
The title is SEO bait – you can’t do it. We’ve seen a few recurring patterns trying to achieve similar – and I thought I would share with you my favorite two:
Option #1: Use a table to insert into, and grab the insert_id:
|
1 2 3 4 5 |
CREATE TABLE option1 (id int not null primary key auto_increment) engine=innodb; # each insert does one operations to get the value: INSERT INTO option1 VALUES (NULL); # $connection->insert_id(); |
Option #2: Use a table with one just row:
|
1 2 3 4 5 6 |
CREATE TABLE option2 (id int not null primary key) engine=innodb; INSERT INTO option2 VALUES (1); # start from 1 # each insert does two operations to get the value: UPDATE option2 SET id=@id:=id+1; SELECT @id; |
So which is better? I don’t think it’s that easy to tell at a first glance, since option 2 does look more elegant – but if the next value is fetched as part of a transaction – I can see a potential for many other transactions to back up waiting on a lock (more on that in a second).
To start with a naive test, I booted two EC2 small instances in the same availability zone. Ping times are ~0.5ms between nodes. –skip-name resolve is enabled on the server. There is some skew from the machine being virtualized. My simulation is:
The testing options are:
The raw results are:
|
1 2 3 4 |
option1 usetransactions =19 seconds for x10000 iterations. option1 ignoretransactions = 13 seconds for x10000 iterations. option2 usetransactions = 27 seconds for x10000 iterations. option2 ignoretransactions =22 seconds for x10000 iterations. |
Alright – option1 seems quicker. The problem is that to be like most applications, we can’t really tell until a little concurrency is applied. Using only the “transactional” test in a few more concurrency options:
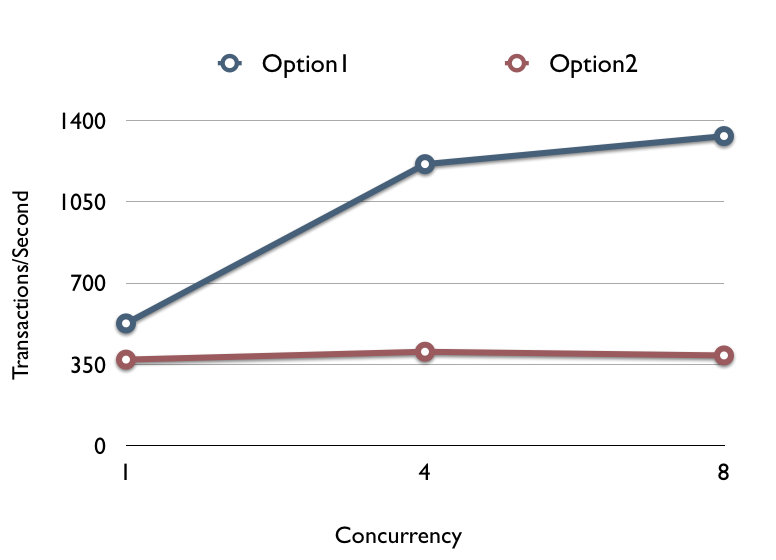
(results are transactions/second – more is better).
Option #1 starts to flatten out after 4 threads – and this is probably just because the machine I am running it against has 1 CPU. Option #2 stays flat the whole time.. and while we are running it, most of the threads are perpetually in a state of ‘Searching rows for update’ – which is what I suspect is better described as waiting on a lock.
Option #2 will likely scale better in auto_commit, since locks are held for the duration of a transaction, but this is not always possible to do if you have already started modifying data before you need an auto_increment number but you do not want to commit yet.





http://code.flickr.com/blog/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/
Flickr’s ticket servers use REPLACE INTO and LAST_INSERT_ID to do this same thing.
Option 3: use Redis
INCR mysql:id
Returns the next ID to use, and can handle 100k of these requests per second on a laptop
Option 4: Use PostgreSQL or some other DB that implements sequences 🙂
See http://openquery.com/blog/implementing-sequences-using-a-stored-function-and-triggers and comments (from 2005), does this transparently as a stored proc with triggers, so the app can actually pretend it’s using the auto-inc.
To avoid the “it’s within a transaction” issue you could use MyISAM for the sequence table. That of course has some other consequences such as what happens in a crash – but that could be sorted by a stored proc on server startup that grabs the max sequence value from the tables where the sequences are used making sure that the sequence table is at the right point.
There are app layer code conventions you can use to general universally unique ids, you’ll just need more bits to guarantee uniqueness. Something like a 128 bit UUID
MAC address of eth0 + process startup time in ms + current time in ms + counter that resets every ms
Then you can just call
insert into sometable values(getMyGuid(), name, rank, serial_number)
Another solution is to issue:
UPDATE option1 SET id = LAST_INSERT_ID(id+1);
New id is then available with mysql_insert_id API call.
This problem occurs most often in sharded data sets. Since I recommend using a directory based sharding method, method #1 or the method in comments #1 or #6 work very well on the directory server.
I suggest including the sharding key as part of the primary key of each table, so I it is safe to use auto_increment on each shard (if you need to identify insert order, for example to return only N most recent items):
create table some_sharded_table(
shard_key int,
some_child_key bigint auto_increment not null,
key(some_child_key),
primary key (shard_key, some_child_key),
data1 int,
data2 char(10),
…
)
You can safely move records between shards, because the primary key includes the directory provided key. The directory server maps keys to shards.
You can then partition
some_sharded_tablenicely:alter table some_sharded_table partition by hash(shard_key) partitions 16;
All the values related to one shard_key are now in one physical server, and the values are then partitioned again locally for improved performance through smaller indexes. This helps alleviate the overhead of the increased length of the secondary key used for the auto_increment value.
You can use the primary key index to get the most recent N rows very efficiently for any shard_key, something that is very common in most sharded applications that I see.
At one point in Mysql 5.0 or later, there was a bug that caused updating a primary key to be slow. I’d retest senario number two with an update to a non primary key column.
Like:
CREATE TABLE option2 (dumb_key int not null primary key, id int not null) engine=innodb;
INSERT INTO option2 VALUES (1,1); # start from 1
# each insert does two operations to get the value:
UPDATE option2 SET id=@id:=id+1;
SELECT @id;
At one point that was a lot faster than updating the primary key.
William – updating via a primary key should always be faster in InnoDB (data is stored in a clustered index). If you have a bug number to prove otherwise, I would be interested to hear it.