
 In this first of its kind, Percona welcomes Dehowe Feng, Software Developer from Bitnine as a guest blogger. In his blog post, Dehowe discusses how viewing imported data from IMDb into a graph database (AgensGraph) lets you quickly see how data nodes relate to each other. This blog echoes a talk given by Bitnine at the Percona Live Open Source Database Conference 2017.
In this first of its kind, Percona welcomes Dehowe Feng, Software Developer from Bitnine as a guest blogger. In his blog post, Dehowe discusses how viewing imported data from IMDb into a graph database (AgensGraph) lets you quickly see how data nodes relate to each other. This blog echoes a talk given by Bitnine at the Percona Live Open Source Database Conference 2017.
Graphs help illustrate the relationships between entities through nodes, drawing connections between people and objects. Relationships in IMDb are inherently visual. Seeing how things are connected grants us a better understanding of the context underneath. By importing IMDb data as graph data, you simplify the schema can obtain key insights.
In this post, we will examine how importing IMDb into a graph database (in this case, AgensGraph) allows us to look at data relationships in a much more visual way, providing more intuitive insights into the nature of related data.
For install instructions to the importing scripts, go here.
Internet Movie Database (IMDb) owned by Amazon.com is one of the largest movie databases. It contains 4.1 million titles and 7.7 million personalities (https://en.wikipedia.org/wiki/IMDb).
Relational Schema for IMDb
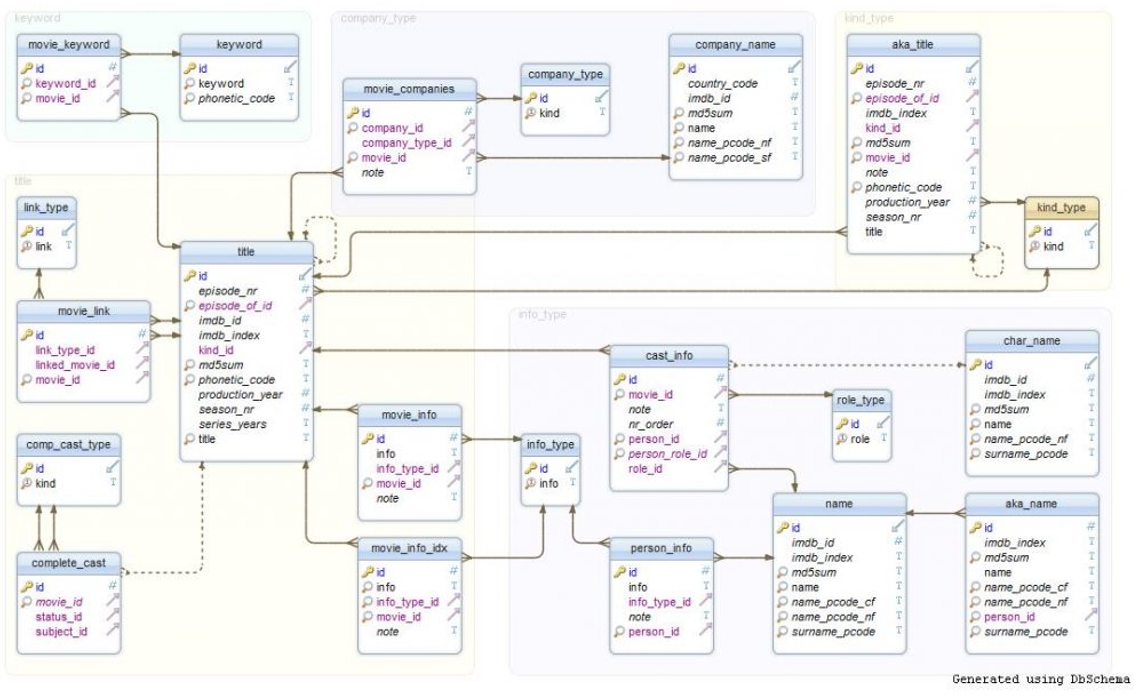
Relational Schema of IMDb Info
Picture courtesy of user ofthelit on StackOverflow, https://goo.gl/SpS6Ca
Because IMDb’s file format is not easy to read and parse, rather than implementing the file directly we use an additional step to load it into relational tables. For this project, we used IMDbpy to load relational data into AgensGraph in relational form. The above figure is the relational schema which IMDbpy created. This schema is somewhat complicated, but essentially there are four basic entries: Production, Person, Company and Keyword. Because there are many N-to-N relationships between these entities, the relational schema has more tables than the number of entities. This makes the schema harder to understand. For example, a person can be related to many movies and a movie can have many characters.
