
This post was originally published in July 2023 and updated in March 2025.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour, businesses increasingly rely on high availability (HA) technologies to maximize application uptime. Unfortunately, achieving HA with certain open source databases can present challenges, and despite its strengths, PostgreSQL software requires careful consideration.
PostgreSQL provides foundational features for high availability, including physical and logical replication and consistent backups with point-in-time recovery (PITR). However, PostgreSQL itself does not offer a complete, out-of-the-box HA solution. DBAs often need to integrate open source extensions and tools from various sources to build a truly PostgreSQL High Availability architecture.
This piecemeal approach can inadvertently create a Single Point of Failure (SPOF), potentially interrupting services – the very outcome HA aims to prevent. As environments scale, the risk of SPOFs can increase if the initial HA design doesn’t evolve with complexity.
This blog highlights key considerations for maintaining highly available and healthy PostgreSQL databases. We’ll examine the intricacies of establishing PostgreSQL High Availability and provide links to Percona HA reference architectures.
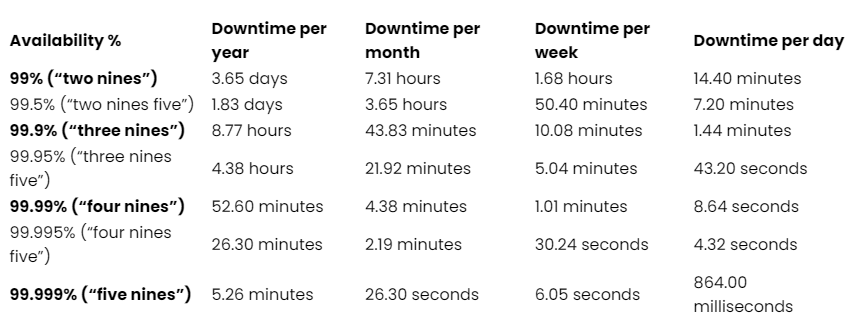
High availability is essential for any business that relies on digital interactions — and today, that means just about everyone. The tolerable downtime depends on business size, operations, and objectives, but that downtime must be minimal to minuscule (see the “Measuring high availability” chart below). HA in PostgreSQL databases delivers virtually continuous availability, fault tolerance, and disaster recovery. It enables businesses and organizations to meet uptime and service level objectives, protect business-critical data, and maintain performant databases.
Achieving PostgreSQL High Availability fundamentally requires:
A complete PostgreSQL High Availability solution typically addresses four key areas:
Before designing a PostgreSQL HA solution, evaluate your specific requirements:
Downtime Tolerance: How much downtime (if any) can the business withstand financially and reputationally?
Industry Requirements: Are there regulatory or compliance mandates for availability?
Recovery Time Objective (RTO): How quickly must service be restored after a failure?
Cost vs. Benefit: Can the business afford the hardware, software, and operational overhead of the required HA level?
Expertise: Do you have the internal resources and skills to design, implement, and manage the HA solution?

HA levels are often expressed in “nines,” indicating the percentage of uptime. Even “five nines,” the gold standard, allows for a small amount of downtime per year.
Before delving further into the inner workings of PostgreSQL high availability, let’s briefly examine the burgeoning popularity of this open source relational database software.
PostgreSQL has rapidly gained favor among professional developers in recent years. StackOverflow statistics show that 26% of developers preferred it in 2017, 34% in 2019, and 40% in 2021. Most recently, in StackOverflow’s 2022 Stack Developer Survey, PostgreSQL took a slight lead over MySQL (46.48% to 45.68%) as the most popular database platform among professional developers.
PostgreSQL is favored among relational database options for its complex data analysis, data science, graphing, and AI-related capabilities. PostgreSQL is known for powerful and advanced features, including synchronous and asynchronous replication, full-text searches of the database, and native support for JSON-style storage, key-value storage, and XML.
PostgreSQL is highly extensible, enabling users to add custom functionality through plug-ins and extensions. It also features tools such as repmgr and Patroni for automatic failover and cluster management.
Being a more advanced database management system, PostgreSQL is well-suited for performing complex queries in a large environment quickly. Because it readily supports failover and full redundancy, it’s often preferred by financial institutions and manufacturers. It’s also preferred for use with geographic information systems (GIS) and geospatial data. PostgreSQL ranks as the fourth most popular database management system (DB-Engines, March 2023).
