
In this blog post, we’re going to break down what constitutes a MongoDB replica set.
While replica sets are not a specific environment or solution, understanding what you can do with their sophisticated features helps fit a multitude of situations. With many classical databases, you would need to use services, third party software and scripts to facilitate many of the abilities of a replica set. We are going to explore how you might use each, and end with a complicated diagram showing off these features.
If you ever asked why can’t we have an elastic, highly available, fast to recover and resilient database layer out of the box, then this blog will help you pick the right thing to get the features you need. The design given here – while good, sophisticated and expansive – is only an example. Please make sure you only use what you need to get the result you desire.
In all projects, we need to some way to store data persistently. In many cases, this needs to be a shared state across all of your applications that allows load balancing for incoming traffic to help you scale. To facilitate this layer of scaling up and out as needed, we typically have a few requirements: Data Loading, Replication, Recovery, Fail-Over and Data stability. In a different database, these are all separate tasks your operations group would handle, using precious staff hours and thus costing you money. Using replica sets lets you defer much of this work, while supporting higher uptime (also called “9s” due to its automated behaviors).
MongoDB replica sets include a few basic node types: Primary, Secondary, and Arbiter. These, in turn, support a few options: Priority, Votes, Delay, Tags, and Hidden. Using these together allows you some very advanced or very simple configurations.
|
Term
|
Meaning
|
|
|---|---|---|
| Primary | A node that accepts writes and is the leader for voting (there can be only one!). | |
| Secondary | A node that replicates from the Primary or another secondary, and can be used for reads if you tell the query to allow this. There can be a max of 127. | |
| Arbiter | In the event your physical node count is an even number, add one of these to break the tie. Never add one where it would make the count even. | |
| Priority | No arbiter nodes can have a priority set. Allows you to prefer specific nodes are primary, such as any node in your primary data center or one with more resources. | |
| Votes | In some specific cases, having more than eight nodes means additional nodes must not vote. This allows you to set that. | |
| Delay | You can make a node not vote, be hidden and delay its replication. This is useful if you want to quickly revert all nodes back by a set amount of time to reverse a change, as resyncing this node to the others is faster than a full recovery. | |
| Tags | Grants special ability to make queries directly to a specific node(s). Useful for BI, geo locality and other advanced functions. | |
| Hidden | This makes a node unable to take queries from clients without a tag, but is useful for a dedicated DR or backup node. |
The table above tells you what each main setting is, but there is much more you could use to control writing, reading and even chaining replication. However, those advanced functions are outside of the scope of this document, as you will know when you need them. What we’re going to talk about is the RAID level you need in MongoDB. This is a subject that need more consideration.
Below I will talk about RAID a good deal; this is because it’s important to understand where you can save costs to justify more nodes. However, in the cloud your choices are different. Typically you would not use several ephemeral type drives to make a RAID that would go away. Similarly, you might think to use EBS or other cloud storage systems because they already have durability and scaling in their design. Interestingly, I would rather have local SSD’s with MongoDB as discussed below. It provides duplication and stripes data across many nodes to solve that issue. It also reduces the impact or network issues affecting storage. This sounds great, but it also means I can’t just clone a snapshot to build a new node, and in a traditional RDBMS you might opt for EBS because of the work involved in creating a new replica. With MongoDB, however, our story is different. We instead merely spin up a new node and tell it what replica set it is part of. When MongoDB starts up, it automatically copies the data for use. The ability to copy data when needed removes the need for shared storage or using snapshots.
This is not to say you MUST use ephemeral SSD storage. You can, of course, use provisioned IOPS or basic EBS for example. However, in both cases there are logical network limitations to consider on your account, let alone per-node. EBS provides you an extra layer of protection on the storage level, but I would instead take those same savings and allow myself an additional data bearing node, allowing even more availability, resiliency and read scaling.
When talking about their own data center, many people would suggest we use RAID5 everywhere. However, is this the best option? To answer this, here’s a quick primer on RAID levels.
Data is split up into blocks that get written across all the drives in the array. By using multiple disks (a minimum of two) at the same time, this offers superior I/O performance. RAID 0 provides excellent performance, both in read and write operations. There is no overhead caused by parity controls. We use all storage capacity, and there is no overhead.
