
In the first part of this article I have showed how I align IO, now I want to share results of the benchmark that I have been running to see how much benefit can we get from a proper IO alignment on a 4-disk RAID1+0 with 64k stripe element. I haven’t been running any benchmarks in a while so be careful with my results and forgiving to my mistakes ![]()
Here is the summary of the system I have been running this on (for brevity I have removed some irrelevant information):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# Aspersa System Summary Report ############################## Platform | Linux Release | Ubuntu 10.04.2 LTS (lucid) Kernel | 2.6.32-31-server Architecture | CPU = 64-bit, OS = 64-bit # Processor ################################################## Processors | physical = 2, cores = 12, virtual = 24, hyperthreading = yes Speeds | 24x1600.000 Models | 24xIntel(R) Xeon(R) CPU X5650 @ 2.67GHz Caches | 24x12288 KB # Memory ##################################################### Total | 23.59G ... Locator Size Speed Form Factor Type Type Detail ========= ======== ================= ============= ============= =========== DIMM_A1 4096 MB 1333 MHz (0.8 ns) DIMM {OUT OF SPEC} Other ... # Disk Schedulers And Queue Size ############################# sda | [deadline] 128 # RAID Controller ############################################ Controller | LSI Logic MegaRAID SAS Model | MegaRAID SAS 8704EM2, PCIE interface, 8 ports Cache | 128MB Memory, BBU Present BBU | 100% Charged, Temperature 34C, isSOHGood= VirtualDev Size RAID Level Disks SpnDpth Stripe Status Cache ========== ========= ========== ===== ======= ====== ======= ========= 0(no name) 1.088 TB 1 (1-0-0) 2 2-2 64 Optimal WT, RA PhysiclDev Type State Errors Vendor Model Size ========== ==== ======= ====== ======= ============ =========== Hard Disk SAS Online 0/0/0 SEAGATE ST3600057SS 558.911 Hard Disk SAS Online 0/0/0 SEAGATE ST3600057SS 558.911 Hard Disk SAS Online 0/0/0 SEAGATE ST3600057SS 558.911 Hard Disk SAS Online 0/0/0 SEAGATE ST3600057SS 558.911 |
It says controller cache is set to write-through (WT), though in fact for every benchmark I have repeated it with (a) write-through and (b) write-back to see if write-back cache would minimize the effects of misalignment.
File system of choice was XFS. Barriers and physical disk cache was disabled. The tool I used was sysbench 0.4.10 that came with this Ubuntu system. I have run every fileio benchmark and an IO bound read-write oltp benchmark in autocommit mode.
For the FileIO benchmark, I used 64 files – 1GB, 4GB and 16GB total in size with 1, 4 and 8 threads. The operations were done in 16kB units to mimic InnoDB pages. There were couple interesting surprised I faced:
1. After I got (what I thought was) the best configuration, I added LVM on top of that and the performance improved another 20-40%. It took me a while to figure it out, but here’s what happened – for XFS file system on a raw partition I was using full partition size which was slightly over 1TB in size. When I added LVM on top however, I made the logical volume slightly below 1TB. Investigating this I found that 32-bit xfs inodes (which are used by default) have to live in the first terabyte of the device which seems to have affected the performance here (IMO that’s because of where first data extents were placed in this case). When I have mounted the partition with inode64 option however, the effect disappeared and performance without LVM was slightly better than with LVM as expected. I had to redo all of the benchmarks to get the numbers right.
2. I was running vmstat during one of the tests and my eye caught the spike in OS buffers during “prepare” phase of sysbench. I found out that sysbench would not honor –file-extra-flags during “prepare” phase and instead of having files created using direct IO they were buffered in OS cache and so writes to files were serialized until they were fully overwritten and that way flushed from OS buffers. Buffers would be flushed within first few seconds so the effects of this were marginal. Alexey Kopytov fixed this in the sysbench trunk immediately, though I didn’t want to recompile sysbench on this system so I’ve used Domas’ uncache after prepare to make sure caches were clean.
