
 Missing Piece: Failover of the Logical Replication Slot
Missing Piece: Failover of the Logical Replication SlotLogical decoding capability has existed in PostgreSQL for the last several versions, and a lot more functionalities are added over time. However, one of the very crucial functionalities is still missing in PostgreSQL, which prevents logical replication to be part of critical production environments where downstream expects the logical changes to be streamed over a database connection reliably – even after a high-availability failover.
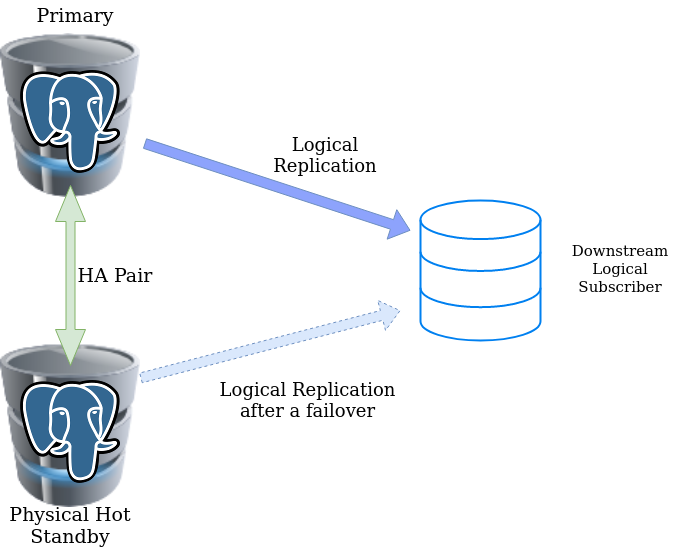
The root of the problem is that the Logical Replication Slot which exists on the primary is not available in a physical standby. Meanwhile, almost all PostgreSQL high-availability solutions depend on physical standbys. So if there is a failover, new primary (the old physical standby) won’t be aware of any slots which were existing with old primary. This leads to a completely broken logical replication (not continuous) downstream. We can create a fresh slot on the new primary and set up a fresh replication, but if the original logical replication was lagging, this leads to data loss.
This topic is not new. The historical PostgreSQL community discussion thread is available here. Craig Ringer blogged about it in 2016 following his efforts to provide a patch that should solve the problems. The idea was to write slot-related changes to the WAL logs so that the standby can recreate and maintain slots using the information passed through WAL logs.
Even though this approach of failover slot makes life easy for most of the scenarios, there were some notable objections because a lot more problems around it also needed to be addressed. Ideally, there should be a way to mark whether a slot is a “failover slot” so that the corresponding information will be written to WAL. But every standby which receives the WALs including the cascaded replicas will create and maintain slots. This will result in unnecessary overhead and WAL retention, maintaining old visions of system catalog, etc. There is no generic way to solve this for everyone.
Alternate paths to solve the problem also were proposed and discussed. This includes approaches on how to maintain the slot replication outside WAL. But that adds another set of complications. A big problem to solve is: how a user can specify/configure which node needs to be maintained for replication slots. Otherwise, it becomes the responsibility of the subscriber to pull slot information. Multiple options for transmitting the slot information from primary to standby, including separate replication channel, and pull and push methods, are also discussed in the community. However, every approach has its own complexity and edge cases. In addition to streaming replica/standbys, there could be archive standbys also. And, they generally don’t have proper methods to send the information back to primary which adds further limitations for available options.
Even though copying the state slot from the master to standby using an extension that keeps the slots on the replica reasonably up to date is good enough, having a complete solution with full integration with PostgreSQL becomes more complex than what we may initially think.
Since logical decoding is not supported on the physical standby side, the client/subscriber cannot create a logical replication slot on the standby, and standby has no provision to advance the slot. Even if the slot is made possible in physical standby, downstream subscribers can connect to it. The standby has no provision to preserve the catalog xmin on its primary by stopping it from cleaning it up.
Assume that we cut down the requirement to have the standby as a logical replication publisher. Then, if there is a method by which slot state can be copied from the master to the replica, ideally the basic failover can be served. A slot state valid on the primary side at a WAL LSN is valid on the standby side also because the physical standby is an exact binary copy of the primary.
Assume that we have a logical replication subscriber “sub” created as follows, from a downstream system:
|
1 2 3 |
postgres=# CREATE SUBSCRIPTION sub CONNECTION 'host=pg0 port=5432 dbname=postgres user=repluser password=highlysecret' PUBLICATION pub; <strong>NOTICE: created replication slot "sub" on publisher</strong> CREATE SUBSCRIPTION |
It creates a permanent (persistent) logical replication slot on the publisher.