BUT…
RAID 0 is not fault-tolerant. If one drive fails, we lose all data in the RAID 0 array. It should not be used for mission-critical systems. RAID 0 does not provide any performance benefits either.
Data is stored twice, as when anything is written to drive 0 the same write event also occurs on drive1 or drive(n) in larger RAID1 setups. When you have a drive failure, you can replace the failed drive and copy the data block by block to the new drive from your existing good drive. As this is pure sequentially reads, it’s recovery is considered to be very fast and stable. RAID1 allows you to read from N number of copy drives, so performance increases with available drives. Write performance, however, is still limited to the speed of a single drive. The rebuild is easy as its block copy, not a logical rebuild
But…
Where RAID 0 allowed you to use all storage capacity, RAID1 cuts it by 50% due to duplication. Software RAID1 is not the best option due to rebuild and hot-swap issues. You need hardware controllers for anything above level 0.
RAID 10 can also be considered to be RAID 1+0. It is the marriage of both designs, taking on the ability to scale to more sets of duplication. In RAID 0, you could have four drives but there would not duplicate any data. In RAID 1, on the other hand, you would have the capacity of a single drive with three additional replica drives. Obviously getting 25% of your storage is only useful in extreme redundancy needs, for which you usually would use a SAN instead. With RAID10, you could say d1/d2 and d3/d4 are paired, so you get the read performance of four drives and the write performance of two drives while having disk failure tolerance.
BUT…
RAID5 allows more than 50% usage of capacity, unlike RAID1+0. The trade-off is capacity vs. Mean Time to Recovery (MTR). The minimum drive count is four drives. You should carefully consider this vs. additional shards in MongoDB.
RAID 5 is the most common RAID in a typical system. It provides good data capacity, durability and read performance. However, it is strongly impacted by write cost, which includes rebuilding times. This RAID level is going to have the slowest recovery time, which keeps the system in a degraded state (but still working). Adding more drives allows you to create what is also called RAID 6, or having 2+ parity drives, allowing you multiple disk failures before a full outage. Like RAID1, hardware controllers are preferred for both performance and stability reasons. Many database systems use this, as rebuilding or recovery is manual in the database, and we want to avoid that work. This is where MongoDB differs. Replica sets already provide stripping+partity. However, it’s over separate systems, meaning its even less likely for all components to fail at the same time. For this reason, to run any replica set with RAID 5/6 is considered overkill. I typically recommend either RAID1 or RAID10 – it varies by the storage available. It is common for larger drivers to cost more, so you should consider the ROI on doing RAID 10 with four drives of smaller size (this is especially true with SSDs).
As mentioned, MongoDB already provides duplication and stripping across nodes. For this reason, some people use RAID0, which is as wrong as using RAID5. This is the Goldilocks paradox in action: one does not provide enough single node recoverability, and the other too much so that it costs you valuable response time. RAID1 or 1+0 is the best choice here, so long as you follow the best advice and have three full data nodes (not two for data and one arbiter). It is important to note that RAID5 or even RAID6 are still acceptable, but you need to consider that their recovery times might exceed the time MongoDB could have just done initial sync with less than five minutes of your DBA/SRE’s time. MongoDB takes this even further when you consider sharding. It adds an extra layer as only N% of data is owned in any single shard, and the replica set + RAID1 provides the durability of that data.
Now that you are an active contender to be an expert in the features and consideration of a replica set, we should see two replica sets in action by showing you an “Every Feature Configuration Replica Set” architecture example. While it is very complicated, it can show you how you could run two main data centers and one DR data center, needing east and local west reads for performance, local backup nodes to improve recovery, delayed slave in the DR, and even a preferred pair of nodes to become primary.
The most common thing people get wrong with replica sets is one thing with two outcomes: the arbiter. You should always run three full data nodes if you don’t need any work such as building indexes, building a node, or backups. These can have a measurable impact on your system, or worst yet, risk your HA coverage. On the other side, do not randomly add arbiters. Only use them to break ties and only where you need to. Adding a full data node where you can afford it will always improve your uptime SLA capabilities.