As the goal was to compare performance with different IO alignment, not different MySQL configurations, I didn’t try out different MySQL versions or settings. Moreover, I have been running these benchmarks for a customer so I just used the setting that they would have used anyway. One thing I did change was – I have significantly reduced InnoDB buffer pool to make sure the benchmark is IO bound.
That said, benchmark was running on a Percona Server 5.0.92-87 with the following my.cnf configuration:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
[mysqld] datadir=/data/mysql socket=/var/run/mysqld/mysqld.sock innodb_file_per_table = true innodb_data_file_path = ibdata1:10M:autoextend innodb_flush_log_at_trx_commit = 2 innodb_flush_method = O_DIRECT innodb_log_buffer_size = 8M innodb_buffer_pool_size = 128M innodb_log_file_size = 64M innodb_log_files_in_group = 2 innodb_read_io_threads = 8 innodb_write_io_threads = 8 innodb_io_capacity = 200 port = 3306 back_log = 50 max_connections = 2500 max_connect_errors = 10 table_cache = 2048 max_allowed_packet = 16M binlog_cache_size = 16M max_heap_table_size = 64M thread_cache_size = 32 query_cache_size = 0 tmp_table_size = 64M key_buffer_size = 8M bulk_insert_buffer_size = 8M myisam_sort_buffer_size = 8M myisam_max_sort_file_size = 10G myisam_repair_threads = 1 myisam_recover skip-grant-tables |
Amount of rows used was 20M, transactions were not used (autocommit), number of threads – 1, 4, 8, 16 and 32.
Here’s the different settings that I have ran the same benchmark on. As I mentioned earlier, each of those were run twice – first with RAID controller cache set to Write-Through and then to Write-Back.
1. Baseline – misalignment on the partition table, no LVM and no alignment settings in the file system. This is what you would often get on RHEL5, Ubuntu 8.04 or similar “older” systems if you wouldn’t do anything with respect to IO alignment.
2. Misalignment on the partition table, but proper alignment options on the file system. This is what we get when file system tries to balance writes but is not aware that it is not aligned to the beginning of the stripe element.
3. 1M alignment in partition table but no options on the file system. You should get this on RHEL6, Ubuntu 10.04 and similar systems if you wouldn’t do anything with respect to IO alignment yourself. In this case offset is correct, but file system is unaware how to align files properly.
4. Partition table and file system properly aligned; sunit/swidth set during mkfs. No LVM at this point.
5. Partition table aligned properly; sunit/swidth set during mounting but not during mkfs. This is your best option if you have a proper alignment in partition table but you did not set alignment options in xfs when creating it and you don’t want or can’t format the file system. One thing to note however – files that were written before this was set may still be unaligned, though xfs defragmentation may be able to fix that (not verified).
6. Added LVM on top of aligned partition table, used proper file system alignment.
I had a hard time thinking how it would be best to present results so it’s not too stuffed and actually interesting. I decided that instead of preparing charts for each benchmark, I’ll just describe few less interesting numbers first, then I’ll show graphs for more interesting results. Let me know if you thought this was a bad idea ![]()
Sequential read results are expectedly the least interesting. Read-ahead kicked in immediately giving ~9’600 iops (~150MB/s) at 1 thread, 14500 iops (~230MB/s) at 4 threads and ~16300 iops (~250MB/s) at 8 threads. Neither IO alignment nor file size made any difference. Adding LVM here reduced single-thread performance by 5-10%.
