
The expected growth of ARM processors in data centers has been a hot topic for discussion for quite some time, and we were curious to see how it performs with PostgreSQL. The general availability of ARM-based servers for testing and evaluation was a major obstacle. The icebreaker was when AWS announced their ARM-based processors offering in their cloud in 2018. But we couldn’t see much excitement immediately, as many considered it is more “experimental” stuff. We were also cautious about recommending it for critical use and never gave enough effort in evaluating it. But when the second generation of Graviton2 based instances was announced in May 2020, we wanted to seriously consider. We decided to take an independent look at the price/performance of the new instances from the standpoint of running PostgreSQL.
Important: Note that while it’s tempting to call this comparison of PostgreSQL on x86 vs arm, that would not be correct. These tests compare PostgreSQL on two virtual cloud instances, and that includes way more moving parts than just a CPU. We’re primarily focusing on the price-performance of two particular AWS EC2 instances based on two different architectures.
For this test, we picked two similar instances. One is the older m5d.8xlarge, and the other is a new Graviton2-based m6gd.8xlarge. Both instances come with local “ephemeral” storage that we’ll be using here. Using very fast local drives should help expose differences in other parts of the system and avoid testing cloud storage. The instances are not perfectly identical, as you’ll see below, but are close enough to be considered same grade. We used Ubuntu 20.04 AMI and PostgreSQL 13.1 from pgdg repo. We performed tests with small (in-memory) and large (io-bound) database sizes.
Specifications and On-Demand pricing of the instances as per the AWS Pricing Information for Linux in the Northern Virginia region. With the currently listed prices, m6gd.8xlarge is 25% cheaper.
|
1 2 3 4 5 |
Instance : m6gd.8xlarge Virtual CPUs : 32 RAM : 128 GiB Storage : 1 x 1900 NVMe SSD (1.9 TiB) Price : $1.4464 per Hour |
|
1 2 3 4 5 |
Instance : m5d.8xlarge Virtual CPUs : 32 RAM : 128 GiB Storage : 2 x 600 NVMe SSD (1.2 TiB) Price : $1.808 per Hour |
We selected Ubuntu 20.04.1 LTS AMIs for the instances and didn’t change anything on the OS side. On the m5d.8xlarge instance, two local NVMe drives were unified in a single raid0 device. PostgreSQL was installed using .deb packages available from the PGDG repository.
The PostgreSQL version string shows confirm the OS architecture
|
1 2 3 4 5 |
postgres=# select version(); version ---------------------------------------------------------------------------------------------------------------------------------------- PostgreSQL 13.1 (Ubuntu 13.1-1.pgdg20.04+1) on aarch64-unknown-linux-gnu, compiled by gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0, 64-bit (1 row) |
** aarch64 stands for 64-bit ARM architecture
The following PostgreSQL configuration was used for testing.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
max_connections = '200' shared_buffers = '32GB' checkpoint_timeout = '1h' max_wal_size = '96GB' checkpoint_completion_target = '0.9' archive_mode = 'on' archive_command = '/bin/true' random_page_cost = '1.0' effective_cache_size = '80GB' maintenance_work_mem = '2GB' autovacuum_vacuum_scale_factor = '0.4' bgwriter_lru_maxpages = '1000' bgwriter_lru_multiplier = '10.0' wal_compression = 'ON' log_checkpoints = 'ON' log_autovacuum_min_duration = '0' |
First, a preliminary round of tests is done using pgbench, the micro-benchmarking tool available with PostgreSQL. This allows us to test with a different combination of a number of clients and jobs like:
|
1 |
pgbench -c 16 -j 16 -T 600 -r |
Where 16 client connections and 16 pgbench jobs feeding the client connections are used.
The default load that
pgbench creates is a tpcb-like Read-write load. We used the same on a PostgreSQL instance which doesn’t have checksum enabled.
