
Recently Oracle announced several new features for the latest available development version of MySQL that is 5.7.2 at the time of writing this article. Most of them are performance and replication related that show us how incredible the new release will be.
In this post I’m going to try to explain in some easy steps how the new multi-source replication works and how we can configure it for our own tests. It is important to mention that this is a development release, so it is not production ready. Therefore this post is intend to people that want to test the new feature and see how it works with their application, always in a staging environment.
First, we need to have clear that multi-master and multi-source replication are not the same. Multi-Master replication is the usual circular replication where you can write on any server and data gets replicated to all others.
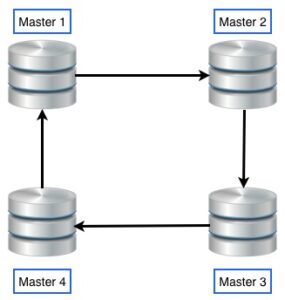
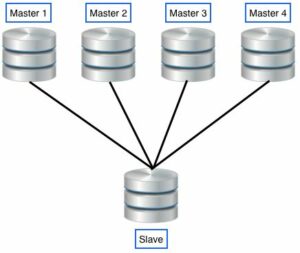
Now we have the concept of communication channels. Each communication channel is a connection from slave to master to get the binary log events. That means we will have one IO_THREAD for each communication channel. We will need to run different “CHANGE MASTER” commands, one for each master, with the “FOR CHANNEL” argument that we will use to give a name to that channel.
|
1 |
CHANGE MASTER MASTER_HOST='something', MASTER_USER=... FOR CHANNEL="name_of_channel"; |
Pretty easy. There is one single pre-requisite. The slave should have been configured first with the crash-safe feature of MySQL 5.6. That means that info usually included in master.info or relay-log.info should be on a table. Let’s start with the configuration.
First you need to download the lab version of mysql from this link.
We have a sandbox environment with 2 masters and 1 slave servers. I won’t go over the details of how to configure the server_id, binary logs or replication users. I assume they are well configured. If you need a howto, you can follow this one.
First, we have to enable the crash safe feature on the slave:
|
1 2 |
master_info_repository=TABLE; relay_log_info_repository=TABLE; |
After a restart of the slave we can start creating the channels with the names “master1” and “master2”:
|
1 2 |
slave > change master to master_host="127.0.0.1", master_port=12047, master_user="msandbox",master_password="msandbox" for channel="master1"; slave > change master to master_host="127.0.0.1", master_port=12048, master_user="msandbox",master_password="msandbox" for channel="master2"; |
To start the slave processes you need to specify what channel are you referring to:
|
1 2 |
slave > start slave for channel="master1"; slave > start slave for channel="master2"; |
Now, we want to check the status of the slave:
|
1 2 |
slave > show slave statusG Empty set (0.00 sec) |
Oh, it is empty. We have to specify again which channel we want to check:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
slave > SHOW SLAVE STATUS FOR CHANNEL="master1"G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 127.0.0.1 Master_User: msandbox Master_Port: 12047 Connect_Retry: 60 Master_Log_File: mysql-bin.000002 Read_Master_Log_Pos: 232 Relay_Log_File: squeeze-relay-bin-master1.000003 Relay_Log_Pos: 395 Relay_Master_Log_File: mysql-bin.000002 Slave_IO_Running: Yes Slave_SQL_Running: Yes [...] |
and we can also check that the IO_THREAD and SQL_THREADS are running:
|
1 2 3 4 5 6 7 8 9 |
slave > SHOW PROCESSLIST; +----+-------------+-----------------------------------------------------------------------------+ | Id | User | State | +----+-------------+-----------------------------------------------------------------------------+ | 2 | system user | Waiting for master to send event | | 3 | system user | Slave has read all relay log; waiting for the slave I/O thread to update it | | 4 | system user | Waiting for master to send event | | 5 | system user | Slave has read all relay log; waiting for the slave I/O thread to update it | +----+-------------+-----------------------------------------------------------------------------+ |
Let’s test it:
|
1 2 3 4 5 6 7 8 9 |
master1 > create database master1; master2 > create database master2; slave > show databases like 'master%'; +--------------------+ | Database (master%) | +--------------------+ | master1 | | master2 | +--------------------+ |
It works, that easy!
The new multi-source feature allow us to create new replication environments that were impossible in the past without some complex “hacks”. Of course, your application should be designed and developed with this new architecture in mind. Like with multi-master, multi-source needs special care to not end up with your data messed up.
MySQL replication is getting better on every release giving us more configuration, performance and design possibilities. And all those new features can be combined. Your replication environment can be even better if you mix some of the new (and old) features added recently to the replication. For example, you can configure GTID or enable multi-threaded slave per schema.





Great feature! It looks helpful for when you want to funnel sharded data into a single location so you can run OLAP type operations over all the data.
