
Diablo Technologies engaged Percona to benchmark IBM eXFlash™ DIMMs in various aspects. An eXFlash™ DIMM itself is quite an interesting piece of technology. In a nutshell, it’s flash storage, which you can put in the memory DIMM slots. Enabled by Diablo’s Memory Channel Storage™ technology, this practically means low latency and some unique performance characteristics.
These devices are special, because their full performance potential is unlocked by using multiple devices to leverage the parallelism of the memory subsystem. In a modern CPU there is more than one memory controller (4 is typical nowadays) and spreading eXFlash™ DIMMs across them will provide maximum performance. There are quite some details about the device that are omitted in this post, they can be found in this redbook.
Diablo technologies also provided us a 785 GB FusionIO ioDrive 2 card (MLC). We will compare the performance of it to 4 and 8 of the eXFlash DIMMs. The card itself is a good choice for comparison because of it’s popularity, and because as you will see, it provides a good baseline.
CPU: 2x Intel Xeon E5-2690 (hyper threading enabled)
FusionIO driver version: 3.2.6 build 1212
Operating system: CentOS 6.5
Kernel version: 2.6.32-431.el6.x86_64
Sysbench command used:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
sysbench --test=fileio --file-total-size=${size}G --file-test-mode=${test_mode} --max-time=${rtime} --max-requests=0 --num-threads=$numthreads --rand-init=on --file-num=64 --file-io-mode=${mode} --file-extra-flags=direct --file-fsync-freq=0 --file-block-size=16384 --report-interval=1 run |
The variables above mean the following:
Size: the devices always had 50% free space.
Test_mode: rndwr, rndrw, rndrd for the different types of workloads (read, write, mixed)
Rtime: 4 hours for asynchronsous tests, 30 minutes for synchronous ones.
Mode: sync or async dependening on which test are we talking about.
From the tdimm devices, we created RAID0 arrays with linux md (this is the recommended way to use them).
In case of 4 devices:
|
1 |
mdadm --create /dev/md0 --level=0 --chunk=4 --raid-devices=4 /dev/td{a,c,e,g} |
In case of 8 devices:
|
1 |
mdadm --create /dev/md0 --level=0 --chunk=4 --raid-devices=8 /dev/td{a,b,c,d,e,f,g,h} |
The filesystem used for the tests was ext4, it was created on the whole device (md0 or fioa, no parititions), which the block size of 4k.
We tested these with read-only, write-only and mixed workloads with sysbench fileio. The read/write ratio with the mixed test was 1.5. Apart from the workload itself, we varied the IO mode as well (we did tests with synchronous IO as well as asynchronous IO). We did the following tests.
The asynchronous read tests lasted 4 hours, because we tested the consistency of the device’s performance with those over time.
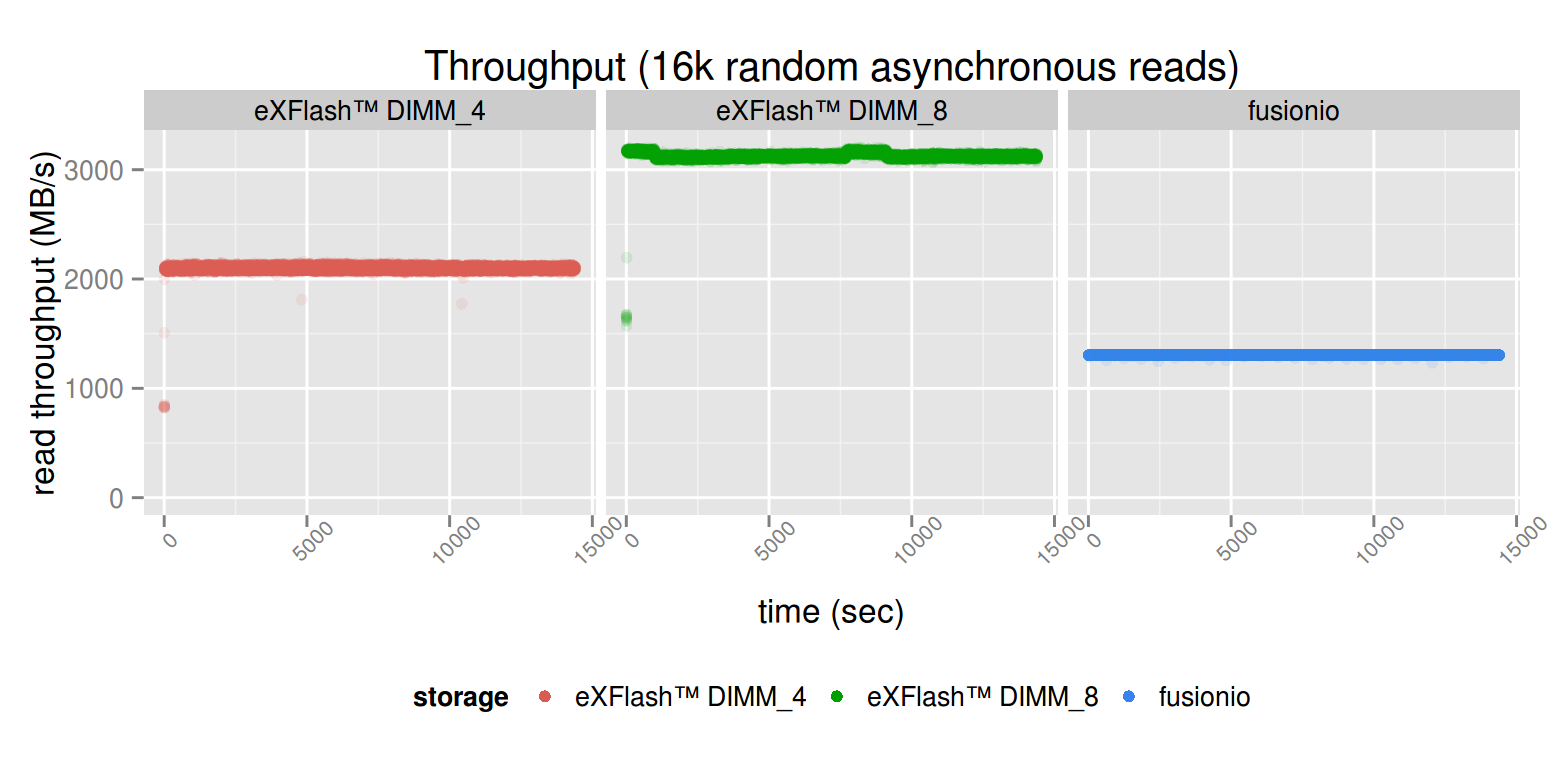
The throughput is fairly consistent. With 8 dimms, the peak throughput goes above 3 GB/s in case of 8 eXFlash DIMMs.
