
![]()
Dolphin and Elephant: an Introduction
This post is intended for MySQL DBAs or Sysadmins who need to start using Apache Hadoop and want to integrate those 2 solutions. In this post I will cover some basic information about the Hadoop, focusing on Hive as well as MySQL and Hadoop/Hive integration.
First of all, if you were dealing with MySQL or any other relational database most of your professional life (like I was), Hadoop may look different. Very different. Apparently, Hadoop is the opposite to any relational database. Unlike the database where we have a set of tables and indexes, Hadoop works with a set of text files. And… there are no indexes at all. And yes, this may be shocking, but all scans are sequential (full “table” scans in MySQL terms).
So, when does Hadoop makes sense?
First, Hadoop is great if you need to store huge amounts of data (we are talking about Petabytes now) and those data does not require real-time (milliseconds) response time. Hadoop works as a cluster of nodes (similar to MySQL Cluster) and all data are spread across the cluster (with redundancy), so it provides both high availability (if implemented correctly) and scalability. The data retrieval process (map/reduce) is a parallel process, so the more data nodes you will add to Hadoop the faster the process will be.
Second, Hadoop may be very helpful if you need to store your historical data for a long period of time. For example: store the online orders for the last 3 years in MySQL and store all orders (including those mail and phone orders since 1986 in Hadoop for trend analysis and historical purposes).
The next step after installing and configuring Hadoop is to implement a data flow between Hadoop and MySQL. If you have an OLTP system based on MySQL and you will want to use Hadoop for data analysis (data science) you may want to add a constant data flow between Hadoop and MySQL. For example, one may want to implement a data archiving, where old data is not deleted but rather placed into Hadoop and will be available for further analysis. There are 2 major ways of doing it:
Using Apache Sqoop for MySQL and Hadoop integration
Apache Sqoop can be run from a cronjob to get the data from MySQL and load it into Hadoop. Apache Hive is probably the best way to store data in Hadoop as it uses a table concept and has a SQL-like language, HiveQL. Here is how we can import the whole table from MySQL to Hive:
|
1 |
$ sqoop import --connect jdbc:mysql://mysql_host/db_name --table ORDERS --hive-import |
If you do not have a BLOBs or TEXTs in your table you can use “–direct” option which will probably be faster (it will use mysqldump). Another useful option is “–default-character-set”, for example for utf8 one can use “–default-character-set=utf8”. “–verify” option will help to check for data integrity.
To constantly import only the new rows from the table we can use the option “–where “. For example:
|
1 |
$ sqoop import --connect jdbc:mysql://mysql_host/db_name --table ORDERS --hive-import --where "order_date > '2013-07-01'" |
The following picture illustrates the process:
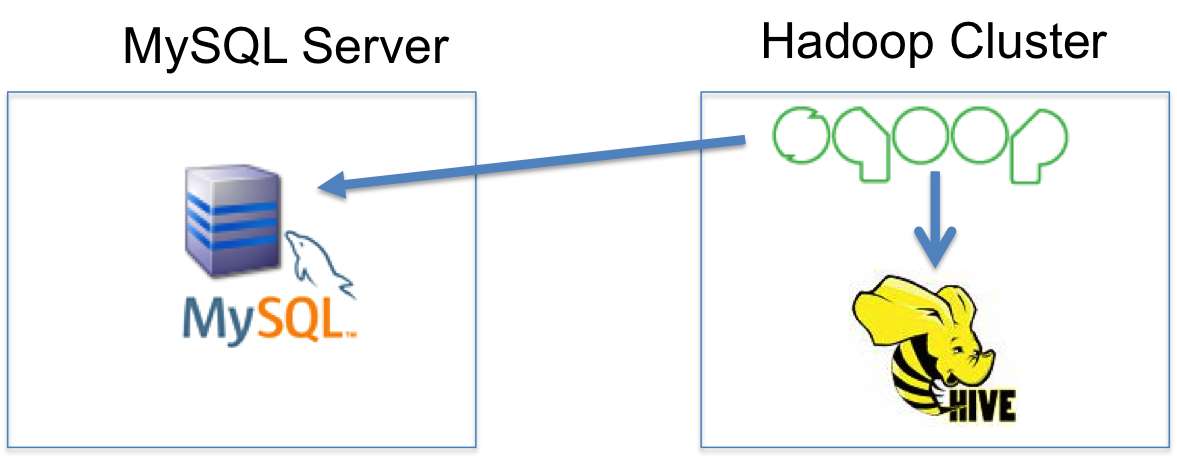
Using MySQL Applier for Hadoop
Sqoop is great if you need to perform a “batch” import. For realtime data integration, we can use MySQL Applier for Hadoop. With the MySQL applier, Hadoop / Hive will be integrated as if it is an additional MySQL slave. MySQL Applier will read binlog events from the MySQL and “apply” those to our Hive table.
