The latest release of the Percona Operator for MySQL, 1.1.0, is here. It brings point-in-time recovery, incremental backups, zstd backup compression, configurable asynchronous replication retries, and a set of stability fixes. This post walks through the highlights and how they help your MySQL deployments on Kubernetes.

Running stateful databases on Kubernetes means your backup and recovery story has to be airtight. A full nightly backup is fine, until the DBA drops a table at 2 PM and you’re looking at 14 hours of lost work. Or until your storage bill grows faster than your actual data because every backup is a full copy.
Percona Operator for MySQL 1.1.0 addresses exactly these pain points. This release lands point-in-time recovery, incremental backups, and backup compression: three features that together give you finer recovery control, faster backup jobs, and meaningfully smaller storage footprints. It also brings configurable asynchronous replication retries and a set of stability fixes that harden everyday operations.
This is a community-driven release. Nearly every headline feature in 1.1.0 traces back to user feedback: issues raised on forums.percona.com, JIRA tickets filed by operators in production, and recurring questions from teams running MySQL on Kubernetes at scale. The operator is fully open source, runs on any CNCF-conformant Kubernetes distribution (GKE, EKS, OpenShift, or bare metal), and costs nothing to run. Let’s walk through what’s new.
In this post, you’ll learn about:
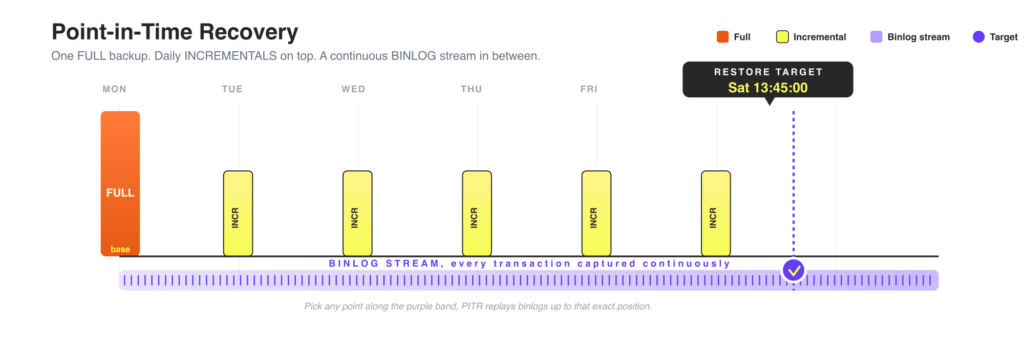
A backup restores your cluster to the moment the backup was taken, but incidents rarely respect your backup schedule. With point-in-time recovery now available in Tech Preview, you can restore your MySQL cluster to any specific timestamp or GTID position, not just to a backup snapshot.
The operator continuously collects binary logs and stores them alongside your full and incremental backups. When a restore is needed, it starts from the nearest full backup, applies incremental backups, and then replays binary logs forward to the exact point in time you specify. PITR works identically across asynchronous and group replication topologies, so you don’t need to restructure your setup to take advantage of it.
A timestamp-based restore targets the exact moment before an incident:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: ps.percona.com/v1 kind: PerconaServerMySQLRestore metadata: name: restore-pitr-example spec: clusterName: cluster1 backupName: backup-20260418 pitr: type: date date: "2026-04-18 13:45:00" #Restore with GTID # type: gtid # gtid: a3e5ff70-83e2-11ef-8e57-7a62caf7e1e3:1-36 |
When you need finer precision than timestamp-based recovery (for example, replaying right up to the transaction immediately before a bad UPDATE), use pitr.type: gtid and specify the exact GTID position.
This is especially useful after an accidental DROP TABLE or a bad application deploy mid-day: you recover to the moment just before the event, not to last night’s snapshot.
See the documentation for the full configuration reference.
Note: PITR is marked Tech Preview in 1.1.0 and is not recommended for production workloads yet. Try it in staging and share your feedback on the community forum.
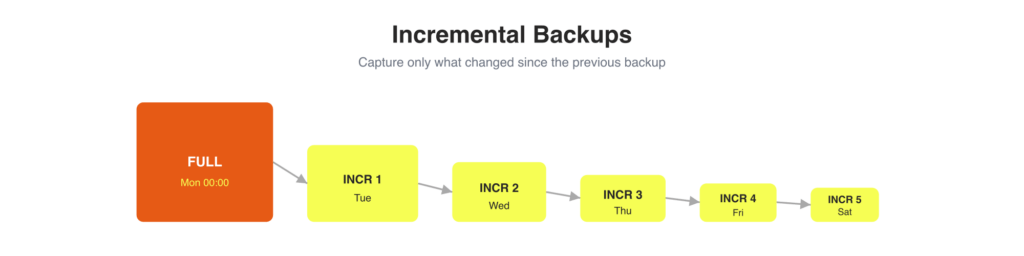
Full backups work, but they come with a cost: every job copies your entire dataset, consuming time, I/O, and storage whether or not much has changed since the last run. Incremental backups solve this by capturing only the changes since the previous backup.