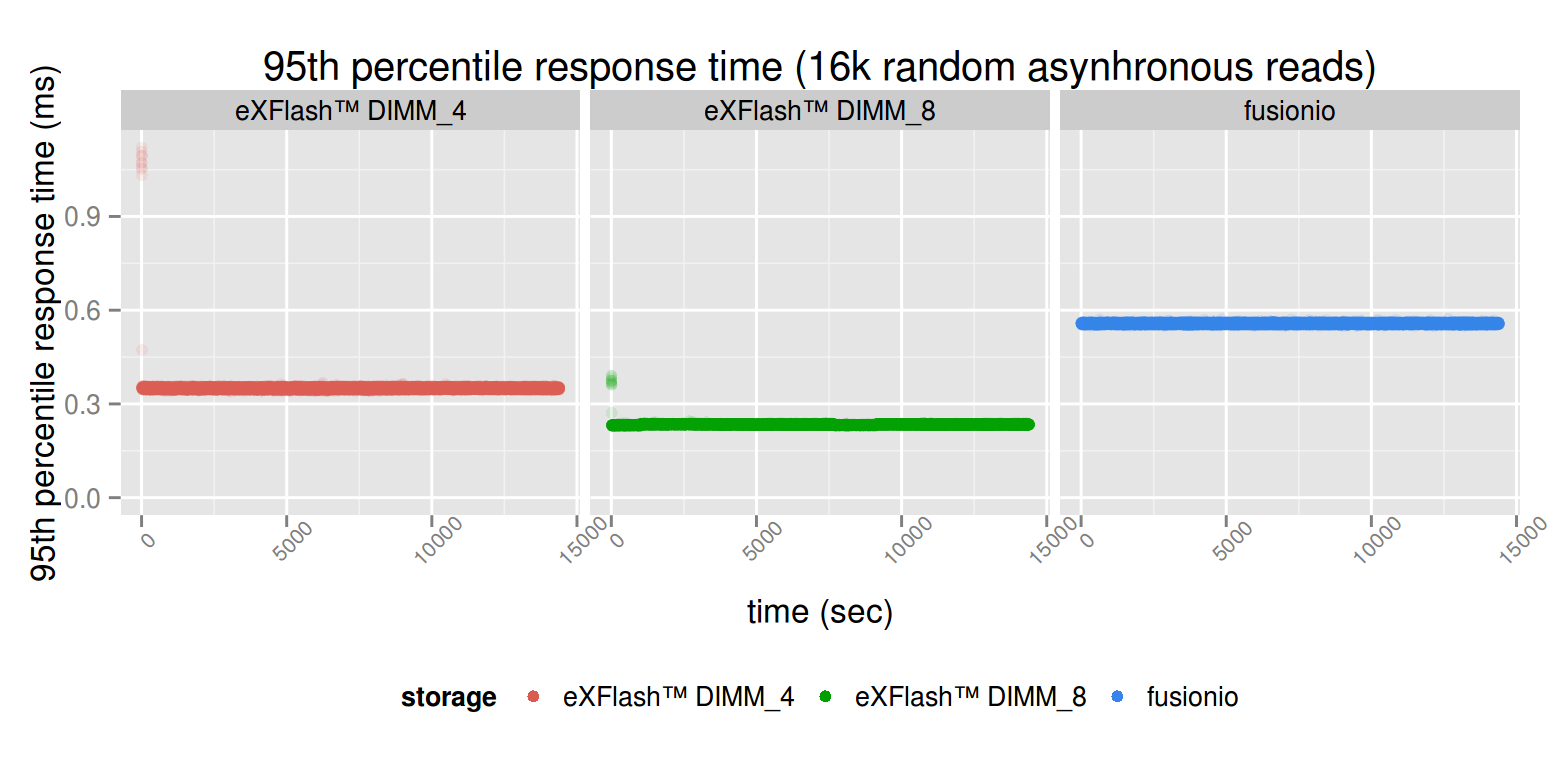
At the beginning of the testing we expected that latency would drop significantly in case of eXFlash DIMMs. We based this assumption on the fact that the memory is even “closer” to the processor than the PCI-E bus. In case of 8 eXFlash DIMMs, it’s visible that we are able to utilize the memory channels completely, which gives a boost in throughput as well as it gives lower latency.
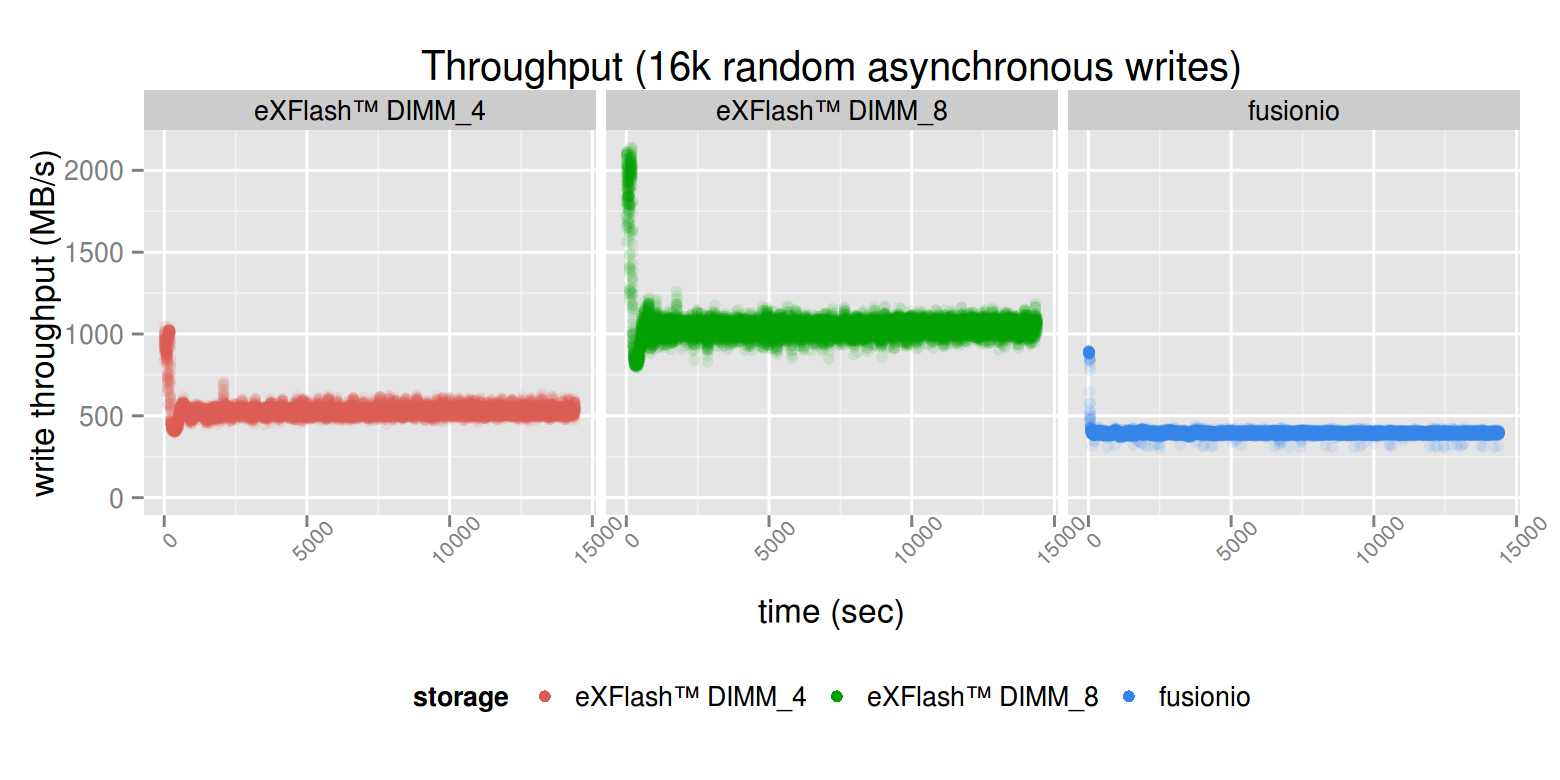
The consistent asynchronous write throughput is around 1GB/sec in case of eXFlash DIMM_8. Each case at the beginning has a spike up in throughput: that’s the effect of caching. In eXFlash DIMM itself, the data can arrive much faster on the bus than it could be written to the flash devices.
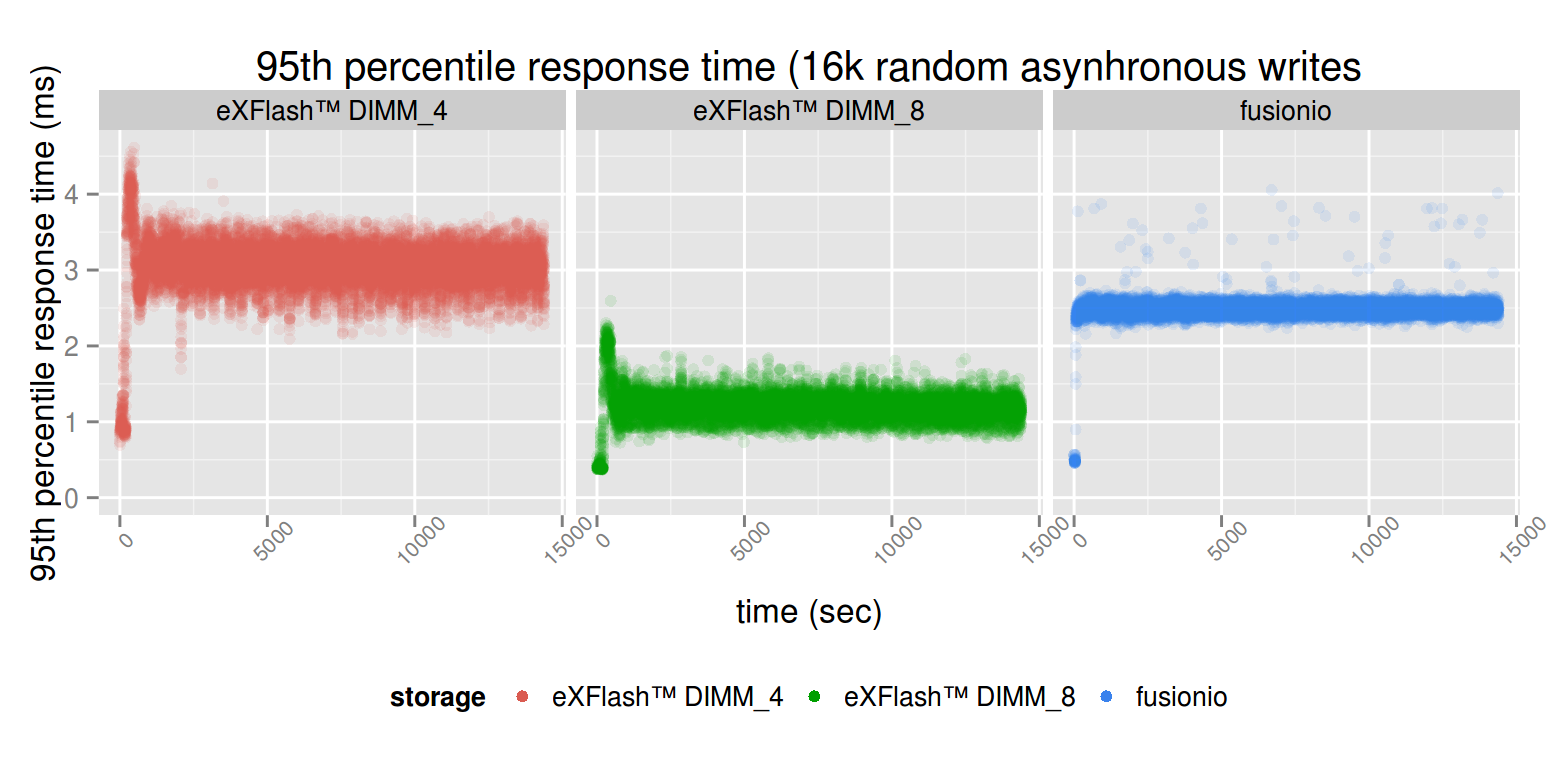
In case of write latency, the PCI-E based device is Somewhat better, and also the performance is more consistent compared to the case where we were using 4 eXFlash DIMMs. When using 8, similarly to the case where only reads were tested in isolation, both the throughput increased and the latency drops.