The following picture illustrates this process:
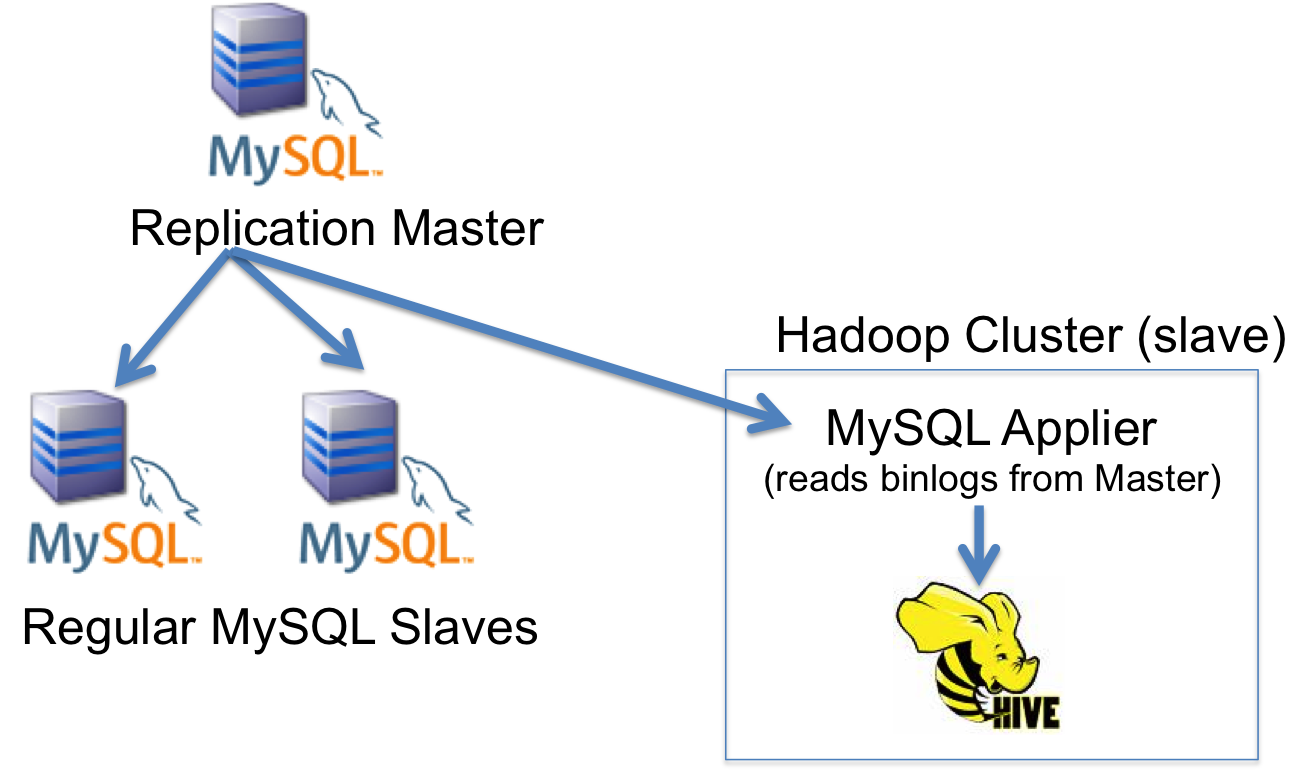
Conclusion
In this post, I have shown the ways to integrate MySQL and Hadoop (the big picture). In the subsequent post, I will show how to implement a data archiving with MySQL using Hadoop/Hive as a target.





I am not sure if mysql-hadoop-applier is mature enough to recommend using it.
While I am somewhat confident that it can handle INSERTs, I do not know how well it does on UPDATE/DELETEs.
So it is dependant on how you use your database.
I don’t think it does support deletes and updates. The point of hadoop is to throw everything in as an insert and work with the data later. It’s not there for consistency.
From the MySQL Applier for Hadoop doc:
“It connects to the MySQL master to read the binary log and then:
Fetches the row insert events occurring on the master”
True said Jonathan and Marc !
It is really good if it gets martured , and its quite interesting with the future of this project in terms of how it handles the updates as there is no update feature with underlying Hive/HDFS blocks !
If its really gets matured in terms of updates/deletes , it will removes many layers of critical workflows where sqoop involved !!
Sandeep.Bodla
Good Work
is there a link for the followup post?
Is there any other way to get answer like this? I tried with out success. Any way thanks for your help.
I learned a lot from Besant Technologies in my college days. They are the Best Hadoop Training Institute in Chennai.
I test MySQL Applier and Tungsten to do same tests.
I guess tungsten has a more mature product for real time loading,but if MySQL Applier has more testing i guess is more lightweight
hive in the since not working delete,query