Because PostgreSQL software is open source, it’s free of proprietary restrictions that can come with vendor lock-in. Developers can customize the source code and try new applications without a big budget hit. Companies can more easily scale infrastructure — up or down — to meet economic conditions and changing business objectives. With open source software, a business is not trapped into using one provider’s software, support, or services. Instead, the business may design and redesign systems as customer expectations change and business objectives evolve.
Also, with open source, there’s a global community of dedicated volunteers driving the development of PostgreSQL database technology. Open source standards and community support enable developers and DBAs to focus on accelerating PostgreSQL feature creation and enhancing availability, performance, scalability, and security.
Now, let’s go into more detail about high availability with PostgreSQL. Several methods of the aforementioned replication form the backbone of PostgreSQL high availability. They allow for data redundancy, fault tolerance, failover amid disasters, power outages, human incursions — just about any scenario. Those methods include:
With streaming replication, the entire database cluster is replicated from one server, known as the primary, to one or more standby servers. The primary server continuously streams the write-ahead logs (WAL) to the standby servers, which apply the changes to their own database copies. Streaming replication comes in two modes:
Replication forms the backbone, ensuring data redundancy.
Streaming Replication: Replicates the entire database cluster (physical changes via WAL records) from a primary to one or more standbys.
Synchronous Streaming Replication: Primary waits for confirmation from at least one standby before committing. Minimizes data loss risk but can impact write performance.
Asynchronous Streaming Replication: Primary commits without waiting for standby confirmation. Default mode, higher performance, but potential for minor data loss on immediate primary failure.
Logical Replication: Replicates changes at the object level (e.g., specific tables) based on logical data changes. Offers more flexibility (e.g., replicating between different major versions, replicating subsets of data). Uses a publisher/subscriber model.
Failover is the process of promoting a standby server to become the new primary when the original primary fails.
Manual Failover: Initiated by an administrator.
Automatic Failover: Triggered automatically by a monitoring system or cluster manager (like Patroni) upon detecting primary failure. This is crucial for minimizing RTO.
Automatic Switchover refers to the automated process managed by tools that monitor the primary and orchestrate the failover seamlessly when predefined failure conditions are met.
Tools like Patroni and Replication Manager (repmgr) significantly simplify managing PostgreSQL High Availability clusters. They automate tasks such as:
Monitoring primary and replica health.
Performing automatic failover.
Managing cluster configuration.
Assisting with switchover operations.
To handle traffic efficiently and ensure applications connect to the current primary after a failover, connection management is vital.
Connection Pooling: Tools like Pgbouncer or pgpool-II maintain a pool of ready database connections, reducing the overhead of establishing new connections for each application request.
Load Balancing / Connection Routing: Proxies like pgpool-II, Pgbouncer (with specific configurations), or HAProxy sit between applications and the database servers. They route connections to the appropriate node (e.g., writes to primary, reads potentially to replicas). Pgpool-II offers native read/write splitting capabilities.
DNS Load Balancing: A simpler method using multiple DNS records for the same hostname pointing to different database server IPs. Less flexible in dynamic failover scenarios.
Continuous monitoring is essential to detect failures promptly and ensure the HA system is functioning correctly. Tools monitor instance health, replication lag, and other key metrics, triggering alerts for potential issues.
When implemented successfully, the components we’ve examined can make for successful high availability in PostgreSQL databases. But, as stated, the PostgreSQL community version does not come with ready-to-go HA. It takes work, the right architecture, and often some outside help.
Let’s start with the architectures.
There’s an unfortunate misconception that high availability solutions are too expensive for startups and small businesses. But when using open source tools, coupled with an architecture such as the one offered by Percona, high availability on PostgreSQL can be achieved without a big price tag or the need for an overly complex environment. It can be done by building the HA infrastructure within a single data center.
As your business grows, so should your high availability architecture. For medium and large businesses, the consequences of downtime, both in terms of lost revenue and erosion of customer sentiment, can be significant. High availability requires more fault-tolerant, redundant systems and probably larger investments in IT staff. Still, when using open source tools, high availability can be achieved cost-effectively and without the threat of vendor lock-in that can come from paid enterprise SQLs. For medium and large businesses, Percona provides an architecture that spreads availability across data centers to add more layers of availability to the cluster.
For enterprises, the challenges and potential consequences increase exponentially. An architecture must address a lot more. The Percona architecture, for example, features two disaster recovery sites and adds more layers to the infrastructure in order to stay highly available and keep the applications up and running. This architecture, based on tightly coupled database clusters spread across data centers and availability zones, can offer an HA level up to 99.999% when using synchronous streaming replication, the same hardware configuration in all nodes, and fast internode connection.