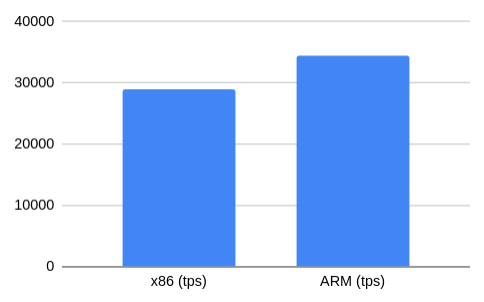
We could see a 19% performance gain on ARM.
| x86 (tps) | 28878 |
| ARM (tps) | 34409 |
We were curious whether the checksum calculation has any impact on Performance due to the architecture difference. if the PostgreSQL level checksum is enabled. PostgreSQL 12 onwards, the checksum can be enabled using pg_checksum utility as follows:
|
1 |
pg_checksums -e -D $PGDATA |
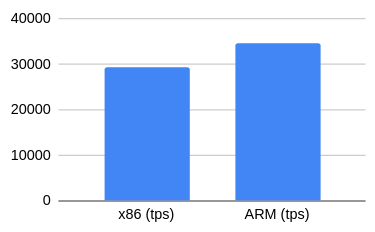
| x86 (tps) | 29402 |
| ARM (tps) | 34701 |
To our surprise, the results were marginally better! Since the difference is around just 1.7%, we consider it as a noise. At least we feel that it is ok to conclude that enabling checksum doesn’t have any noticeable performance degradation on these modern processors.
Read-only loads are expected to be CPU-centric. Since we selected a database size that fully fits into memory, we could eliminate IO related overheads.
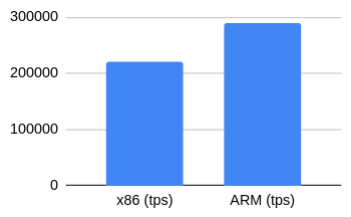
| x86 (tps) | 221436.05 |
| ARM (tps) | 288867.44 |
The results showed a 30% gain in tps for the ARM than the x86 instance.
We wanted to check whether we could observe any tps change if we have checksum enabled when the load becomes purely CPU centric.
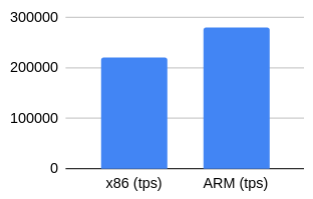
| x86 (tps) | 221144.3858 |
| ARM (tps) | 279753.1082 |
The results were very close to the previous one, with 26.5% gains.
In pgbench tests, we observed that as the load becomes CPU centric, the difference in performance increases. We couldn’t observe any performance degradation with checksum.
PostgreSQL calculates and writes checksum for pages when they are written out and read in the buffer pool. In addition, hint bits are always logged when checksums are enabled, increasing the WAL IO pressure. To correctly validate the overall checksum overhead, we would need longer and larger testing, similar to once we did with sysbench-tpcc.
We decided to perform more detailed tests using sysbench-tpcc. We were mainly interested in the case where the database fits into memory. On a side note, while PostgreSQL on the arm server showed no issues, sysbench was much more finicky compared to the x86 one.