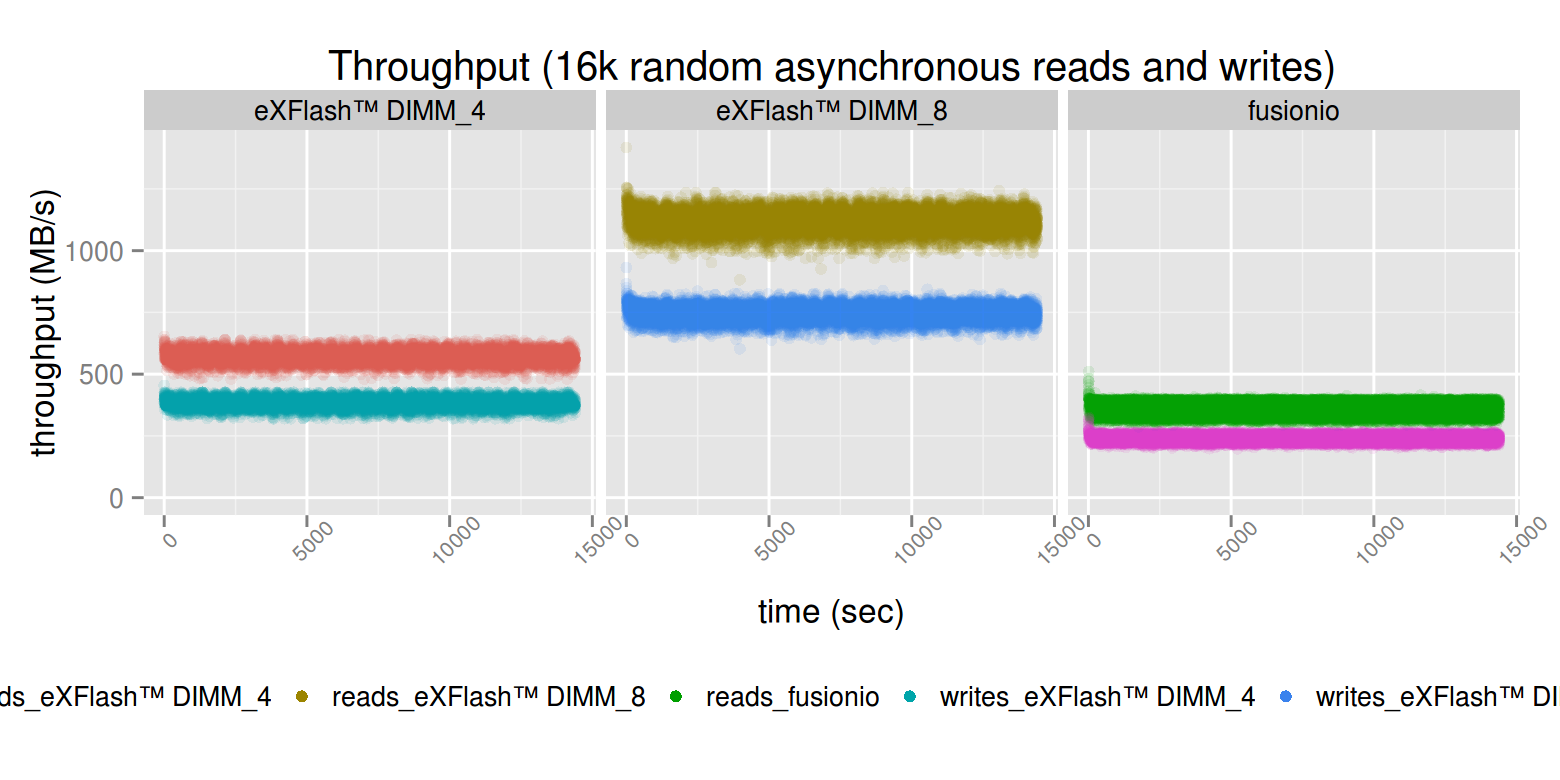
In the mixed workload (which is quite relevant to some databases), the eXFlash DIMM shines. The throughput in case of 8 DIMMs can go as high as 1.1 GB/s for reads, while it’s doing roughly 750 MB/s writes.
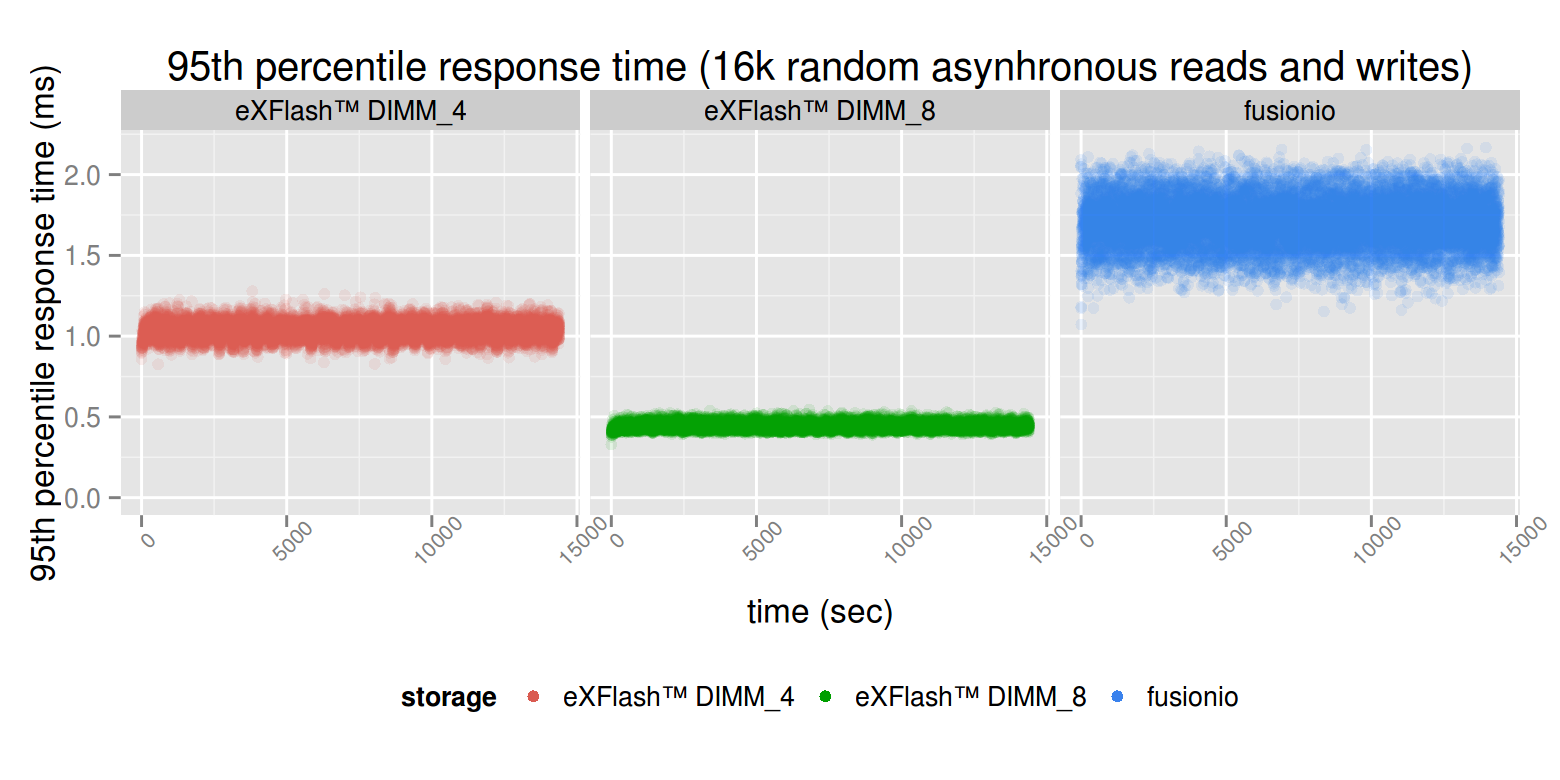
In case of mixed workload, the latency is the eXFlash DIMMs is lower and far more consistent (the more DIMMs we use, the more consistent it will be).