Very nice feature. Keeping eye on 5.7…
Hi Miguel,
You can use the new replication performance schema tables to look at all the channels or choose which channel you want…
shiv, yes, it is possible to get that info from P_S tables:
replication_connection_configuration
replication_execute_configuration
but… in my personal opinion that should be in I_S. That info is not performance related, it just show us configuration information so it should be available via SHOW (for example SHOW SLAVE STATUS CHANNEL ALL) or via I_S tables. Maybe I’m wrong, but I’ve opened a feature request anyway:
http://bugs.mysql.com/bug.php?id=70434
I trying to imagine the practical implementation of this new ‘multi source replication’ and how does it really help having a slave getting replicated from multiple sources when the data_set_from_every_master is the same ?
Consider the M-M replication master1 and master2 having the dataset X and I could easily run a slave1 either from Master1 or Master2 and possibly have many other slaves from slave1 or master[1-2] and so on, why would one need to replicate from multiple masters if data is all the same unless for some arcane reason i want to replicate a particular db from master 1 and another db2 from another master which is not necessarily in the M-M replication chain .
Tariq, the data from masters don’t need to be the same. The masters on the second graph they are not in M-M replication. There are lot of examples where multi-source can be applied:
– maybe you have hundred of apache servers, logging accesses to a mysql. in that case, having all those mysql replicating to a single slave could help you to run queries there.
– or you have radar-controlled speed cameras all around the country and you need to have one single point to query the data.
– or just the example made by Marc on the first comment.
So, masters don’t need to have the same data set. Now practical implementation depends on what you need not on MySQL limitations.
I will definitely test and blog this setup. Will make downtime-less migrations easier, without any doubt.
Nice Nice.
This will drastically reduce the complexity on our OLAP servers.
Does this works nice if the salve uses BlackHole Engine for all the replicated databases?
Hugo, this still works like regular replication, just with more IO and SQL threads. No limitation on what storage engine you use.
Hi Miguel,
For the multi-source replication, I would like to know if it is sufficient to upgrade the slave to 5.7.2, or do the masters also need to run the same mysql version?
Terence, didn’t have time to check it. But the theory says “it should”. It just opens more “io threads”, so for the master server is like having two different slaves. But as I said, didn’t check it. If I get some spare time I will try it.
Hi Miguel,
Thanks for your reply. I just got multi-source replication working with MySQL 5.7.2 on my laptop with 2 vms running 5..
I got multi-source replication running with 2 VMs with different MySQL versions (5.1.49 and 5.1.63). Thanks.
Hi all,
I’ve just slave it in m-m with two percona’s 5.6 and it works as expected. Everything is replicated everywhere. I noticed. after 5.7.2 is restarted the replications on it can’t be started again and have to be setup again.
is percona plans to add feathure Parallel Slave like MariaDB? thanks
During my (still labs-version 5.7.2) testing of multi source replication, it seems there is a bug where replication does not automatically pick back up after a server restart.
Information remains in the slave_master_info table, how ever attempt to start slave for channel or show slave status for channel returns an error as if it had never been setup.
Rerunning a full change master to command from the log positions left in slave_master_info table seemed to allow replication to resume.
Aside from that one gotcha I ran into was trying to replicate a table with the now-reserved word “channel” for a column name. The application wasn’t encasing the column names in backticks to replication would break on a syntax error for those inserts.
Further testing off a real replication stream broke with an error about not being able to parse log events. This was trying to read binlogs from a percona 5.5.34 build. Between mixing percona builds with mysql labs builds and a big “TESTING ONLY” warning on the download I’ll wait for it to become more stable before pursuing further.
Mike, thanks for your comments. That is what Oracle wants with Lab version, to have people breaking it like you are doing. It would be good if you could report those bugs on http://bugs.mysql.com/ That will help to make the final release even better 🙂
I am trying to do some testing but I keep getting syntax errors when trying to do CHANGE MASTER TO …. FOR CHANNEL = ‘channel_name’. Any ideas. Using 5.7.3, tried in Workbench and on command line – same result.
I’m wondering how mysql does 5.7 handle auto_increment feature. What if i have two master without any communication and both of them has auto increment row, they can easily get same ids. Should i also use auto_increment_increment and auto_increment_offset parameters like master-master structure?.
‘@wayne, you have to download the laps specific version from http://labs.mysql.com/ Select multi source replication from the drop down.
*labs; I wish I could edit comments here
‘@s capkan, I believe the point of multi source replication is to get the databases from server A and server B into the same instance on the slave C instance. If both A and B hold the same database/table schemas I imagine you’re going to have a bad time.
The auto_increment_offest is meant for multi master replication so they don’t step on each other since mysql replication is not synchronous.
We have many MySQL instances that are set up with the same set of databases for each instance. I was planning to use multi-source to create a single backup point and reporting point. The problem is that all the source instances have the same databases. Are there any considerations for a prefix on the database name, or something that creates a unique database name on the replica in such a scenario?