Each round of testing consisted of a few steps:
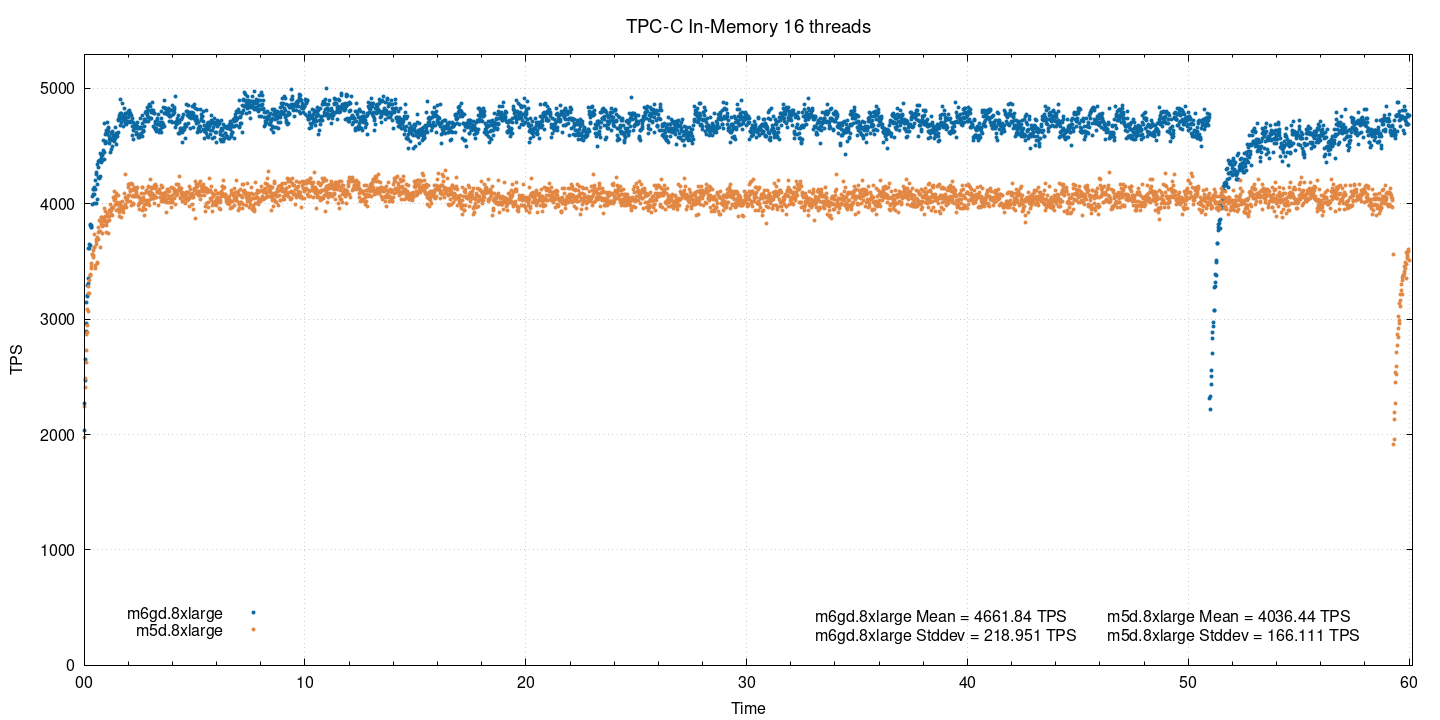
With this moderate load, the ARM instance shows around 15.5% better performance than the x86 instance. Here and after, the percentage difference is based on the mean tps value.
You might be wondering why there is a sudden drop in performance towards the end of the test. It is related to checkpointing with full_page_writes. Even though for in-memory testing we used pareto distribution, a considerable amount of pages is going to be written out after each checkpoint. In this case, the instance showing more performance triggered checkpoint by WAL earlier than its counterpart. These dips are going to be present across all tests performed.