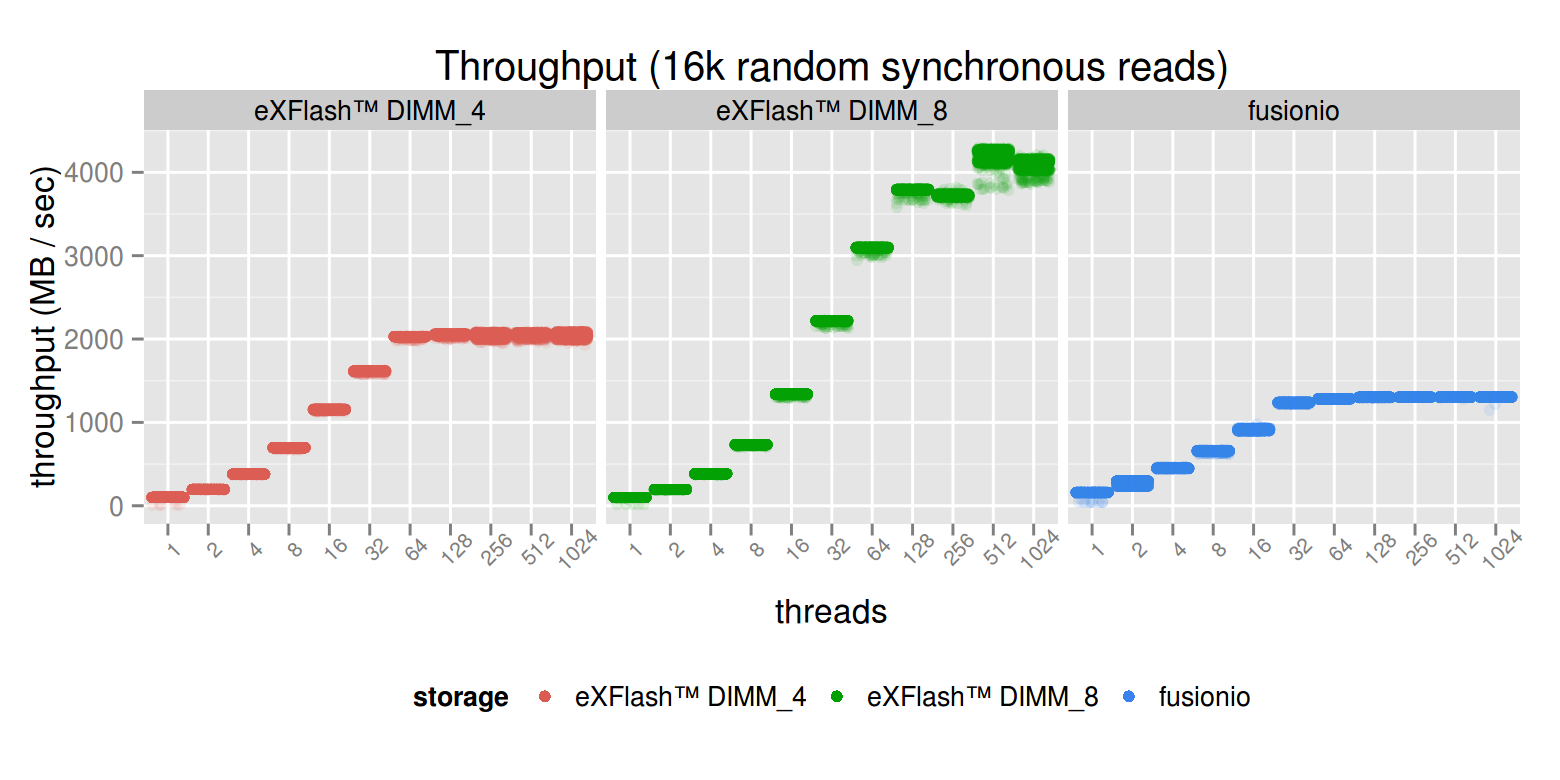
In case of synchronous IO, we reached the peak throughput at 32 threads used in case of the PCI-E device, but needed 64 and 128 threads for the eXFlash DIMM_4 and eXFlash DIMM_8 configurations respectively (in both cases, the throughput at 32 threads was higher than the PCI-E device’s).
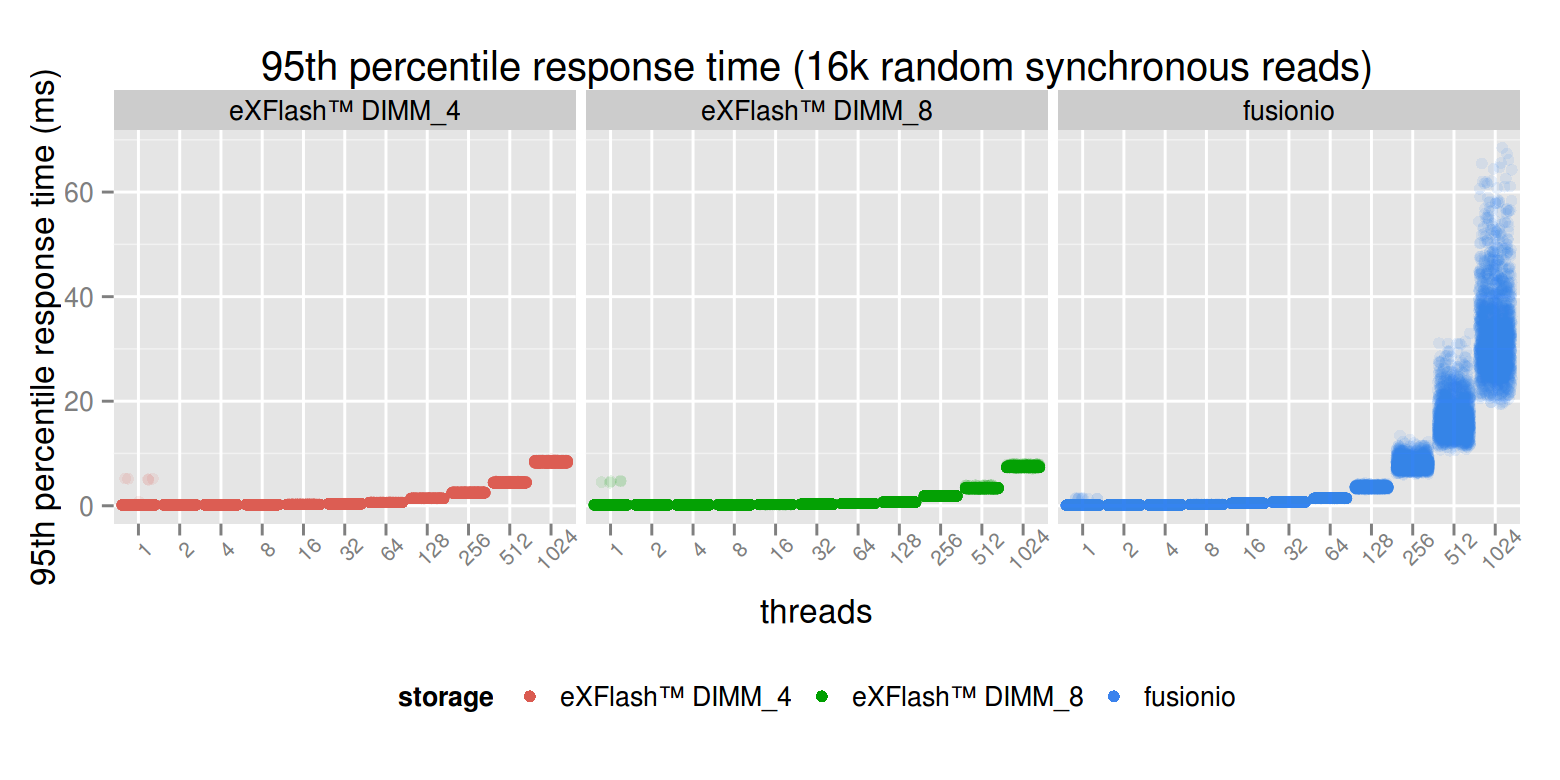
The read latency degrades much more gradually in case of the eXFlash DIMMs, which makes it very suitable for workloads like linkbench, where the buffer pool misses are more frequent than writes (many large web application have this kind of read mostly and the database doesn’t fit into memory profile).In order to be able to see the latency differences at a lower number of threads, this graph has to be zoomed in a bit. The following graph is the same (synchronous read latency), but the y axis has a maximum value of 10 ms.