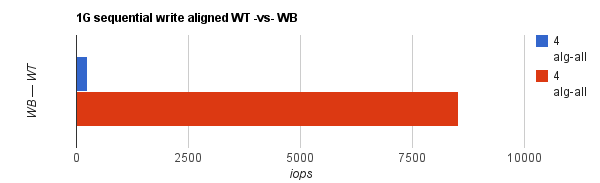
Sequential write results were a bit more interesting. With WT (write-through) cache enabled, performance was really poor whatsoever and there was virtually no difference whether it was 1 thread, 4 or 8 threads. Different file sizes made no difference too. Write-back cache gave an incredible performance boost – up to 33x in single-threaded workload. File system IO alignment seems to have made a difference – up to 15% with write-back cache enabled. Here’s 1GB seqwr with WT cache:
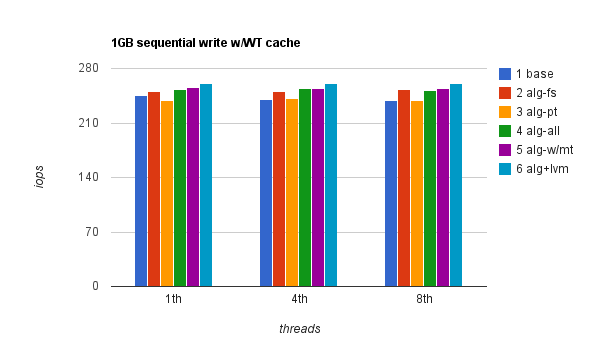
Here’s same test with WB cache:
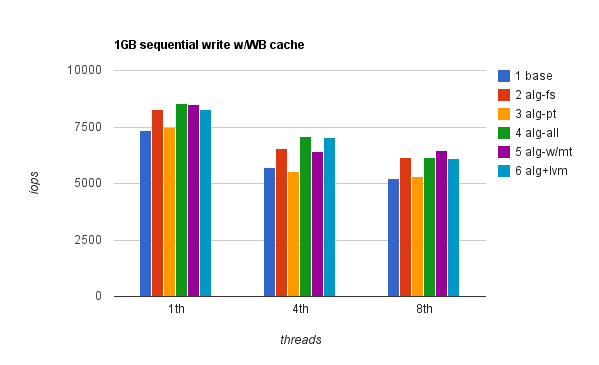
And just to show you the difference between sequential writes with WT cache and WB cache:
Random read. This is probably the most interesting number for OLTP workload which is usually light on writes (especially if there’s a BBU protected Write-Back cache) and heavy on random reads. Regardless of the file size, the difference between aligned and misaligned reads was the same and, WT -vs- WB cache of course showed no difference at all. Here are the results:
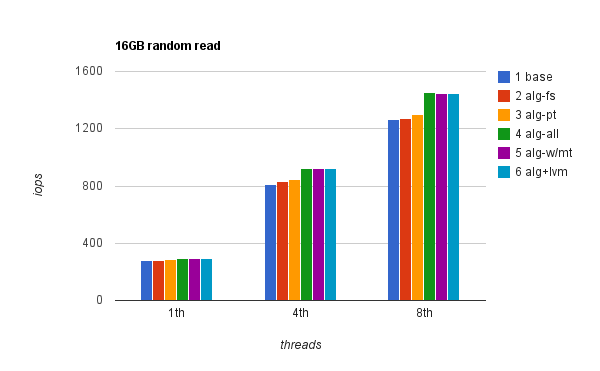
As you can see IO alignment makes a difference here and improves performance up to 15% in case of 8 threads running concurrently. Because the customer was running a database which was way bigger than 16G, I’ve repeated the random read (and write) benchmark with 8 threads and total size of 256G. While the number of operations per second was slightly lower, the difference was still 15% — 909 iops unaligned -vs- 1049 aligned.
