HEX(uuid) to see that they were roughly ordered as they were inserted? And the uuid was the PRIMARY KEY?
Hi Martin,
Can you try removing the unique key constraint on uuid. That is a killer. If the application looks up based on uuid, you can create normal index and also change the column to binary from varbinary
uuid binary(16) DEFAULT NULL,
…
KEY index_fast_zids_on_uuid (uuid)
By default, the index is BTREE.
UNIQUE keys (including PRIMARY KEY) must be checked as you insert the row. Action on non-unique keys are delayed; search for “change buffer” for further discussion. Each row inserted must do a potentially cached read of a block of each UNIQUE key, but does not need such for non-unique keys. However, eventually the read-modify-write for each non-unique index block (that needs changing) will be done. That is, UNIQUE keys are sluggish at INSERT time; non-unique keys may be sluggish later.
The ultimate question is “will the next block be cached?” For a small index, it could be cached. Once the index is grows bigger than the buffer_pool, it becomes less and less likely to be cached, hence more reads. Reads are I/O; I/O is the biggest factor in performance.
My point is that it is more complicated than simply saying that “uniqueness is the killer”.
SPATIAL and FULLTEXT are the only indexes other than BTree in InnoDB; you must explicitly ask for them, else you get BTree.
Is it really worth playing with a fire called ID collision ? The VARBINARY to BINARY change is good, no problems there.
Seems You haven’t drawn any conclusions? Why do You compare table with 4 indexes to tables with 3 indexes?
I am producing the same value every time I try to create a uuid.
SELECT ordered_uuid(uuid());
is always returning :
ordered_uuid(uuid())
0x11e8dc2ddb202bef8d1d0800277ad90c
Mysql version is : 5.7.23-0ubuntu0.18.04.1
I have copy and pasted function ordered_uuid I am using here (which I think I copied correctly from this article) :
RETURN UNHEX(CONCAT(SUBSTR(uuid, 15, 4),SUBSTR(uuid, 10, 4),SUBSTR(uuid, 1, 8),SUBSTR(uuid, 20, 4),SUBSTR(uuid, 25)))
What am I missing please?
TIA.
Neil.
Thanks!! Added a simple JS lib for helping with this: https://github.com/odo-network/binary-uuid
Nice work
Thanks for this, I have a question: are you storing 1d8eebc58e0a7d7 as bytes (meaning you are cutting off the other half of the UUID) orrdo you rearang the hexdecimal value to store them as BINARY(16).
In MySQL version 8 (documentation here: https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html), function
ordered_uuidcan be replaced by the new built-in functionUUID_TO_BIN(UUID(), 1), where **1** is a flag to swap groups 1 and 3. To read stored primary key, we can use the functionBIN_TO_UUID(id, 1)