
In this blog post, we’ll look at MongoDB 3.6 sessions implementation.
As I mentioned in my previous post, we are going to look a bit deeper into the new sessions in MongoDB 3.6. You should know that many of the cornerstone features of 3.6 depend directly or indirectly on sessions – things such as “retryable” writes, casual consistency, killSession (global killOp) and more.
However, before we get into using them and how they work, why exactly are they needed? To talk about that we need to understand a bit of the MongoDB ecosystem history. A long time ago in a distant but familiar database called MongoDB 2.4 (Mar 2013), we had a simple command protocol stack. You might see something like the following:
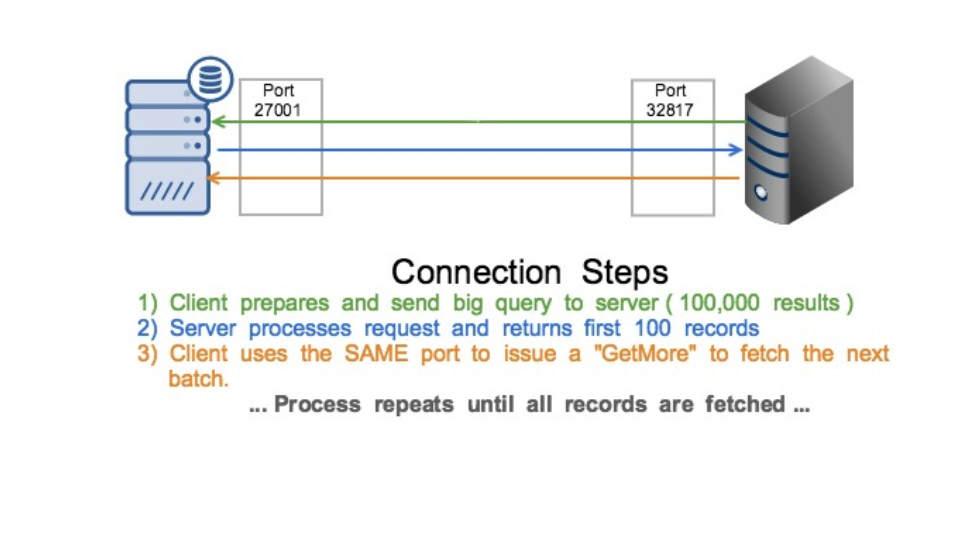
Makes sense right? This also made it very easy for things like load balancers to work, as they were always using the same source and destination port. You could choose to have things like a least-connection map to multiple mongos nodes in a sharded setup, instead of having to expose them directly to your applications. While this worked well, it made handling failovers to the driver less clean than some people would like. Thus in MongoDB 3.4, a new model was established where each outgoing request used a new random port. The drivers would handle failover, load balancing and connection pooling themselves, making it easier for a developer to not think about those situations. Unfortunately, operation teams were not as happy.
When this change occurred, any team that did have their own internal procedures or rules saying they needed a load balancer for security or segmentation had a bit of a mess. The move made it so least connection strategies would no longer work, and MongoDB Inc suggested you should not have a load balancer at all.
Given no other option to the operation, teams had to move to using the only host-based pinning balancer strategies to meet corporate guidelines. This solution had issues. A busy server would “pin” to a single mongos, and there was a probability that multiple busy nodes could end up on the same mongos. From this point on, the diagram looked more like this:
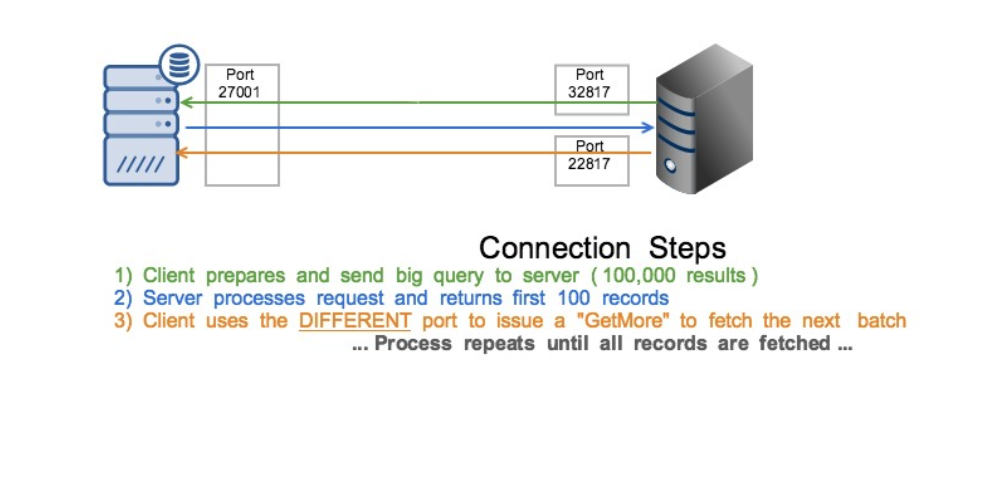
You might ask, well why didn’t they provide some piece of data to the load balancer to make it easier on them? I truly believe they wanted to, but there was no good way to do it. There wasn’t a global ID tracker, meaning two mongos could generate the same ID if they just provided the operation ID from db.currentOp(). With WiredTiger, however, there are more options. Unlike MMAPv1, WiredTiger has some native snapshot abilities due to its MVCC nature. Teams could use this to get an ID with a low rate of collision.