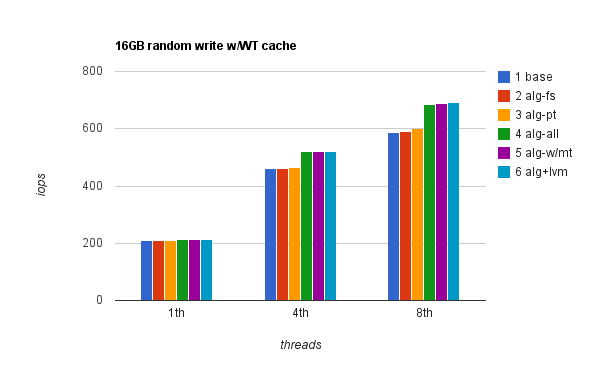
Random write. This is an important metric for write intensive workloads where there’s a lot of data being modified, inserts are done to random positions (not consecutive PK causing page splits) etc. Benchmark results are fairly consistent regardless of file size, let’s look at them. First, results with WT cache:
And here’s with WB cache:
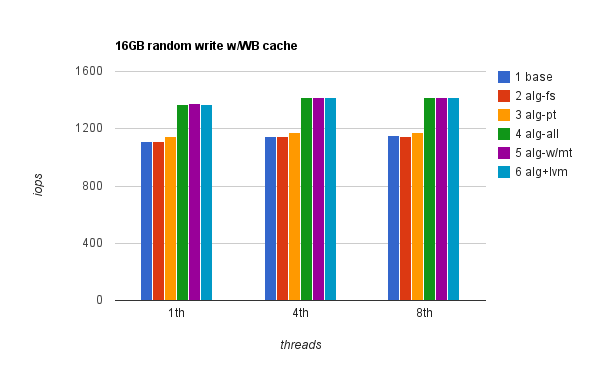
Apparently proper IO alignment in this case gives up to 23% improvement when WB cache is used. With WT cache enabled, single thread performance improvement is marginal however WB cache brings single thread random write performance close to what 8 threads can do, and IO alignment gives extra 23% in this case.
I mentioned I did single test on a larger files (same test I did for random reads) i.e. 8 thread random write benchmark on files totaling to 256GB. With WB cache enabled, I got 919 iops unaligned and 1127 iops aligned i.e. the improvement is still 23%.
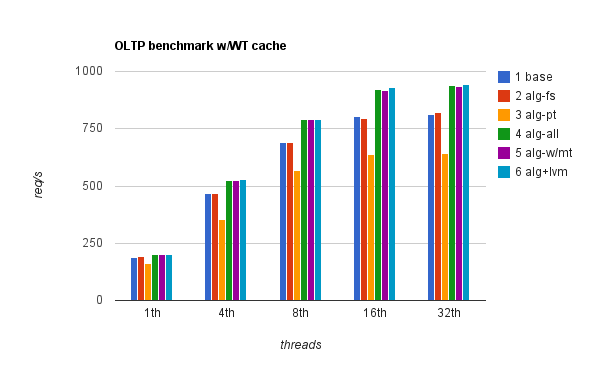
From this benchmark, I only have two graphs to show you. First one is with RAID controller set to WT cache:
The second is with WB cache:
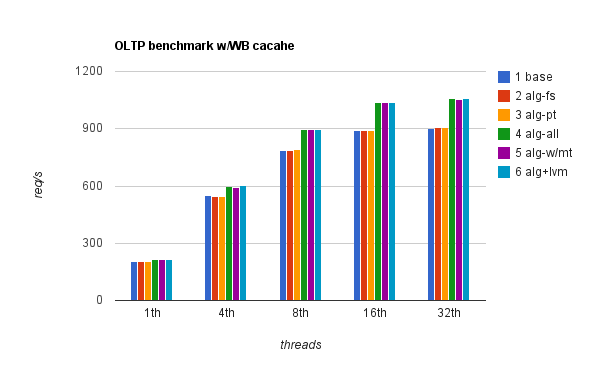
I couldn’t figure out what exactly happened with setting #3 when WB cache was disabled, what I do know though is that, based on IO stats I was gathering during the benchmarks, the reason was in fact lower number of IO operations and higher response time – so it seems in this case misaligned IO had some collateral effects in a mixed read/write environment. Note that the benchmarks were all scripted and oltp benchmarks would automatically start after file tests so if there was an error in the setting, it would have reflected across all other benchmarks for the same setting.
