
I will be talking about Big Data with MySQL and Hadoop at MySQL Connect 2013 (Sept. 21-22) in San Francisco as well as at Percona University at Washington, DC (September 12, 2013). Apache Hadoop is a very popular Big Data solution and we can nowadays easily integrate it with MySQL. I will start with a brief introduction of Apache Hadoop and its components (HFDS, Map/Reduce, Hive, HBase/HCatalog, Flume, Scoop, etc). Next I will show 2 major Big Data scenarios:
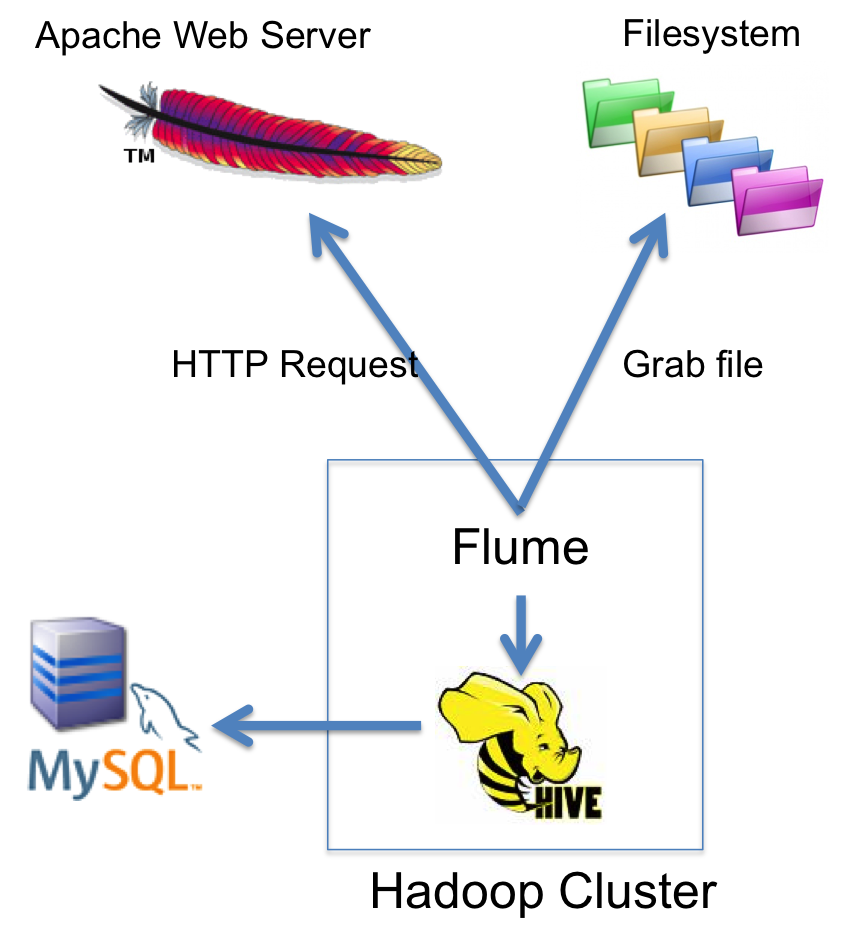
Picture 1: ELT pipeline, from File to Hadoop to MySQL
Picture 2: From OLTP MySQL to Hadoop to MySQL reporting.
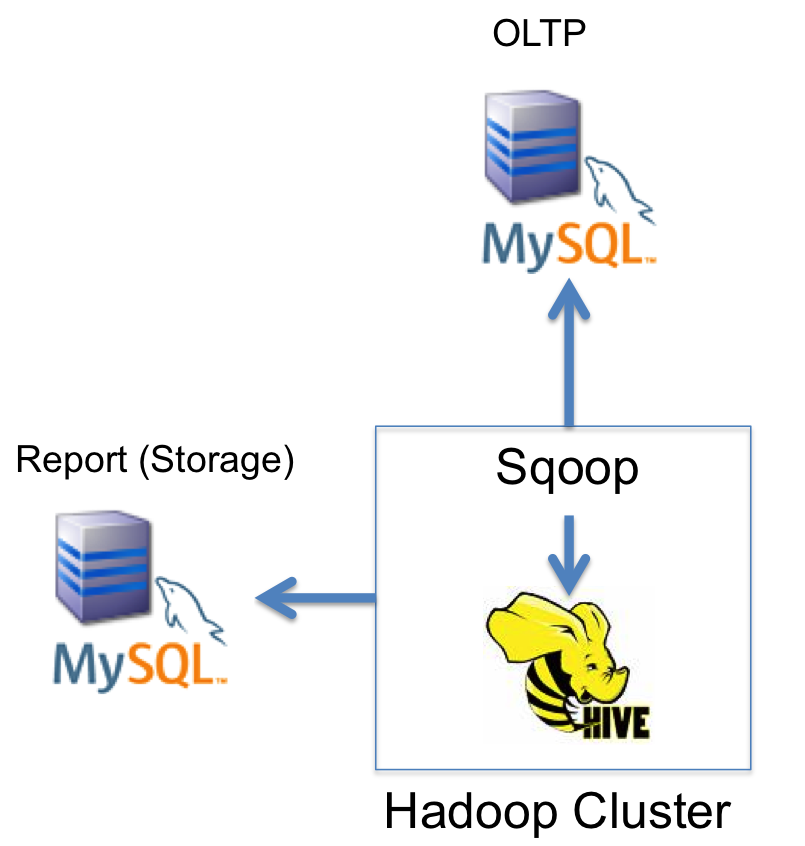
Note: The reason why we need an additional storage for MySQL reports is that it may take a long time to generate a Hive report (as it is executed with Map/Reduce which reads all the files/no indexes). So it make sense to “offload” a common reports’ results into a separate storage (MySQL).
In both scenarios we will need a way to integrate Hadoop and MySQL. In my previous post, MySQL and Hadoop integration, I have demonstrated how to integrate Hadoop and MySQL with Sqoop and Hadoop Applier for MySQL. This case is similar, however we can use a different toolset. In the scenario 1 (i.e. Clickstream) we can use Apache Flume to grab files (or read “events”) and load them into Hadoop. With Flume we can define a “source” and a “sink”. Flume supports a range of different sources including HTTP requests, Syslog, TCP, etc. HTTP source is interesting, as we can convert all (or a number of) HTTP requests (“Source”) into an “event” which can be loaded into Hadoop (“Sink”).
During my presentation I will show the exact configurations for the sample Clickstream process, including:
See you at MySQL Connect 2013!
Resources
RELATED POSTS





From OLTP MySQL to Hadoop to MySQL reporting. In this scenario we extract data (potentially close to real-time) from MySQL, load it to Hadoop for storage and analysis and later generate reports to load it into another MySQL instance (reporting), which can be used to generate and display graphs.
how to real-time extract data from mysql?