
Migrate to Percona software for MySQL – an open source, production-ready, and enterprise-grade MySQL alternative.

MariaDB 10.5 includes an S3 storage engine plugin based on Aria. Its main feature is the ability to move tables from local storage to S3 using ALTER TABLE, while still allowing access through standard SQL.
This is useful for low-cost data archiving. The S3 engine is read-only (no INSERT/UPDATE/DELETE), but table structure changes are allowed.
In this blog, we’ll explore implementation details and compare performance between local and S3-backed tables.
The S3 engine is alpha-level and not enabled by default. Enable it in the config:
|
1 2 |
[mysqld] plugin-maturity = alpha |
Configure S3 credentials:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[mysqld] server-id = 101 plugin-maturity = alpha log_error = /data/s3_testing_logs/mariadb.log port = 3310 s3=ON s3_access_key = xxxxxxxxxxxx s3_secret_key = yyyyyyyyyyyyyyyyyyyyyyy s3_bucket = mariabs3plugin s3_region = ap-south-1 s3_debug = ON |
Note: Credentials are stored in plaintext. Use restricted IAM credentials.
Restart MariaDB and install the plugin:
|
1 2 3 |
MariaDB [(none)]> install soname 'ha_s3'; MariaDB [(none)]> select * from information_schema.engines where engine = 's3'G |
Example table:
|
1 |
show create table percona_s3G |
Convert to S3:
|
1 |
alter table percona_s3 engine=s3; |
After conversion, only the .frm file remains locally. Data moves to S3:
|
1 |
aws s3 ls s3://mariabs3plugin/s3_test/percona_s3/ |
Note: Data and index are stored separately in S3.
|
1 |
select * from percona_s3; |
|
1 |
ERROR 1036 (HY000): Table 'percona_s3' is read only |
|
1 |
alter table percona_s3 add index idx_name (name); |
|
1 |
alter table percona_s3 modify column date_y timestamp; |
|
1 |
drop table percona_s3; |
Note: This removes data from S3 as well.
To modify data:
S3:
|
1 |
select count(*) from percona_perf_compare; |
Local:
|
1 |
select count(*) from percona_perf_compare; |
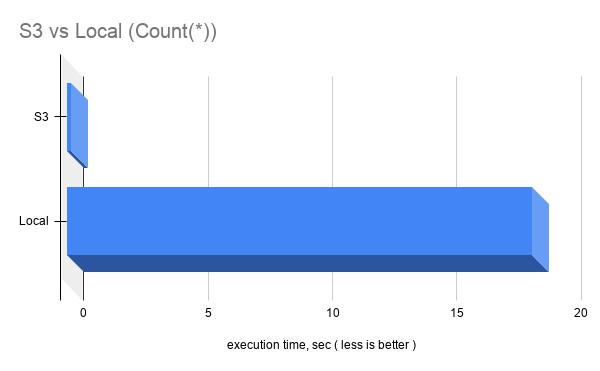
COUNT(*) is faster on S3, likely due to metadata usage similar to MyISAM.
S3:
|
1 |
select * from percona_perf_compare; |
Local:
|
1 |
select * from percona_perf_compare; |
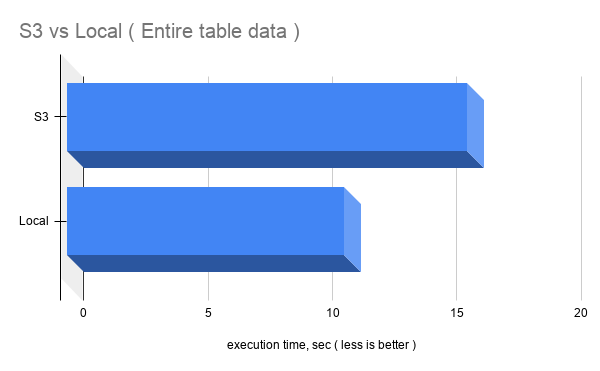
S3:
|
1 |
select * from percona_perf_compare where id in (7196399); |
Local:
|
1 |
select * from percona_perf_compare where id in (7196399); |
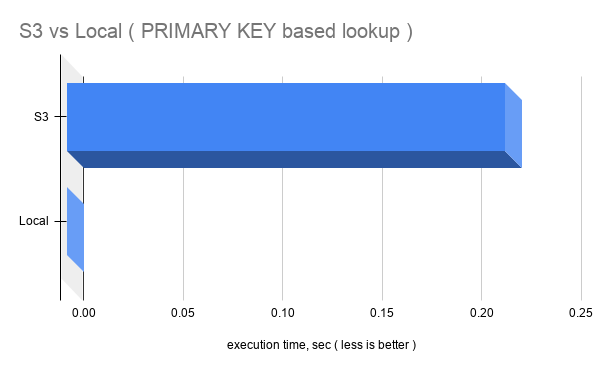
s3_block_sizeCOMPRESSION_ALGORITHM=zlibs3_pagecache_buffer_sizePerformance depends on:
Stay tuned for more on S3 engine compression.





Hi Sri, I had some issues using this plugin regarding the IAM policy owned by the IAM user.
The bucket is not visible in the AWS console or not listed by the CLI command s3api list-buckets.
I struggled then to clean up the environment, I couldn’t delete the bucket due to Access Denied.
Did you have the same issue?