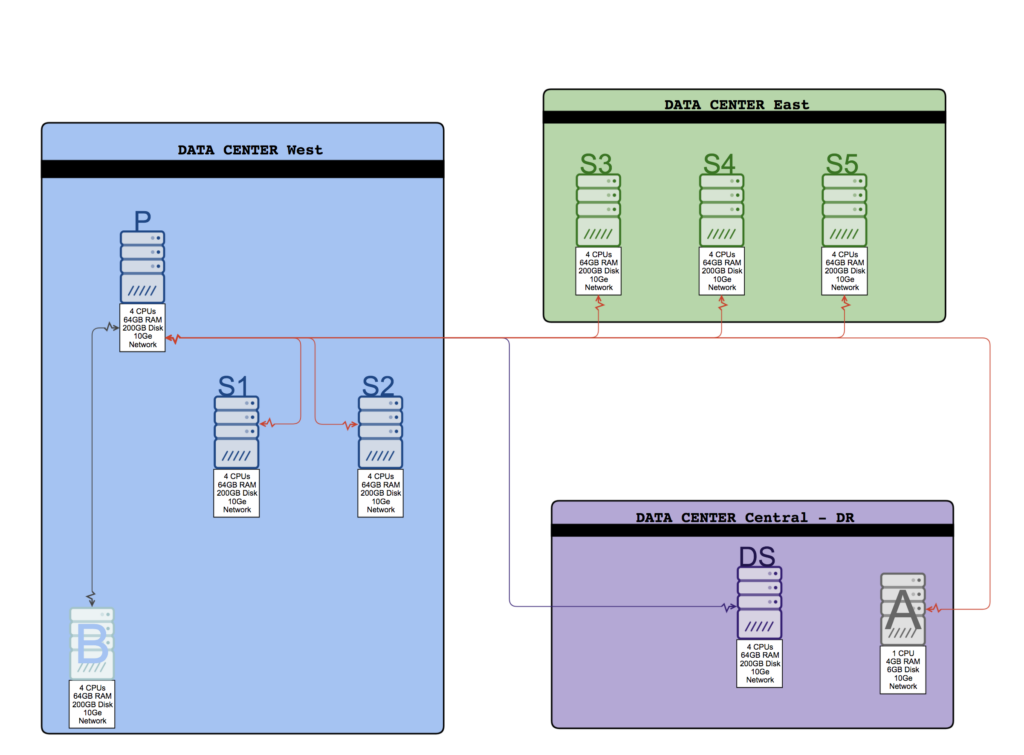 The nodes in the diagram explained:
The nodes in the diagram explained:
All writes are sent to this node for this replica set. S1-S5 could also become primary, however, as S3-S5 have priority:1, and P, S1, and S2 have priority:2. The system will keep the primary on the west coast, only moving to the east coast in dire need.
This non-voting node is dedicated for backups, as seen by the gray heartbeat, and it does not vote or answer queries, and is not in the “West” tag-set.
Both of these nodes are normal secondaries that do vote but are also members of the West tag-set. This means any applications in West that use the tag will query them (not S3-S5). In the event of an election, as this is the primary data center they have a priority of 2, so P, S1, S2 are preferred to keep the primary in West.
Like S1/S2, these nodes are secondaries, but only become primary if the West DC is down in some way. Additionally, as these are green, they are in the “East” tag set. Reads for east coast applications go here, not to the west coast, but writes still go to the primary.
This is a special node that is purple as it’s hidden so it won’t take reads, and delayed so that it applies stuff a full two hours behind the rest of the cluster. Doing this allows the final data center to be a proper Disaster Recovery site. This node can never become primary, and it is unable to vote.
Finally, we get to the arbiter. As we have three voting members in East and West each, we have an even six votes. To break any ties, we have placed an arbiter that holds no data into the DR to ensure either West or East will always have a primary if the opposing DC was to go offline.
I hope this has helped you feel more confident in knowing how a MongoDB replica set works, how to configure them and proper hardware planning when it comes to storage for a distributed database like MongoDB.
Resources
RELATED POSTS