Fundamentally this is what sessions are built out of, but it’s more complex as you need a place to store them and a way to make them persist across elections to allow a true “resume”. To allow this, they provided an interface in system.sessions for each database (where they are kept). Information was recorded in such a way that these snapshots and their results could be shared across nodes solving the issue. A side effect (not yet tested but VERY likely) is that you could move back to a customized least connection system, as mongos now have a shared global ID inventory and can make sure your query goes to he right place.
This comes with some need for planning on your side. However, if you look carefully in the manual on system.sessions, it states that when sharding – if a node already has a system.session collection when sharding is enabled – it will delete it and recreate it. What this means in practice is you will want to actually STOP ALL WORK on a collection when you go to shard it. Otherwise, your sessions could vanish and your application become very confused.
While this is a minuscule amount of time, it’s a change you don’t want to get burned by. Let’s see what the same process as before look like now, with sessions. Please note that gray lines indicate actions that are automatic and invisible to you.
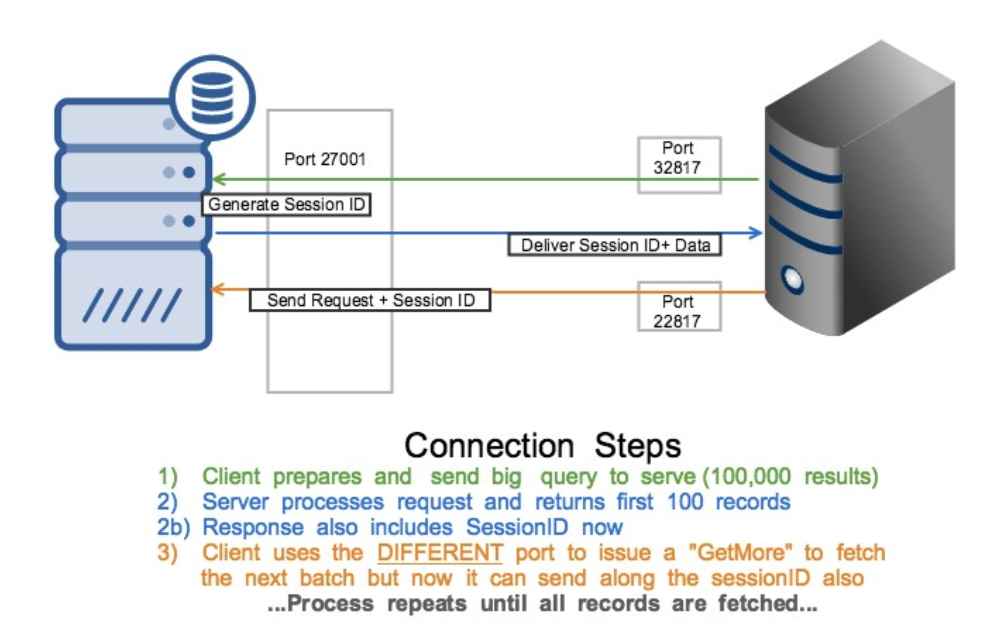
We’ll write more posts on the features that are built on this logic, but it is very important the community understands how we came to need these, how they work and what it means.





This is a horrible explanation.
I agree ^