I have the same concern as the post above me, Alex. If Master1 and Master2 both have a schema called “test”, how does this conflict with multi-source replication? I would imagine there would be 2 problems, the first one being can’t have 2 schemas with the same name. Second, how does the slave know which schema to apply the slave event?
have you checked if mysql 5.7.4 support this feature? when i issue this statement “change master to master_host=”127.0.0.1″, master_port=12047, master_user=”msandbox”,master_password=”msandbox” for channel=”master1″; , mysql reports an syntax error near ‘ for channel’. i havent found any document for ‘for channel’ clause. could you please give me some help ? thanks .
‘@alex: It is not in the release builds yet, you have to download the multi-source replication version from http://labs.mysql.com/
Hello,
Could you help me with the installation of MySQL 5.7.2, because I am unable to install on my Slave
Hi Lilian,
I suggest asking this on our MySQL discussion forums: https://www.percona.com/forums/
Hi All,
Does this gives HA facilit. For e.g., If we assume M1,M2,M3 are three multisource masters and S1 is the Slave server.if one among the Master server fails. Let us say M2 failed. Can we failover to Slave S1 and is it possible to continuously write to new Master?
Any real time example or Use case for this to get a clear idea ?
Best Regards,
Kiran.M.K.
Did you get an answer for this?
Is the GTID mandatory in Multi source Replication ?
Best Regards,
Kiran.M.K.
Is this a reasonable solution for a fallback/backup server for disparate master instances? We have two different instances running completely unrelated data in unique DBs. I’m looking to put together a single fallback source for maintenance/failures and I’m still not perfectly sure this is a good option, though it’s really attractive. should I just go with 1:1 instances instead?
It has been more than a year since the original announcement, and multi-source replication is still available only in the lab version not intended for production use. Is there any way to find out if and when this feature will be available in a production release of MySQL?
can you show me step by step create 2 master for one slave ?
server A = Master
server B = Master
Server C = slave
cen you help me ?
contact me i will teach
[email protected]
How does this multi-source replication configuration works, if all masters (masters only) are in circular replication setup and slave try to pull data from all masters?
Hi,
In mysql 5.7 multiple source replication, do masters also need to run on same mysql version?
For clarification. I have 3 master having mysql version 5.6 and slave with 5.7 will multiple master and single slave replication will work?
did you find out about this? I have the same setup.
Hi,
I’m building a multi-source replication on mysql 5.7.7-rc. The scenario in my side is there are multiple mysql instances, all of them has the same table structure, but with different data, all I need to do is to merge all the data into 1 replica mysql instance.
Therefore I planned to add 1 column in replica database tables named master-name, next step is to write a “before update/insert” trigger to update the replica table when every time insert/update come. BUT, I found it’s not easy to identify the source of the insert/update.
Some findings from my side:
1. I can find replication channel information from table “performance_schema.replication_connection_configuration”.
2. Also there is process information on information_schema.PROCESSLIST.
Which mysql master instance does the insert/update comes from?
Thanks in advance!
‘@Dirham follow https://www.digitalocean.com/community/tutorials/how-to-set-up-master-slave-replication-in-mysql and http://dev.mysql.com/doc/refman/5.7/en/replication-multi-source-tutorials.html helped me a lot
actually, just add “FOR CHANNEL ‘master-XX’ for each Master on slave and it will work!
it this feature still only in the labs version? I’ve installed 5.7.7-rc and get syntax error
Before setting up a test environment, figured I’d ask before wasting the time. Anyone know if having a mysql master running 5.6 and having slaves at version 5.7 would work? Or would we need to upgrade the masters to 5.7 also?
Guess I can answer my own question. Yes it works using 5.6 master and 5.7 slaves making use of the CHANNELs
Marc? As in SOLN, Marc Castrovinci?
Hi Guys,
Have tried MySQL5.7.10, syntax changed little bit.
It’s works for me.
>change master to master_host=”172.16.60.8″,master_port=3306, master_log_file = ‘bin.000011’, master_log_pos= 403, master_user=”replicator”, master_password=”pass” for channel “master1”;
nice article.. I am using Xampp and I successfully replicated only for one master and one slave…I want to replicate multiple master and one slave..can you explain how to do this in Xampp?.Thanks
I don’t know if this changed from the time this article was written or what but with Percona-Server-server-57-5.7.11-4.1.el6.x86_64 it is not:
… for channel=’master1′;
It is:
… for channel ‘master1’;
See the MySQL docs: https://dev.mysql.com/doc/refman/5.7/en/change-master-to.html
But even the MySQL docs omit the quotes around the channel name.
Hope this helps someone.
how to skip one transaction in one channel ?
# stop all slaves
stop slave;
# set skip counter
set global sql_slave_skip_counter=1;
# start slave that shall skip one entry
start slave for channel “$channel”;
# start all other slaves
start slave;
Hello Miguel,
I am not sure whether multi source replication in Percona server v5.7.13 supports replicate-rewrite-db option for multiple channels. Similarly as explained here – https://mariadb.com/blog/multisource-replication-how-resolve-schema-name-conflicts
Can you please share your thoughts on this. Any blog which can give more insights on this would be helpful.
Fix or delete the link at the end of the article.
intra-databaseit links to malware.Nick, thanks for your comment. We have deleted the link.