Concise Graph Modeling
From there, we developed our own graph schema using Production, Person, Company and Keyword as our nodes (or end data points).
Productions lie at the “center” of the graph, with everything leading to them. Keywords describing Productions, Persons and Companies are credited for their contributions to Productions. Productions are linked to other productions as well.
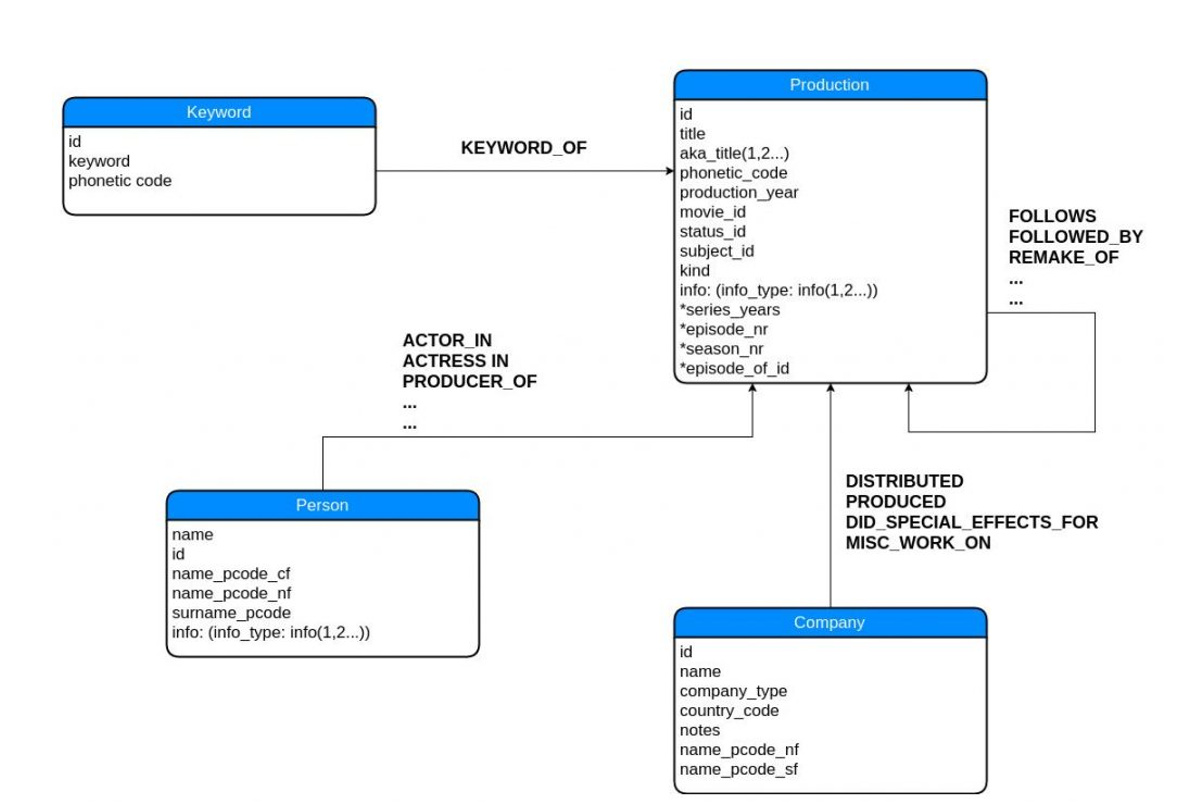
Simplified Graph Database Schema
With the data in graph form, one can easily see the connections between all the nodes. The data can be visualized as a network and querying the data with Cypher allows users to explore the connections between entities.
Compared to the relational schema of IMDb, the graph schema is much simpler to understand. By merging related information for the main entities into nodes, we can access all relevant information to that node through that node, rather than having to match IDs across tables to get the information that we need. If we want to examine how a node relates to another node, we can query its edges to see the connections it forms. Being able to visually “draw a connection” from one node to another helps to illustrate how they are connected.
Furthermore, the labels of the edges describe how the nodes are connected. Edge labels in the IMDb Graph describe what kind of connection is formed, and pertinent information may be stored in attributes in the edges. For example, for the connections ACTOR_IN and ACTRESS_IN, we store role data, such as character name and character id.
Data Migration
To make vertexes’ and edges’ properties we use “views”, which join related tables. The data is migrated into a graph format by querying the relational data using selects and joins into a single table with the necessary information for creating each node.
