
 Due to the immense generation of data, scalability has become one of the hottest topics in the field of databases. Scalability can be achieved horizontally or vertically. Vertical scalability means adding more resources/hardware to existing nodes to enhance the capability of the database to store and process more data, for example, adding a new process, memory, or disk to an existing node. Every DBMS engine improves the capability of vertical scalability by improving the locking/mutex mechanisms and the concurrency by which it can use the newly added resources more effectively. The database engines provide configuration parameters, which helps to utilize the available hardware resources more effectively.
Due to the immense generation of data, scalability has become one of the hottest topics in the field of databases. Scalability can be achieved horizontally or vertically. Vertical scalability means adding more resources/hardware to existing nodes to enhance the capability of the database to store and process more data, for example, adding a new process, memory, or disk to an existing node. Every DBMS engine improves the capability of vertical scalability by improving the locking/mutex mechanisms and the concurrency by which it can use the newly added resources more effectively. The database engines provide configuration parameters, which helps to utilize the available hardware resources more effectively.
Due to the cost of hardware and the limit to add the new hardware in the existing node, it is not always possible to add new hardware. Therefore, horizontal scalability is required, which means adding more nodes to existing network nodes instead of enhancing the capability of the existing node.
Contrary to vertical scalability, horizontal scalability is challenging to implement. It requires more development effort and requires more work to set up. PostgreSQL provides quite a rich feature set for both vertical scalability and horizontal scalability. It supports machines with multiple processors and a lot of memory and provides configuration parameters to manage the use of these resources. The new features of parallelism in PostgreSQL make the vertical scalability more prominent, but it is also not lacking horizontal scalability. Replication is the crucial pillar of horizontal scalability, and PostgreSQL supports unidirectional master-slave replication, which is enough for many use-cases.
Learn more about PostgreSQL backup strategies for an enterprise-grade environment.
Database Replication
Database replication replicates the data on other servers and stores it on more than one node. In that process, the database instance is transferred from one node to another node and an exact copy is made. Data replication is used to improve data availability, a key feature of HA. There can be a full database instance, or some frequently used or desired objects are replicated to another server. As replication provides the multiple consistent copies of the database, it not only provides high availability but also improves the performance.
Synchronous replication
There are two strategies while writing the data on disk, Synchronous, and Asynchronous. Synchronous replication means data is written to master and slave simultaneously, in other words, “Synchronous replication” means commit waits for write/flush on the remote side. Synchronous replication is used in the high-end transactional environment with instant failover requirements.
Asynchronous replication
Asynchronous means data is written to master first and then replicated to the slave. In the case of a crash, data loss can occur, but Asynchronous replication provides very little overhead and therefore it is acceptable in most cases. It does not overburden the master. The fail-over from primary to secondary takes a longer time than with synchronous replication.
In a nutshell, the main difference between Synchronous and Asynchronous is when data is written to master and slave.
Single Master Replication
Single master replication means data is allowed to be modified only on a single node, and these modifications are replicated to one or more nodes. The data update and insertion are only possible on the master node. In that case, applications require routing the traffic to master, which adds some complexity to the application. Because of single masters, there is no chance of conflicts. Most of the time single master replication is enough for the application because it is less complicated to configure and manage. But in some cases, single master replication is not enough and you need multi-master replication.

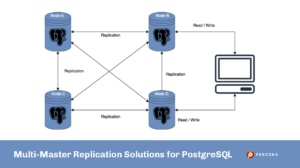
Multi-master replications mean there is more than one node that acts as master nodes. Data is replicated between nodes and updates and insertion can be possible on a group of master nodes. In that case, there are multiple copies of the data. The system is also responsible for resolving any conflicts that occur between concurrent changes. There are two main reasons to have a multiple master replication; one is HA, and the second is performance. In most cases, some nodes are dedicated to the intensive write operation, and some nodes are dedicated to some nodes or for failover.
Here are the pros and cons of multi-master replication
Pros:
Cons:
As we have already discussed, Single-Master replication is enough in most of the cases and highly recommended, but still, there are some cases where there is a requirement of Multi-Master replication. PostgreSQL has built-in single-master replication, but unfortunately, there is no multiple-master replication in mainline PostgreSQL. There are some Multimaster replication solutions available, some of these are in the form applications and some are PostgreSQL forks. These forks have their own small communities and are mostly managed by a single company, but not by the mainline PostgreSQL community.