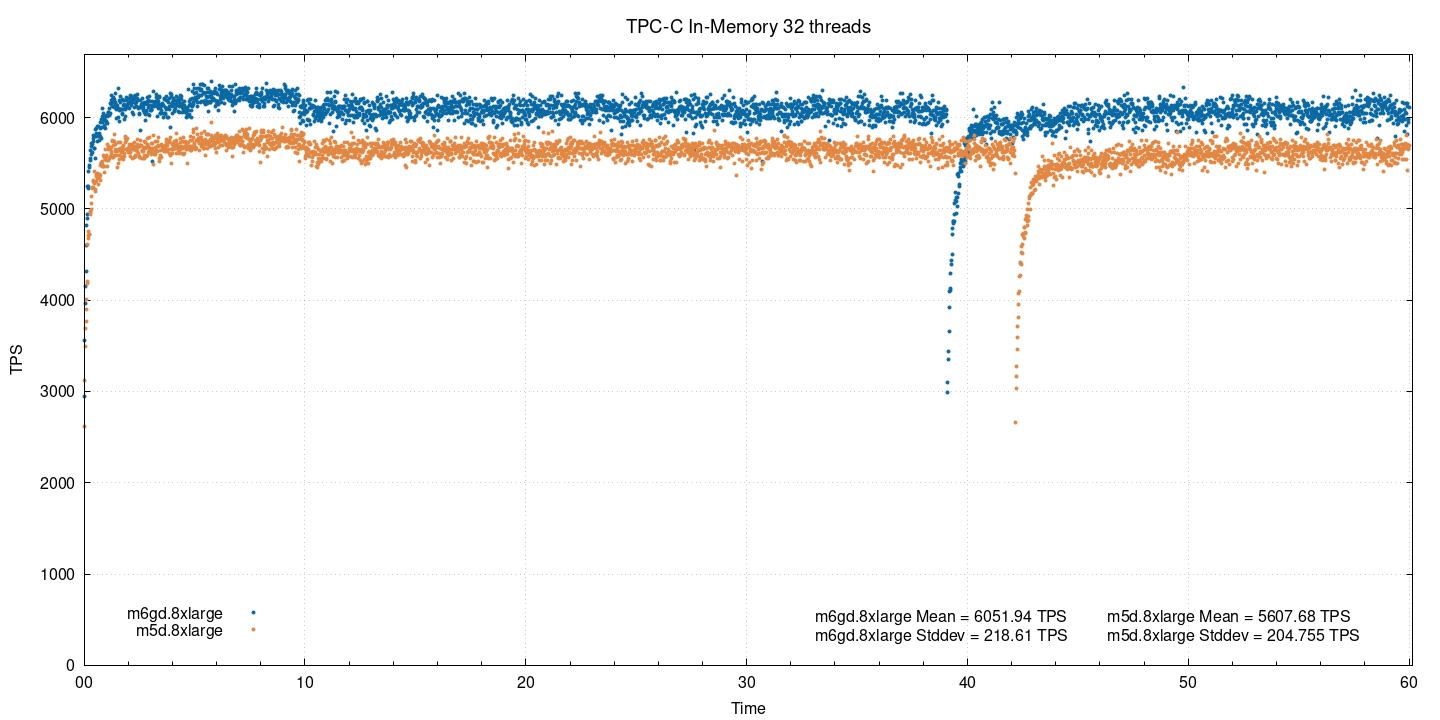
When concurrency increased to 32, the difference in performance reduced to nearly 8%.
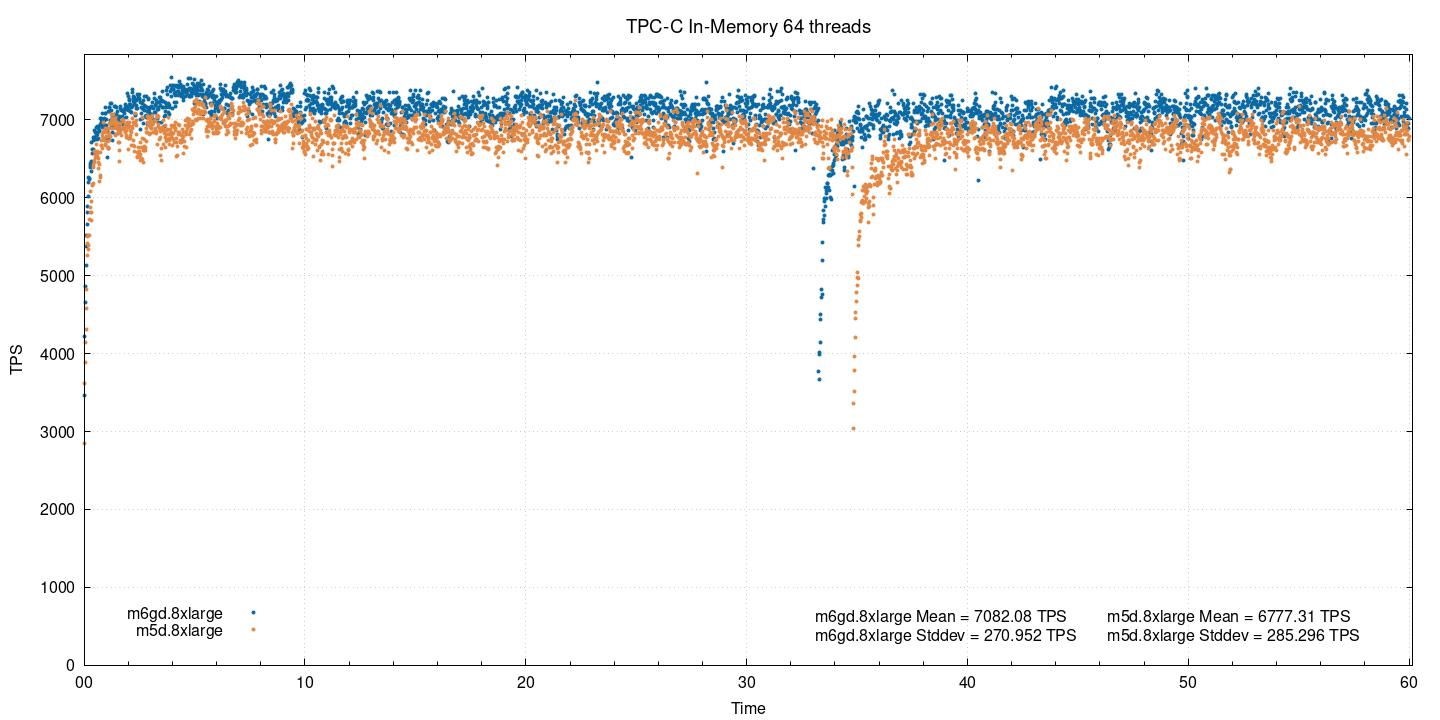
Pushing instances close to their saturation point (remember, both are 32-cpu instances), we see the difference reducing further to 4.5%.
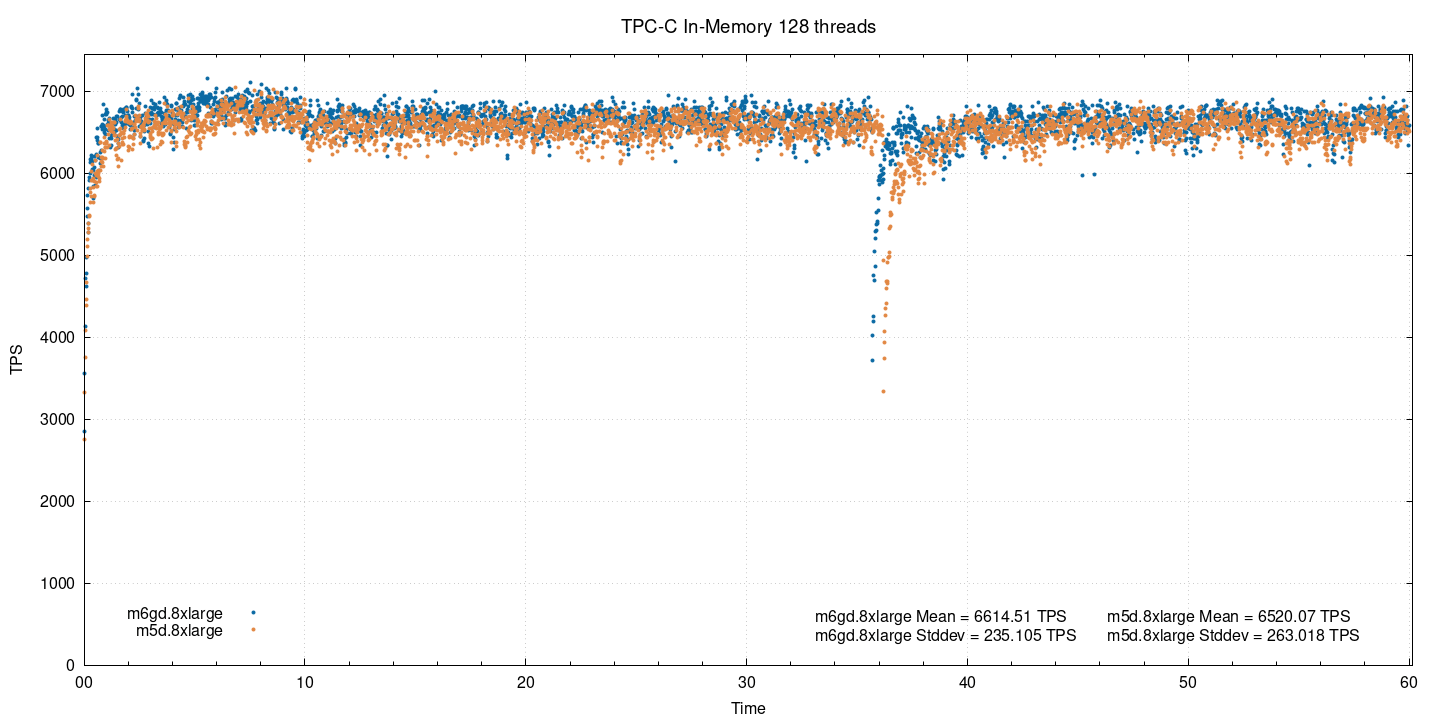
When both instances are past their saturation point, the difference in performance becomes negligible, although it’s still there at 1.4% Additionally, we could observe