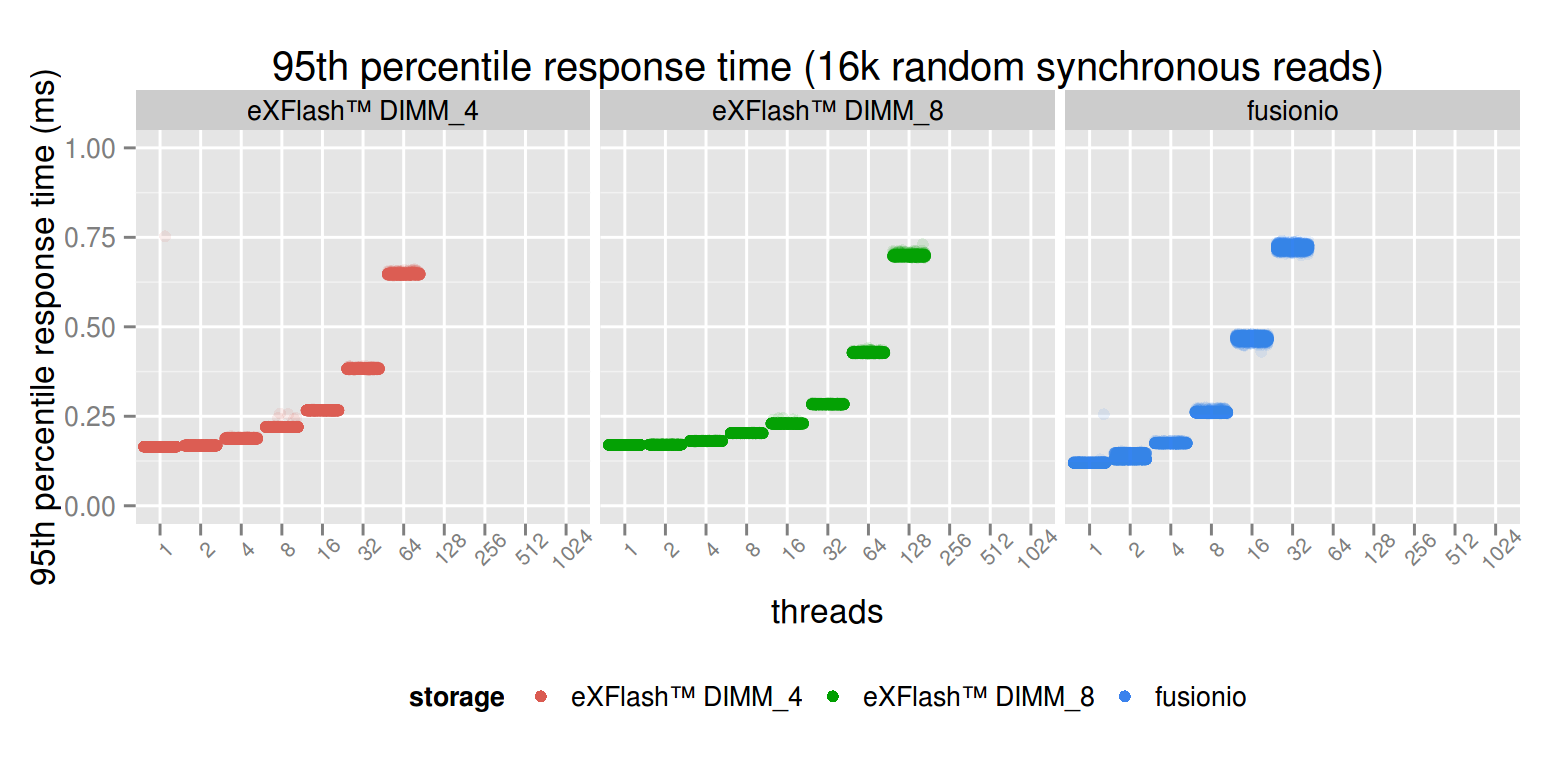
The maximum value is hit at 256 threads in case of the PCI-E device, and performance is already severely degraded at 128 threads (which is the optimal degree of parallelism for the eXFlash DIMM_8 configuration). Massively parallel, synchronous reads is a workload where the eXFlash DIMMs are exceptionally good.
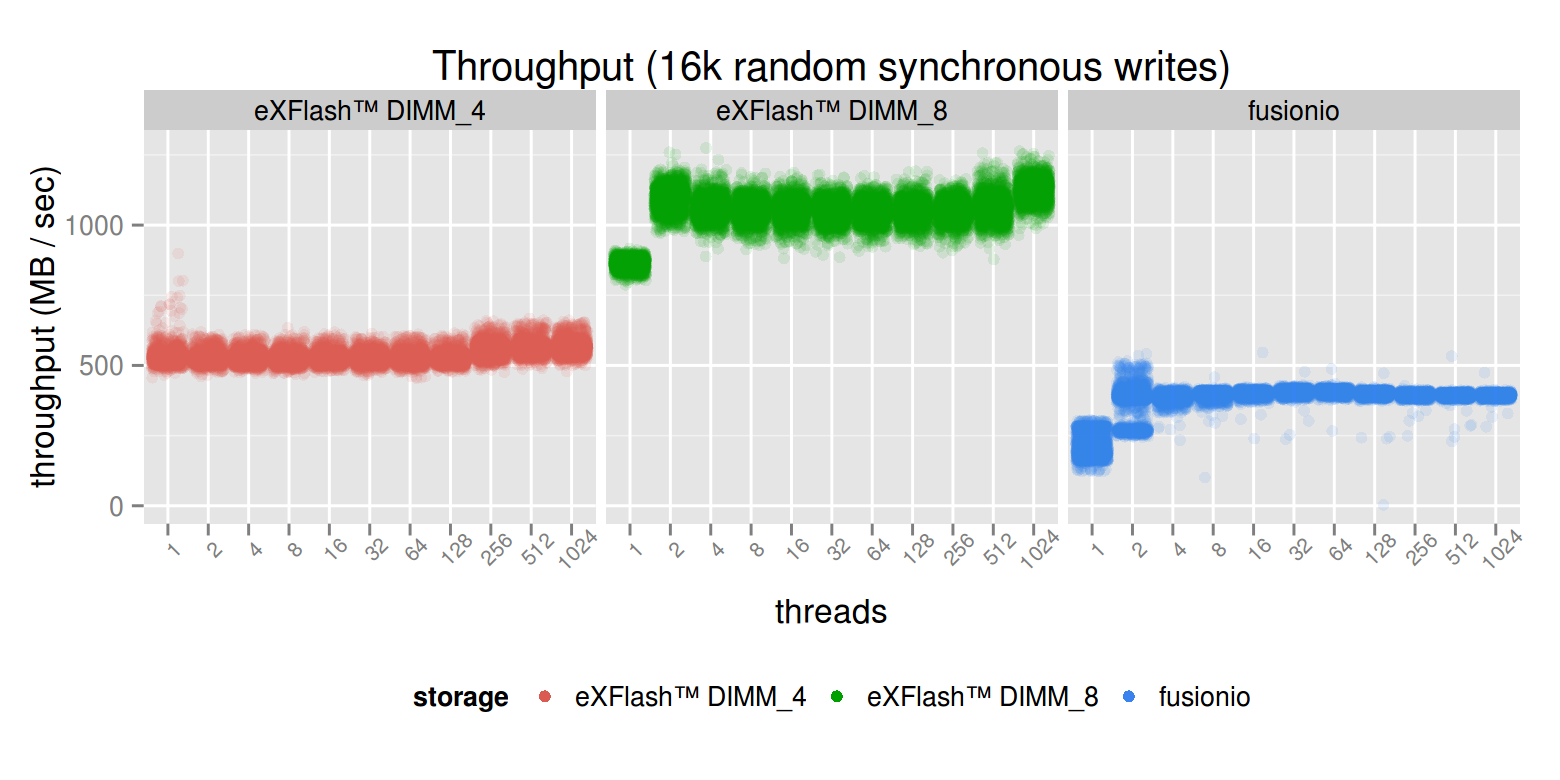
Because of caching mechanisms, we don’t need too much writer threads in order to utilize the devices. This makes sense, writes are easy to cache: after a write, the device can tell the operating system that the write is completed, when in reality it’s only completed later. In case of reads, this is different, when the application requests a block to read, the device can’t give the data to the application, but only read it later. Because of mechanisms like this, consistency is very important in case of write tests. The PCI-E device delivers the most consistent, but the lowest throughput. The reason for this is NUMA’s effect to the MCS performance. Because sysbench was allowed to use any CPU core, it may got lucky by hitting the DIMM which is in the CPU’s memory bank it’s currently running on, or may got unlucky, and the QPI was involved in getting the data. One case is not more rare than the other, hence we see the more wide bars on the graphs.
