
Some time ago we at Percona were approached by ScaleFlux Inc to benchmark their latest hardware appliance, the CSD 2000 Drive, which is a next-generation SSD computational storage drive. It goes without saying that a truly relevant report requires us to be as honest and as forthright as possible. In other words, my mission was to, ahem, see what kind of mayhem I could cause.
Benchmarking is a bit like cooking; it requires key ingredients, strict adherence to following a set of instructions, mixing the ingredients together, and a bit of heat to make it all happen. In this case, the ingredients include the Linux OS running Ubuntu 18.04 on both the database and the bench-marking hosts, PostgreSQL version 12, SysBench the modular, cross-platform, and multi-threaded benchmark tool, and a comparable, competing appliance i.e. the Intel DC P4610 series drive. The two appliances are mounted as partitions respectively both using the same type of file system.
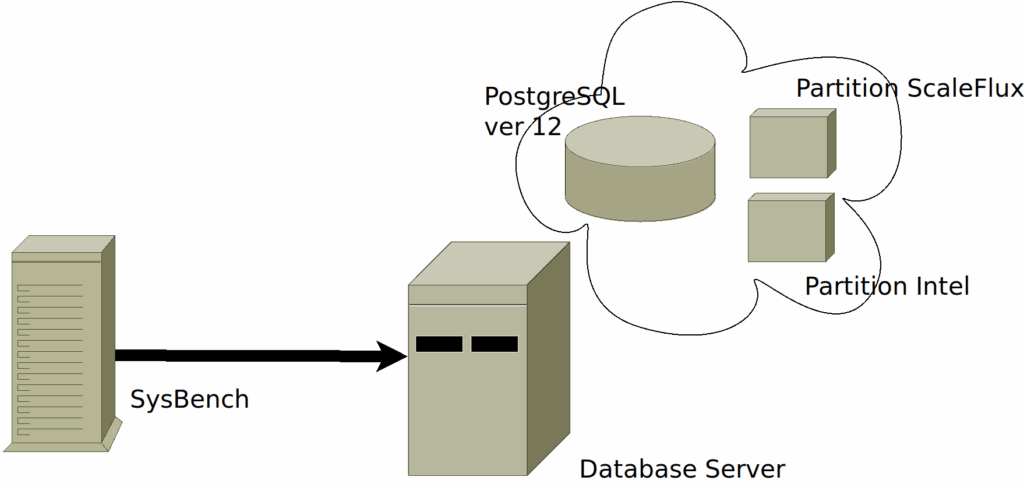
Once the environment is ready, the next step involves declaring and implementing the bench-marking rules which consist of various types of DML and DDL activity. Keeping in mind that apart from the classic OLAP vs OLTP modes of database processing, executing a benchmark that closely follows real production activities can be problematic. Quite often, when pushing a system to its full capacity, one can say that all production systems are to some extent unique. Therefore, for our purposes, we used the testing regime SysBench offers by default.
Once the system was ready, loading started out slow and gentle. The idea was to develop a baseline for the various types of activity and Postgres runtime conditions. Then, the bench-marking intensity was gradually increased to the point where we eventually started getting interesting results.
Needless to say, it took quite a bit of time running the various permutations, double-checking our numbers, graphing the data, and then after all that, interpreting the output. I’m not going to go into any great detailing the analysis itself. Instead, I encourage you to look at the whitepaper itself.
So after all this effort, what was the takeaway?
There are two key observations that I’d like to share:
Finally, one last item… I didn’t mention it but we also benchmarked MySQL for ScaleFlux. The results were pretty remarkable. It’s worth your while to have a look at that one too.
ScaleFlux White Papers:
Resources
RELATED POSTS