a 6-7% drop in throughput(tps) for ARM and a 4% drop for x86 when concurrency increased from 64 to 128 on these 32 vCPU machines.
Not everything we measured is favorable to the Graviton2-based instance. In the IO-bound tests (~200G dataset, 200 warehouses, uniform distribution), we saw less difference between the two instances, and at 64 and 128 threads, regular m5d instance performed better. You can see this on the combined plots below.
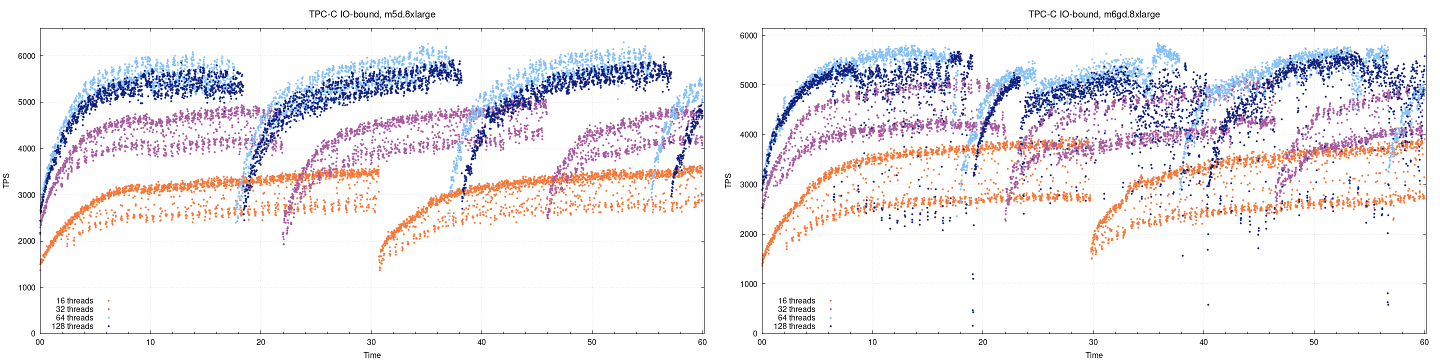
A possible reason for this, especially the significant meltdown at 128 threads for m6gd.8xlarge, is that it lacks the second drive that m5d.8xlarge has. There’s no perfectly comparable couple of instances available currently, so we consider this a fair comparison; each instance type has an advantage. More testing and profiling is necessary to correctly identify the cause, as we expected local drives to negligibly affect the tests. IO-bound testing with EBS can potentially be performed to try and remove the local drives from the equation.