PostgreSQL persists the state of the replication slot information in pg_replslot subdirectory within the data directory of the publisher.
|
1 2 3 4 5 6 |
$ ls -R pg_replslot/ pg_replslot/: sub pg_replslot/sub: state |
For a user, this is quite different from the publisher’s information which is part of the catalog.
As we can see, there is a directory with the name of the replication slot name “sub” and a file with the name “state” which holds the replication state information. This information is presented to the user when they query on pg_replication_slots.
|
1 2 3 4 5 |
postgres=# select * from pg_replication_slots ; slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn -----------+----------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+--------------------- sub | pgoutput | logical | 14185 | postgres | f | t | 8305 | | 7897 | 0/E967B630 | 0/E967B668 (1 row) |
Ideally, one should expect everything persisted in the data directory of the primary side to be present in the data directory of physical standby. But when it comes to the case of the replication slot, it won’t be available on the physical standby side.
|
1 2 |
$ ls -R pg_replslot/ pg_replslot/: |
If you are using pgbasebackup, it won’t be copying this file at all.
Now the question arises, what happens if we explicitly copy this state file directly to the physical standby side?
|
1 2 3 |
[postgres@pg0 ~]$ scp -r $PGDATA/pg_replslot/* pg1:$PGDATA/pg_replslot postgres@pg1's password: state 100% 176 135.6KB/s 00:00 |
Since we are just copying the file without the notice of the PostgreSQL processes, it won’t be available until PostgreSQL re-reads the data directory. And no slot information will be available on the standby side.
|
1 2 3 4 |
postgres=# select * from pg_replication_slots ; slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn -----------+--------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+--------------------- (0 rows) |
It would have been better if promoting the standby if PostgreSQL detects the new slot copied from the primary. But the slot will remain invisible until the next restart of the PostgreSQL instance. A restart of the instance will help PostgreSQL to detect the slot.
|
1 2 3 4 5 6 7 8 9 10 11 |
postgres=# select pg_is_in_recovery(); pg_is_in_recovery ------------------- t (1 row) postgres=# select * from pg_replication_slots ; slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn -----------+----------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+--------------------- sub | pgoutput | logical | 14185 | postgres | f | f | | | 7971 | 2/55000028 | 2/55000060 (1 row) |
Once the slot is visible in the standby, it starts retaining all the WALs. because the catalog_xmin and LSN won’t be advancing. This could be dangerous.
So if we want to engineer an external solution, I would prefer PostgreSQL doesn’t recognize the slot until the failover is required. And as a first step for the promotion, restart the standby instance with slot information in place, even though it is not a very ideal and an unwanted step in normal standby promotion. On the event of a primary failure, a restart of the standby with the latest slot copy and promotion can be done.
|
1 |
pg_ctl restart -D $PGDATA; pg_ctl promote -D $PGDATA |
Once the same slot is available in newly promoted primary, the logical subscriber can just alter the subscription to a new master.
|
1 |
ALTER SUBSCRIPTION sub CONNECTION 'host=pg1 port=5432 dbname=postgres user=repluser password=highlysecret'; |
**Please note that we are changing host of the connection from pg0 to pg1 in this case
The publisher’s information is part of the catalog and it is already replicated. In addition to this, all the WALs for logical decoding need to be retained on the standby. However, there is no automatic mechanism like a slot on standby. A probable workaround for this is to retain as many WAL files required by using settings like max_wal_size and min_wal_size on the standby side set to a really big value while making sure that there is sufficient space on the disk.
NOTES:– This post is not to make any specific recommendations but as a better understanding for PostgreSQL users. Implementation of solutions based on this for specific business requirement needs more engineering and testing specific to the environment design. There are a few caveats in this. The lag of the physical standby should not be lagging behind the logical subscriber. Cases of silent timeline divergence, as discussed in the thread, should be taken care of. At the time of a failover/standby promotion, it should be quick to restart the standby to detect the slot and then promote so that autovacuum won’t clean it up. Special attention is needed not to lose any catalog_xmin.





FWIW I’ve implementd pg extension to create slots on standby to overlap LSNs from old timeline with new timeline https://github.yandex-team.ru/mdb/pg_tm_aux
Hi Andrey,
This is an excellent effort.
The link you provided is not accessible to us. Hope your github repo has the latest code : https://github.com/x4m/pg_tm_aux/
Yup, sure, upstream-first development, in-house testing 🙂