The Operator integrates incremental backup support, powered by Percona XtraBackup, across all supported backup storage backends (S3-compatible, GCS, Azure Blob Storage). Both scheduled and on-demand backup jobs can run incrementally. When you trigger a restore, the Operator reconstructs the full state by chaining the base backup with the subsequent incremental sets, so you don’t manage that complexity manually.
This helps when you need:
The backup manifest lives in deploy/backup/backup.yaml. Note the commented type and incrementalBaseBackupName fields: they are exactly how you switch a backup to incremental mode and point it at a previous backup as its base.
|
1 2 3 4 5 6 7 8 9 10 |
apiVersion: ps.percona.com/v1 kind: PerconaServerMySQLBackup metadata: finalizers: - percona.com/delete-backup name: backup1 spec: clusterName: ps-cluster1 storageName: minio type: incremental |
Set type: full to take a base backup, then for each subsequent incremental set type: incremental.
Note: Incremental backups are also marked Tech Preview in 1.1.0. You can learn more about this feature in a separate blog post: Incremental backups in Percona Kubernetes Operator for MySQL

Even without incremental backups, you can now shrink your full backup size significantly. The operator adds support for zstd compression, which compresses backup data with Percona XtraBackup before it streams to object storage.
Smaller transfers mean faster uploads, lower egress costs, and less object storage consumption, especially relevant when your cluster is in a different region from your storage bucket. The operator handles decompression transparently during restore, so your recovery workflow stays the same.
You can enable compression globally by configuring XtraBackup in mysql.configuration on the Custom Resource:
|
1 2 3 4 5 |
spec: mysql: configuration: | [xtrabackup] compress=zstd |
Or enable it per on-demand backup via containerOptions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: ps.percona.com/v1 kind: PerconaServerMySQLBackup metadata: name: backup1-compressed finalizers: - percona.com/delete-backup spec: clusterName: ps-cluster1 storageName: s3-us-west containerOptions: args: xtrabackup: - "--compress" |
Full details are in the compressed backups documentation. Percona XtraBackup’s zstd compression reference covers the algorithm-level tradeoffs if you want to tune further. One known limitation in 1.1.0: lz4 compression is not yet supported pending an upstream resolution.
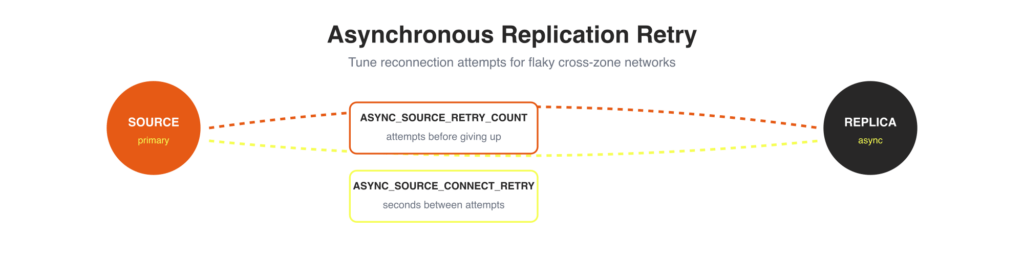
In asynchronous replication topologies, transient network issues can stall replication threads on a MySQL Pod. Previously, reconnection behavior was fixed. Now you can tune it via the Custom Resource using two environment variables:
|
1 2 3 4 5 6 7 |
spec: mysql: env: - name: ASYNC_SOURCE_RETRY_COUNT value: "10" - name: ASYNC_SOURCE_CONNECT_RETRY value: "30" |
This is useful in environments with higher network latency or less reliable connectivity between zones. You can give the replica more time to recover without manual intervention.
A related improvement (K8SPS-69): the readiness probe now fails if replication threads stop on a MySQL Pod. This prevents Kubernetes from routing traffic to a replica that has quietly fallen behind, a common source of stale reads that were difficult to detect without custom monitoring.
Operational polish shipped alongside the headline features:
The release also ships improved documentation: OpenShift installation instructions now include the full OLM procedure, an Operator upgrade tutorial for OpenShift has been added, and Helm documentation covers customized parameters and custom release naming.
Percona Operator for MySQL 1.1.0 delivers meaningful improvements to every phase of the database lifecycle on Kubernetes. PITR and incremental backups in Tech Preview give you a path toward granular recovery without full-backup overhead. Compression with zstd reduces your storage and egress costs immediately. Configurable async replication retries and a batch of stability fixes harden the Operator for production workloads at scale. These features are in this release because the community asked for them.
We encourage you to read the full release notes and try the new features. Feedback is welcome on the GitHub repository, the Community Forum, or JIRA.
Resources
RELATED POSTS