More details of the test setup, results of the tests, scripts used, and data generated during the testing are available from this GitHub repo.
There were not many cases where the ARM instance becomes slower than the x86 instance in the tests we performed. The test results were consistent throughout the testing of the last couple of days. While ARM-based instance is 25 percent cheaper, it is able to show a 15-20% performance gain in most of the tests over the corresponding x86 based instances. So ARM-based instances are giving conclusively better price-performance in all aspects. We should expect more and more cloud providers to provide ARM-based instances in the future. Please let us know if you wish to see any different type of benchmark tests.
Resources
RELATED POSTS





One note for comparison:
m6gd.8xlarge Virtual CPUs : 32 – these are 32 physical cores
m5d.8xlarge Virtual CPUs : 32 – these are 32 virtual threads or 16 physical cores
Thus, you are comparing 32 physical cores against 16.
Considering that the competitors were selected on the basis of comparable value, the comparison can be considered quite correct.
But it should be borne in mind that with an equal number of cores, the solution with Graviton2 will be much slower.
Not sure this will necessarily be the case, though valid point anyway. One method could be to drop one instance size down for the Graviton2 variant, and disable SMT on the other: https://aws.amazon.com/blogs/compute/disabling-intel-hyper-threading-technology-on-amazon-linux/ (guide is for Amazon’s own distro, but same principle applies)
vCPU vs Physical core is valid but then given 2 different architectures it is difficult to get machines
with exact same configuration.
x86 has hyper threading, turbo mode, viz optimization and disabling them in favor on ARM (since arm doesn’t have it)
may not be right.
—————-
I would suggest we look at it from different perspective.
Let’s keep the cost constant (and other resources like storage and memory) and let’s allow the compute power to vary.
(ARM being cheaper will get more compute resources).
This would give a fair idea that for given cost how much more TPS/USD can ARM get back.
—————–
This model is tagged as #cpm (cost performance model) and is widely being used for mysql on arm evaluation.
You can read more about it here https://mysqlonarm.github.io/CPM/
Difference in cpu cache sizes of graviton and intel processors could be the reason of better performance on intel on io bound loads. I have observed similar results between amd and intel processors
I agree with Yuriy Safris.
Also, the measurements themselves without specifying the error are meaningless.
Example.
221436 + -30000 will already intersect with the value 288867 + -30000. That is, these 2 measurements will be almost equal to each other.
Compare against zen2 real cores, and ARM will loose.
Interesting analysis. I assume that EBS is the best way to keep storage the same. Even when using the same instance type with ephemeral storage across instance types I wonder if there is variance — are you getting a device for yourself, or sharing it with others, and possibly getting extra IO.
For the Intel has 16 cores vs ARM has 32 cores, in the end the comparison is about price/performance and if a real Intel core costs more than 2X a real ARM, then users will move to ARM. But this makes me wonder whether that price difference is a result of ARM being that much better, AWS marking up Intel cores, or AWS marking down ARM cores.
Yes, running with EBS would likely make this particular difference go away. However, EBS could also become a bottleneck, somewhat skewing the testing results. Cloudwatch data showed that m5d pushed more IOPS to its volumes, though, and I agree with an HN comment that having something like a comparative bonnie++ reports would make things clearer. Still, it’s an interesting caveat for m6gd family that it has fewer but larger local drives across the range. Instances with local drives are a pretty exotic setup for common databases anyway, I think, though they do make for an interesting way to make IO capacity much larger. Testing with EBS and running some tests with pgio (to get another viewpoint) are definitely among the missing pieces here. The 16/32 cores point is of course also very valid, although it’s difficult to get two really equal instances, unless it’s something like an m4->m5 evolutionary change. As for the pricing, I think it will be interesting to see offers of the other major cloud providers when (or if) they introduce ARM-based instances.