There are multiple categories of these solutions, open-source/ closed source, priority, free, and paid.
Here are some key features of all the replications solutions
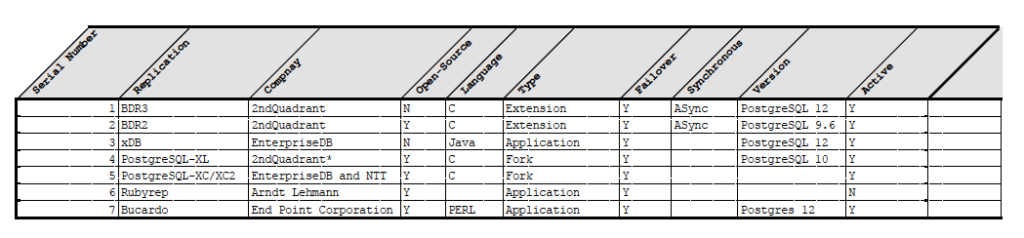
BDR is a multi-master replication solution, and it has different versions. Early versions of BDR are open-source but its latest version is closed-source. This solution is developed by 2ndQuadrant and one of the most elegant Multimaster solutions to date. BDR provides asynchronous multi-master logical replication. This is based on the PostgreSQL logical-decoding feature. Since BDR applies essentially replays the transaction on the other nodes, the replay operation can fail if there is a conflict between a transaction being applied and a transaction that was committed on the receiving node.
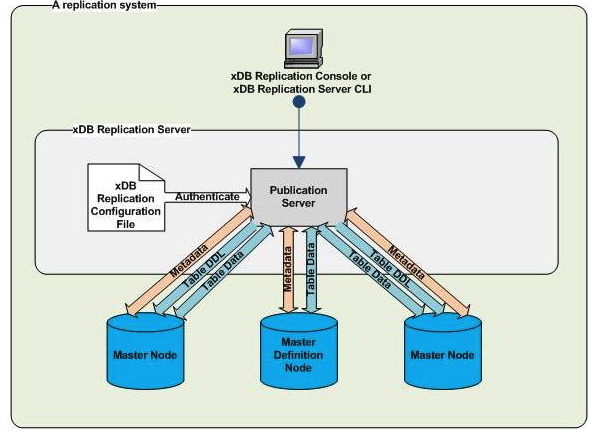
EnterpriseDB developed its own bi-direction replications solution in Java called xDB. It is based on their own protocol. Because it is a closed-source solution, no design information is known to the world.
PostgreSQL-XC is developed by EnterpriseDB and NTT. It is a synchronous replication solution. Postgres-XC is an open-source project to provide a write-scalable, synchronous, symmetric, and transparent PostgreSQL cluster solution. I have not seen much development in PostgreSQL-XC for many years from EnterpriseDB and NTT. Currently, Huawei is working on that. Some performance gain has been reported in the case of OLAP, but not suitable for TPS.
It is a fork of PostgreSQL-XC and currently supported by 2ndQuadrant. It is well behind Community PostgreSQL. As for as I know it based on PostgreSQL 10.6, which is not aligned with PostgreSQL latest version PostgreSQL-12. As we know it is based on PostgreSQL-XC, it is very good when we are talking about the OLAP, but not much suitable for Hight TPS.
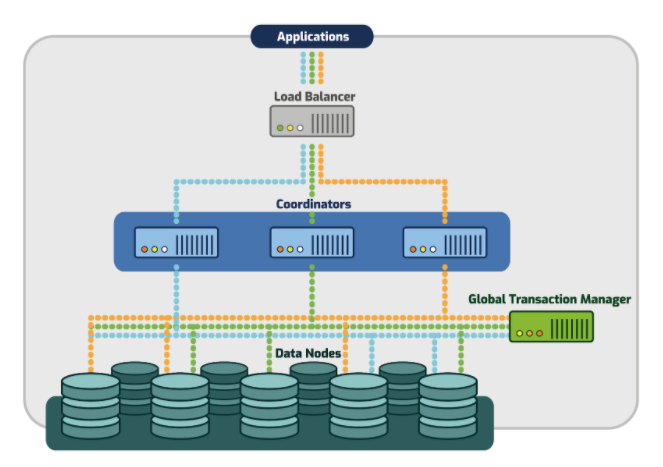
Note: All PostgreSQL XC/XC2/XL are considered as “PostgreSQL-derived software” which are not synchronized with the current development of PostgreSQL.
It is an asynchronous master-master replication developed by Arndt Lehmann. It claims the easiest configuration, setup, and works across platforms including windows. It always operates on two servers, which are referenced as “left” and “right” in Rubyrep terminology. So it is meaningful to call it a “2-master” setup rather than “multi-master”.
Note: – This project has not been active for the last three years, in terms of development.
Bucardo is a Trigger-based replication solution developed by Jon Jensen and Greg Sabino Mullane of End Point Corporation. Bucardo’s solution has been around for almost 20 years now and was originally designed as a “lazy” asynchronous solution that eventually replicates all changes. There is a Perl daemon that listens to NOTIFY requests and acts on them. Changes happening on tables are recorded in a table (bucardo_delta) and notifies the daemon. Daemon notifies the controller which spins up a “kid” to synchronize the table changes. If there is conflict, standard or custom conflict handlers are used to sort it out.
Conclusion
Most of the cases of single-master replication are enough, and it has been observed that people are configuring multi-master replication and over-complicating their design. It is highly recommended to design the system and try to avoid the multi-master replication and only use it where there is no way to design the system without that. There are two reasons: the first is it makes the system over-complex and hard to debug, and second, you will not get any support from the PostgreSQL community because there are no community-maintained multi-master replications available.
You’ve chosen PostgreSQL for its flexibility, performance, and cost savings—but even experienced IT leaders can hit avoidable pitfalls along the way. Here’s what to look out for.
Resources
RELATED POSTS





How about the PGPool-II?
Can it be used as multi-master solution?
http://www.pgpool.net
Yes, you can do that using PgPool-II replication.