For the two workloads that are most relevant to databases – random reads and random writes – IO alignment on a 4-disk RAID10 with standard 64k stripe element size makes a significant difference. When I launched the system that I was benchmarking, I could clearly see the difference in production as I had another machine running sideways with the same hardware, but with a misaligned IO. Here’s diskstats from the two shards running side by side:
|
1 2 3 4 5 6 7 |
Aligned: #ts device rd_s rd_avkb rd_mb_s rd_mrg rd_cnc rd_rt wr_s wr_avkb wr_mb_s wr_mrg wr_cnc wr_rt busy in_prg {540} dm-0 447.1 34.0 7.4 0% 2.4 5.4 23.4 49.6 0.6 0% 0.0 0.6 85% 0 Misaligned: #ts device rd_s rd_avkb rd_mb_s rd_mrg rd_cnc rd_rt wr_s wr_avkb wr_mb_s wr_mrg wr_cnc wr_rt busy in_prg {925} dm-0 462.1 34.1 7.7 0% 3.8 8.2 12.1 87.0 0.5 0% 0.0 0.7 93% 0 |
While number of operations from the OS perspective is very similar, due to high concurrency response time in the first case is significantly better.
It would be interesting however to run similar benchmarks on a larger RAID5 system where it should make even bigger difference on writes. Another interesting setting might be a [mirrored] RAID0 with many more stripes as not having proper file system alignment should have really interesting effects. Large stripe on the other hand should somewhat reduce the effects of misalignment, though it would definitely be interesting to run benchmarks and verify that. If you have some numbers to share, please leave a comment. Next, I plan to look at IO alignment on Flash cards to see what benefits we can get there from proper alignment.
You can find scripts and plain data here on our public wiki.





Siddhartha, one of the reasons for external fragmentation (file system fragmentation, which you can check with filefrag on ext2/3(/4)? or xfs_db on xfs) could be partition that has little free and/or reserved disk space available. It is also a good question whether your file system is extents based (xfs) or not (ext2/3(/4)?) — you should get a lot more fragmentation with non-extents based file systems if you write to many tables (or externally writing other files in the same partition).
As for internal fragmentation, if you are modifying variable length data and/or there’s a decent rate of deletes and inserts, fragmentation is bound to occur regardless of the column type as long as table format is dynamic (which will happen with any variable length columns) – some updates that will fit in an old position will be done in place, others will be written to new areas leaving space in the old ones, deletes will leave gaps which may not be filled in if they are too small etc.
Let me put the question this way. Is there more fragmentation in myisam engine if you include BLOB in the same table. I saw this on the mysql web site. But when I moved this column to different table. Even then the fragmentation is not getting reduced. Optimize table reduces the fragmentation. But I am looking for actual cause.
Appreciate your response.
Cheers
Siddhartha,
fragmentation is a completely different topic and it’s not very clear what external RAID do you have, what local RAID you can have, what is the RAID configuration and so on, so without all the unknowns your question can be answered correctly only with a good amount of luck You can find quite a few articles about fragmentation on our blog.
You can find quite a few articles about fragmentation on our blog.
Hi,
Great article. I am having an issue of fragmentation of MySQL 5.1.3x with RAID for data file.
There is huge fragmentation and therefore, after some time the performance degrades.
What do you think should I do to increase the performance ?
Does it matter to change from RAID to local disk for 2-3 million of records of approx 1kb record ?
definitely powerful and have regularly helped typical men and women like me to attain their targets. This useful essential points can mean significantly to me and somewhat much more to my business office colleagues. Ideal wishes; from all people of us.
Aurimas,
all pictures have gone 🙁
Should be good now.
the Wiki link (raid10-4disk) provided in the article doesn’t work. Thanks for this tho
Thanks, Timy. The content was restored now. Raw data still looks weird as the table formatting doesn’t have any indentation, I’ll work with our webmaster to get this resolved.
Very awesome to see some figures on this and get a better idea of how much it has an effect. What I would love to see is more of a interpolation on understanding the gravity of how this would affect regular office users.