Thank you @Yuriy. Yes, This is more of a value comparison between 2 instance types : What we pay for and what we get. The point you raised is very significant for cloud instances : in m6gd.8xlarge instance, the vCPUs are in a 1 to 1 relation with physical cores. When there are more vCPUs than physical cores, the chance of “noisy neighbor” increases. As we know, some of the AWS instance types are notorious for noisy neighbor problems and unexpected CPU “steal”s in the wrong times.
Could you add m5ad.8xlarge or something like that to the comparsion?
Just completed a bank of internal testing. Was happy to see you are seeing a performance improvement with ARM based instances. I’m showing the slight opposite on smaller instances(large) using Pg 12.x. Perhaps the Pg folks saw this coming and have optimizations in 13, or you see greater dividends when you go larger. Either way, performance does drop off in the higher end of concurrency and when you do something other than simple straight joins. Price performance is still a hit, however. You’d be hard pressed to find a scenario where 25% price difference is justified on Intel IMO.
For higher concurrency there is active discussion on pgsql forum [1]. The said proposed patch helps improve scalability of #pgsqlonarm.
[if you have tested it on platform other than graviton, kunpeng, apple-m1 can you post your result with the said patch on the pgsql thread for more reference].
[1] https://www.postgresql.org/message-id/CAB10pyamDkTFWU_BVGeEVmkc8=EhgCjr6QBk02SCdJtKpHkdFw@mail.gmail.com
‘@Mark, It is an interesting finding that you see difference gains with smaller instances.
There are few reports that the code generation by different compilers are sub optimal for ARM processors at this stage. We should expect some performance gains as the compiler infrastructure improves. So more than PostgreSQL version I would expect change in performance due to compilers used, It is not just about PostgreSQL binaries but other libraries present in the OS aswell.
Hi, this is the default pgbench workload (TPC-B with simple query protocol). It is full of context switches and network calls and then do not really measure the CPU component. I tried to explain this here on an example: https://franckpachot.medium.com/do-you-know-what-you-are-measuring-with-pgbench-d8692a33e3d6 but probably.
A pgio or all plpgsql workload may give a better idea on the processor performance.
Hi Frank, a big fan of your work, and I’ve been following Kevin for a long time since I worked with Oracle databases. Yes, I read your blog post back when it was out, and while working on this test. It was one of the reasons I discarded pgbench for a more realistic sysbench-tpcc workload. While absolutely not perfect, it’s not exactly tpc-b either. Performing a round of testing with pgio (and using EBS for storage, for that matter, to nullify storage differences) is something I haven’t managed to do yet, but it’s definitely on my list.
I am also a fan of Frank’s work, and will read that pgbench post soon
Thank you Sergey and Mark 🙂 I’m currently comparing x86 and POWER platforms for PostgreSQL for a customer. The result really depends on what is tested. One is faster with pgio shared_buffers hits, the other when it is filesystem cache hits. And with pgbench, one faster with the “simple” protocol, the other with prepared statements. So if we want to know which one is better for the applications, the only answer is: it depends 😉 It would be very interesting to see if the Graviton2 shows general patterns in all cases.
I look forward to more interesting perf comparisons given the new diversity in CPU (x86 is joined by ARM, I haven’t been near a POWER server since forever, although I had a PowerPC Mac long ago).
It can be hard to do OSS on POWER given the lack of access to such HW. It seemed like IBM could have done more to promote that in their cloud.
Fortunately we have the OSUOSL that hosts HW for OSS projects, including ARM and POWER servers. I hope that HW is used by the PG community.
https://osuosl.org/services/