For example, here is the SQL query used to create the jsonb_keyword view:
|
1 2 3 4 5 |
CREATE VIEW jsonb_keyword AS SELECT row_to_json(row(keyword)) AS data FROM keyword; |
We use a view to make importing queries simpler. Once this view is created, its content can be migrated into the graph. After the graph is created, the graph_path is set, and the VLABEL is created, we can use the convenient LOAD keyword to load the JSON values from the relational table into the graph:
|
1 2 3 |
LOAD FROM jsonb_keyword AS keywords CREATE (a:Keyword = data(keywords) ); |
Note that here LOAD is used to load data in from a relational table, but LOAD can also be used to load data from external sources as well.
Creating edges is a similar process. We load edges from the tables that store id tuples of the between the entities after creating their ELABELs:
|
1 2 3 4 5 6 7 8 9 |
LOAD FROM movie_keyword AS rel_key_movie MATCH (a:Keyword), (b:Production) WHERE a.id::int = (rel_key_movie).keyword_id AND b.id::int = (rel_key_movie).movie_id CREATE (a)-[:KEYWORD_OF]->(b); |
As you can see, AgensGraph is not restricted to the CSV format when importing data. We can import relational data into its graph portion using the LOAD feature and SQL statements to refine our data sets.
How is information stored?
Most of the pertinent information is held in the nodes (vertexes). Nodes are labeled either as Productions, Persons, Companies or Keywords, and their relative information is stored as JSONs. Since IMDB information is constantly updated, many fields for certain entities are left incomplete. Since JSON is semi-structured, if an entity does not have a certain piece of information the field will not exist at all – rather than having a field and marking it as NULL.
We also use nested JSON arrays to store data that may have multiple fields, such as quotes that persons might have said or alternate titles to productions. This makes it possible to store “duplicate” fields in each node.
How can this information be used?
In the graph IMDb database, querying between entities is very easy to learn. Using the Cypher Query Language, a user can find things such as all actors that acted in a certain production, all productions that a person has worked on or all other companies that have worked with a certain company on any production. Graph database strength is the simplicity of visualizing the data. There are many ways you can query a graph database to find what you need!
Find the name of all actors that acted in Night at the Museum:
|
1 2 3 4 5 |
MATCH (a:Person)-[:ACTOR_IN]->(b:Production) WHERE title = 'Night at the Museum' RETURN a.name,b.title; |
Result:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
name | title -----------------------+--------------------- Asprinio, Stephen | Night at the Museum Blais, Richard | Night at the Museum Bougere, Teagle F. | Night at the Museum Bourdain, Anthony | Night at the Museum Cherry, Jake | Night at the Museum Cheng, Paul Chih-Ping | Night at the Museum ... (56 rows) |
Find all productions that Ben Stiller worked on:
|
1 2 3 4 5 |
MATCH (a:Person)-[b]->(c:Production) WHERE a.name = 'Stiller, Ben' RETURN a.name,label(b),c.title; |
Result:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name | label | title -------------+-------------+----------------------------------------------- ... Stiller, Ben | actor_in | The Heartbreak Kid: The Egg Toss Stiller, Ben | producer_of | The Hardy Men Stiller, Ben | actor_in | The Heartbreak Kid: Ben & Jerry Stiller, Ben | producer_of | The Polka King Stiller, Ben | actor_in | The Heartbreak Kid Stiller, Ben | actor_in | The Watch Stiller, Ben | actor_in | The History of 'Walter Mitty' Stiller, Ben | producer_of | The Making of 'The Pick of Destiny' Stiller, Ben | actor_in | The Making of 'The Pick of Destiny' ... (901 rows) |
Find all actresses that worked with Sarah Jessica Parker:
|
1 2 3 4 5 |
MATCH (a:Person)-[b:ACTRESS_IN]->(c:Production)<-[d:ACTRESS_IN]-(e:Person) WHERE a.name = 'Parker, Sarah Jessica' RETURN DISTINCT e.name; |
Result:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
name --------------------------------- Aaliyah Aaron, Caroline Aaron, Kelly Abascal, Nati Abbott, Diane Abdul, Paula ... (3524 rows) |
Summary
The most powerful aspects of a graph database are flexibility and visualization capabilities.
In the future, we plan to implement a one-step importing script. Currently, the importing script is two-phased: the first step is to load into relational tables and the second step is to load into the graph. Additionally, AgensGraph has worked with Gephi to release a data import plugin. The Gephi Connector allows for graph visualization and analysis. For more information, please visit www.bitnine.net and www.agensgraph.com.
Resources
RELATED POSTS