You can get more details — and view actual architectures — at the Percona Highly Available PostgreSQL web page or by downloading our white paper, Percona Distribution for PostgreSQL: High Availability With Streaming Replication. But for starters, here are elements of a minimalist high availability architecture for PostgreSQL. Such architecture will include at least these four components in the design:
Again, the descriptions immediately above are for a minimalist HA architecture. It can, and usually does, get a lot more complicated. Percona provides proven architectures to get you going, and we offer cost-effective options for help.
Once the method of replication is determined and the architecture is designed, it’s time to deploy it. As with the architecture itself, deployment can be easier and more cost-effective when enlisting high availability support for PostgreSQL from outside experts. It depends on what expertise you have on staff.
Every database environment is different, so deployment procedures can vary, but here are some general steps:
Keeping databases secure demands attention, of course. Yet again, it should be emphasized that every environment is unique, and specific security requirements will vary accordingly. It’s important to check out PostgreSQL documentation. In some cases, if there is no on-staff expertise to maintain adequate security levels of your high availability cluster, it’s wise to consider support.
But whether you can keep your environment secure on your own or need that outside help, there are some general best practices for securing a cluster in a high availability environment:
Configure SSL/TLS encryption of communication with the database cluster. You can disable unnecessary procedures and make it so connections occur only across trusted networks.
Control access. Implementing role-based access control (RBAC) for PostgreSQL can be a helpful way of managing permissions and restricting access to sensitive data.
Use strong authentication. That means strong user passwords that are regularly changed. In more sensitive situations, it’s advisable to implement more secure methods like certificate-based authentication or LDAP integration. PostgreSQL supports a variety of external authentication methods, including GSSAPI, LDAP, and RADIUS.
Audit, log, and regularly review. You can configure PostgreSQL to log queries, failed logins, administrative activity, and any other events. Then, you can examine the logs at any time to spot potential security breaches or suspicious activity.
Conduct regular updates. Apply the latest PostgreSQL security patches and bug fixes ASAP when available. Stay active, or at least observant, as a participant in the global open source community. Stay informed about the latest PostgreSQL security information, including news about vulnerabilities and recommended patches.
Building high availability for PostgreSQL doesn’t have to mean piecing things together yourself or risking costly downtime. Percona brings you proven architectures, open source flexibility, and support options that fit your team, whether you want guidance, occasional help, or fully managed services. Our experts work with you to design and operate resilient PostgreSQL environments, free from vendor lock-in or hidden costs.
Want to see how it works and what’s included? Visit our PostgreSQL High Availability page for details on our approach, technologies, and how we help you achieve always-on PostgreSQL.
See PostgreSQL High Availability solutions
The following are commonly asked questions and short answers about high availability in PostgreSQL databases. More detailed answers are presented in the sections above.
1. What is the difference between high availability and disaster recovery?
PostgreSQL High Availability (HA) focuses on minimizing downtime and ensuring continuous service through redundancy (replication) and automatic failover. Disaster Recovery (DR) focuses on recovering data and services after a major catastrophic event, often relying on backups stored offsite and potentially involving longer recovery times. HA is about uptime; DR is about recovery from major loss.
2. Can high availability architecture eliminate all downtime?
No HA architecture guarantees 100% uptime. Even “five nines” (99.999%) availability allows for ~5 minutes of downtime per year. PostgreSQL High Availability aims to significantly minimize planned and unplanned downtime, but brief interruptions during failover or maintenance might still occur.
3. What are common challenges when implementing PostgreSQL high availability?
Common challenges include the complexity of integrating multiple open source tools (for replication, failover, pooling, monitoring), avoiding Single Points of Failure (SPOFs) in the architecture, correctly configuring network routing/connection management after failover, testing the failover process thoroughly, and managing replication lag.
4. What technologies are typically used for PostgreSQL high availability architecture?
Essential technologies include: PostgreSQL Replication (Streaming or Logical), automated failover tools/cluster managers (e.g., Patroni, repmgr), load balancing/connection poolers (e.g., HAProxy, Pgbouncer, pgpool-II), robust monitoring and alerting systems, and solid backup/WAL archiving solutions.
5. How often should PostgreSQL high availability architecture be tested and validated?
Testing frequency depends on the business’s criticality and RTO requirements. Regular testing (e.g., quarterly failover drills in a staging environment) is highly recommended. More critical systems might warrant more frequent or automated validation checks (e.g., monthly). Chaos engineering practices can also be valuable for proactively finding weaknesses.
Resources
RELATED POSTS