The latency is better in case of eXFlash DIMMs, but not as much as in case of isolated reads. It only seems to be slightly less in case of eXFlash DIMM_4, so let’s do a similar zoom here as we did in case of writes.
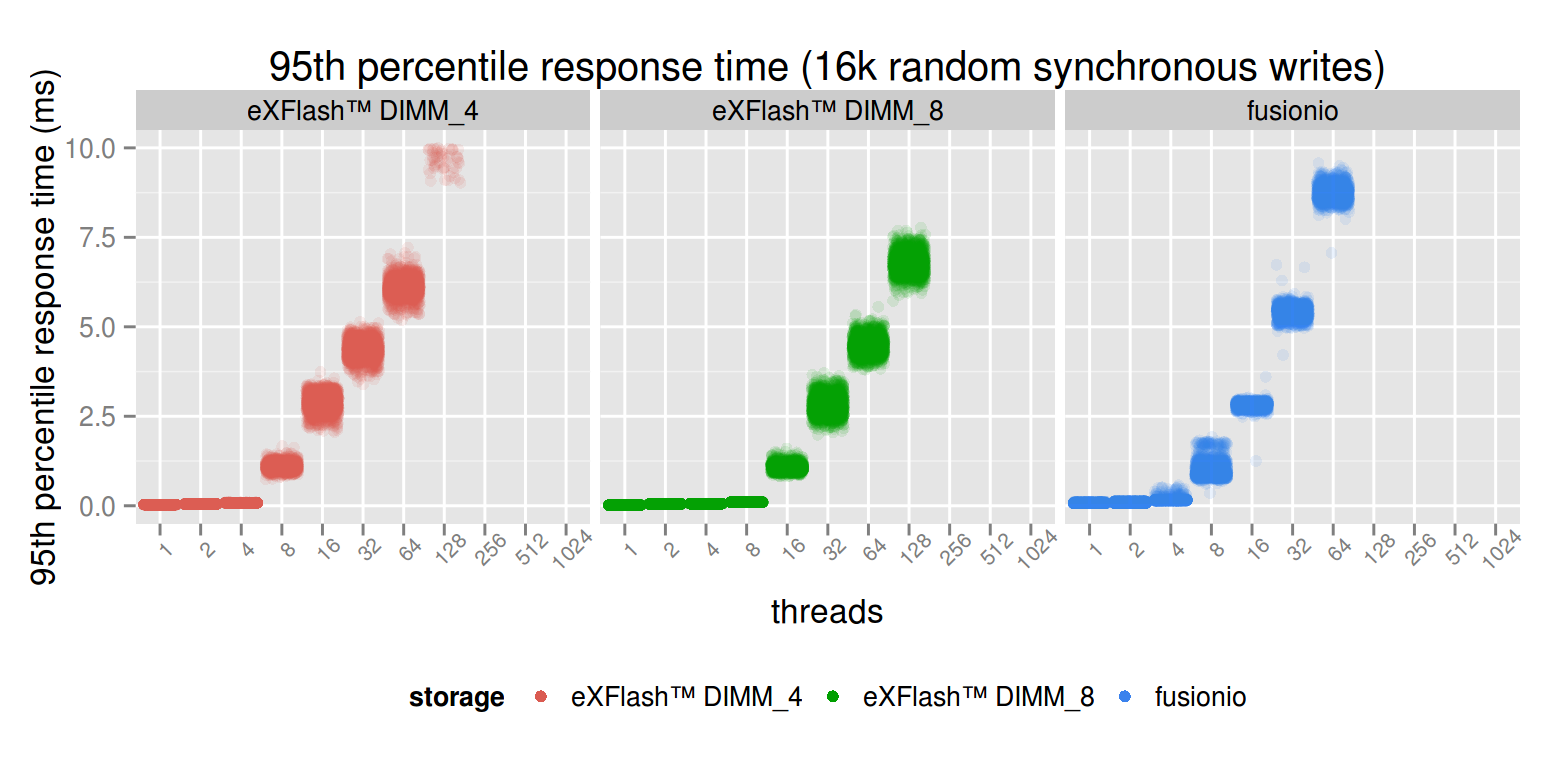
It’s visible on the graph that in case of lower concurrency, the eXFlash DIMM_4 and fusionio measurement is roughly the same, but as the workload becomes more parallel, the eXFlash DIMM will degrade more gradually. This more gradual degradation is also present in the eXFlash DIMM_8 case, but it starts to degrade later.
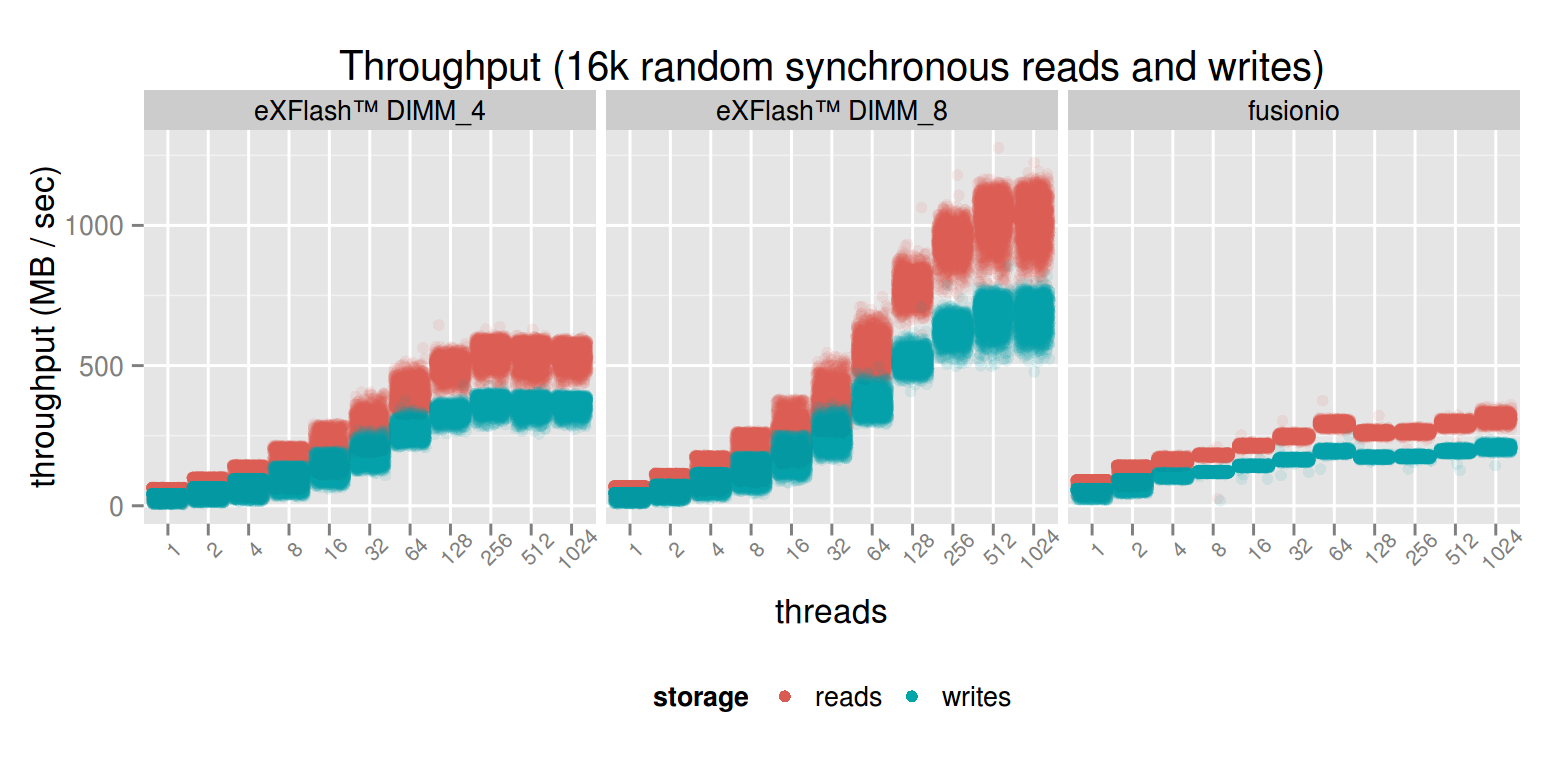
In case of mixed throughput, the PCI-E device similarly shows more consistent, but lower performance. Using 8 DIMMs means a significant performance boost: the 1.1 GB/s reads and 750 MB/s writes like in case of asynchronous IO is doable with 256 threads and above.
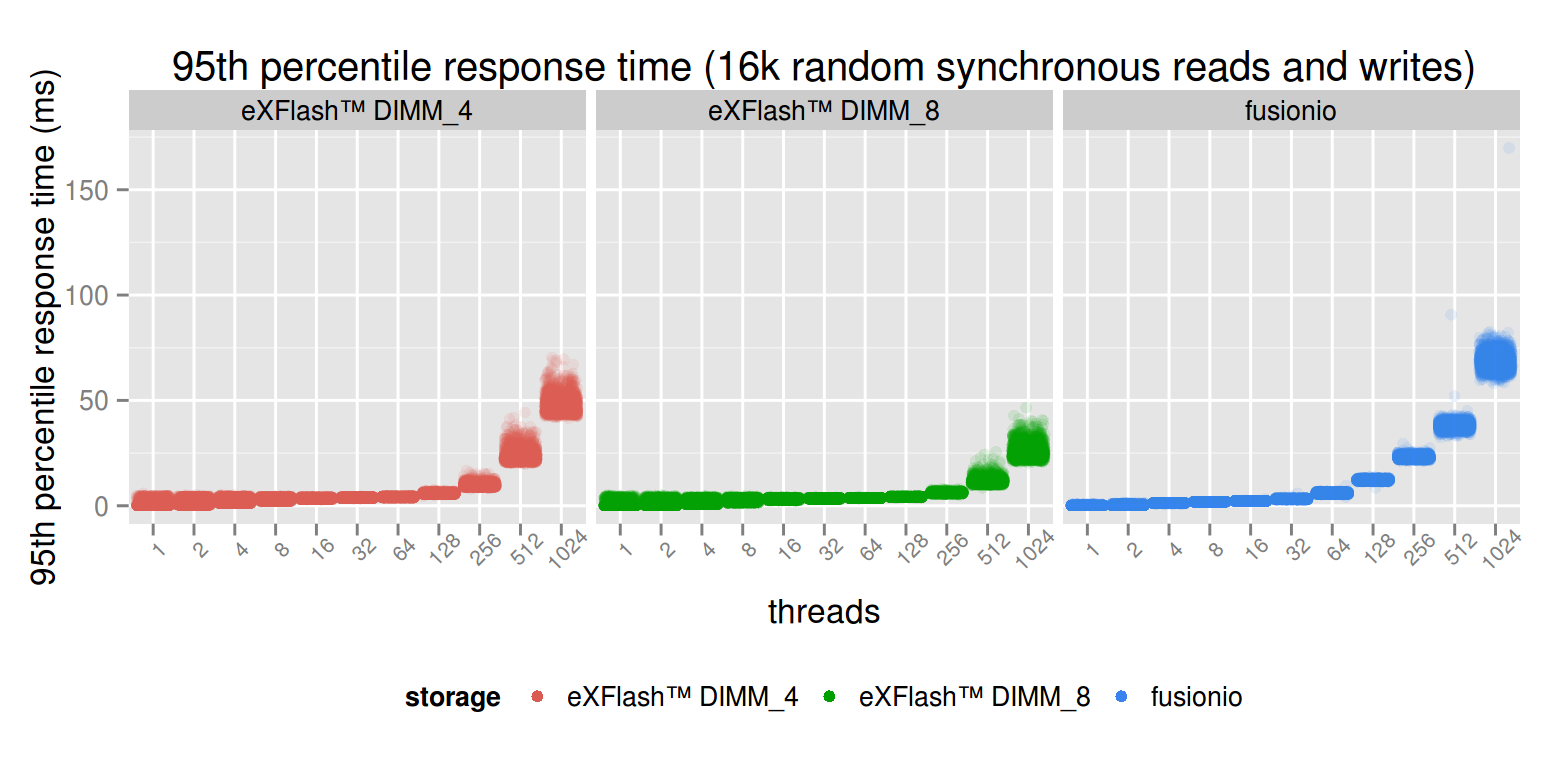
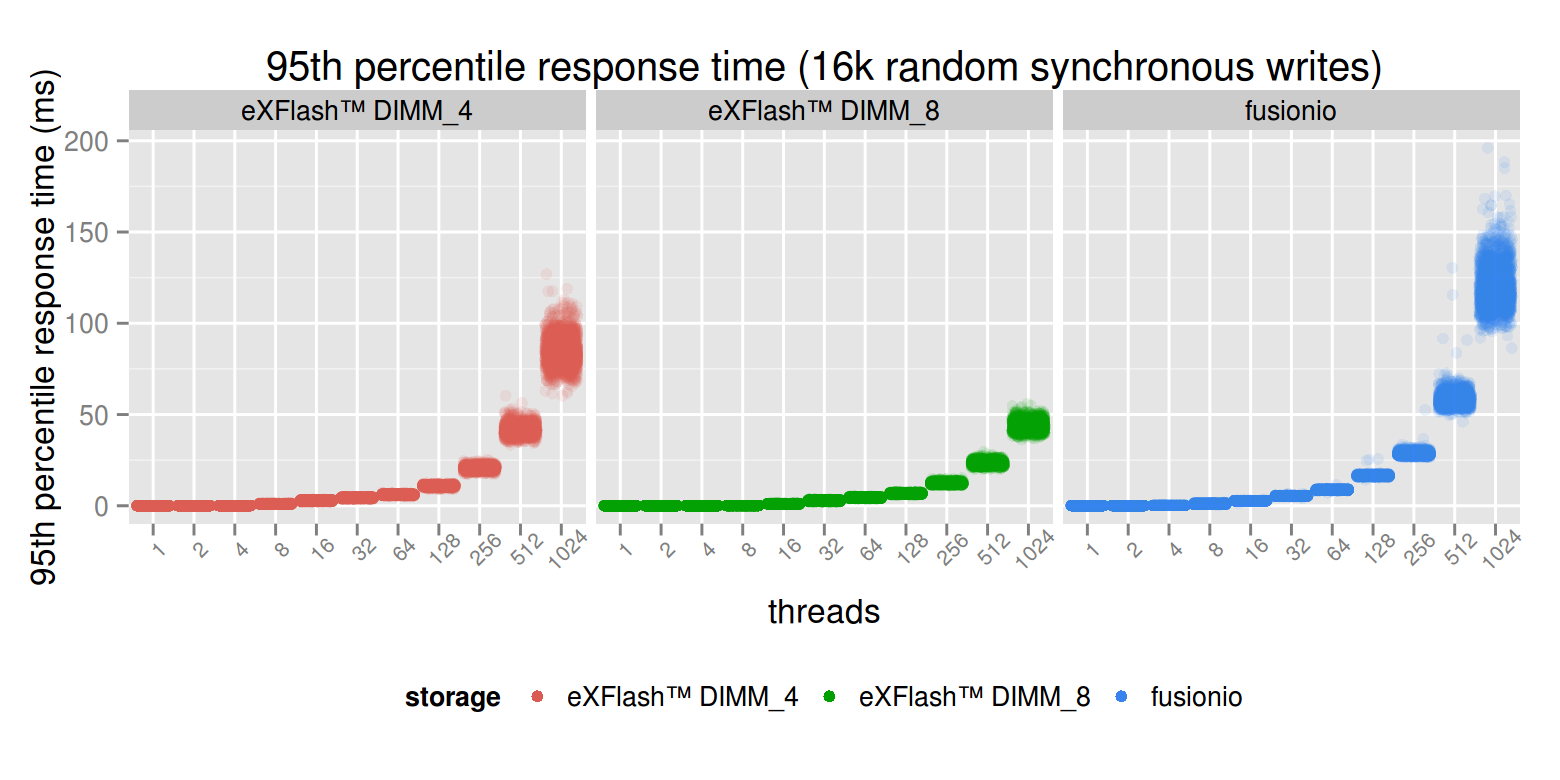
Similarly to the previous cases, the response times are slightly better in case of using eXFlash DIMMs. Because the latency is quite high in case of 1024 threads in each case, a similar zoom like previous cases will show more details.
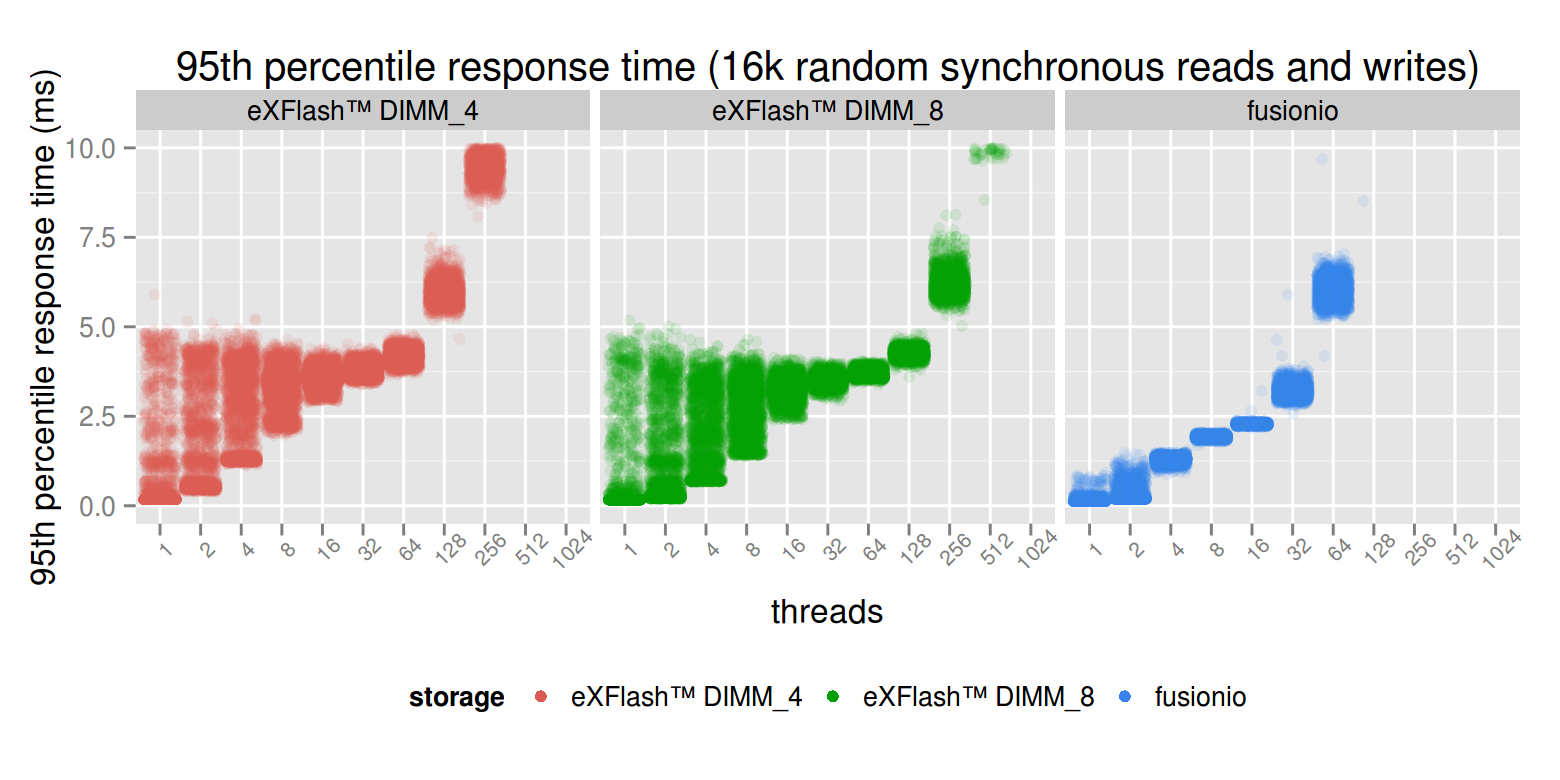
At a low concurrency, the latency is better on the PCI-E device, at least the maximum latency. We can see some fluctuation in case of the eXFlash DIMMs. The reason for that the NUMA, on a single thread, which CPU has the storage the benchmark is accessing matters a lot. As the concurrency gets higher, the response time degrades in case of the flash device, but in the case of eXFlash DIMMs, the maximum remains the same and the response time becomes more consistent. At 32 threads, the mean latency of the devices are very close, with the PCI-E device being slightly better. From there, the eXFlash DIMMs are degrading more gracefully.
Overall, I am impressed, especially with the read latency at massive parallelism. So far this is the fastest MLC device we have tested. I would be curious how would 16 or 32 DIMMs would perform in a machine which has enough sockets and memory channels for that kind of configuration. Like we moved one step closer to the CPU with PCI-E based flash, MCS is one step closer to the CPU compared to the PCI-E based flash.
Resources
RELATED POSTS





Was free space 50% for all devices? If yes, then why did you leave so much free space? That is a lot of overprovisioning.
In the third code listing there seems to be a typo:
mdadm –create /dec/md0
should probably be /dev/md0
I suppose this only works with specific IBM Servers?
‘@Mark Callaghan: Flash devices have very different cell (≃ block) allocation algorithms than spinning disks; a lot of them tend to slow down noticeably the fuller they get.
Half is indeed rather wide on the safe side of things, but it ensures that performance remains optimal, which is what this particular benchmark was interested in.
Limiting the device to half full doubles the real cost/GB. I doubt many customers are willing to do that. Results under more realistic conditions would be much more relevant to the MySQL community.
Second “In case of 4 devices” seems like copypaste typo 🙂
It is probably good to do 2 runs of a bench mark like this.
One at 50% utilization like this which measures data path efficiency without stressing the flash management.
Then another bench mark at device 100% utilization (still likely only 80-90% of real flash capacity) that would look at the flash management efficiency on top of the data path load.
A couple of questions:
1. Are these fresh out of the box (FOB) drives? Are these pre-conditioned so that Garbage Collection is kicked off ?
2. Why is the application response time in milli-seconds for the ex Flash DIMM ? Shouldn’t this be in the microseconds on the DIMM bus since no software is involved on the ex Flash DIMM?
Also, a good data-point would be to run with 2 Fusion-IO drives in parallel to understand if PCIe performance scales linearly just like the DIMM slots.
I just purchased an IBM 3850 X6 system with 4 400GB exFlash DIMMS in the system..
I installed VMware in drives 0 and 1 of the back plane (RAID 1) and then after registering the unit and going over some VMware configuration I was ready to install the proper driver to see the new storage DIMMs and after I installed and rebooted, I noticed nothing happened.. I tried different VMware versions (the ones compatible supposly with exFlash DIMMs) and I just don;t see the new storage, sometimes all I get is a storage adapter that was added after installing the Diablo driver 1.2 but that’s it.
Now, I got on the horn with VMware and after talking to them and they had me re-installed ESXi 5.5 U2 for the 5th time I just got the same results and they said the actual units are not installed.. “I saw them with my own eyes”
I know I’m probably missing a simple step but if you guys know of any similar problem can you please help me, I honestly don’t know where else to loo for help..
Thanks for your help.
Bob
Bob,
The drivers are supported by Diablo and we’ve worked closely with both IBM and VMware to certify those drivers in the system you have (as well as additional systems from IBM). We can help you with your issue. Please send us your contact information and basic configuration information here:
http://www.diablo-technologies.com/contact/#form
We can provide you with support very quickly.
Thanks,
Diablo Support Team
Sorry for the late answer, thanks for noticing the typos, I corrected them.
@Mark Callaghan: I did measurements for performance in function of disk space when I was using 8 dimms, I thought even this post quite lengthy in this form, and readers will get graph poisoning:). I chose 50% utilization because I measured performance from 20-80% utilization in 10% steps. What I found if that going from 20% to 50% the performance drops by 11-12% from the 20% case, from 50 to 80, it’s again a 11-12% drop from the original 20% baseline. This is fairly normal with these type of devices. I chose 50% so it’s somewhere in the middle, in order to show maximum possible performance, 20% is a better fill ratio.
Is this eXFlash linux driver code available ? Where can I find?
Sam – you can get a Linux driver by requesting it at our Support site at Diablo-technologies.com
thanks