
In this post, I’m going to discuss MongoDB consistent backups, and how to achieve them.
You might have read before that MongoDB backup is not consistent. But what if I told you there is a tool that could make them consistent. What if this tool also would make it cluster-wide consistent, automatically compress the backup, become the first step toward continually incremental recording, notify your monitoring system and upload the backup to cloud storage for you?
Recently Percona-Labs created a new repository aimed at exactly these issues. We hope it will eventually grow into something that becomes part of the officially supported tools (like Percona Toolkit and Percona’s Xtrabackup utility). Before we get into how it works, let’s talk about why we need it and its key highlights. Then (for all the engineering types reading this) we can discuss what is does and why.
The first thing to note is you absolutely can’t have a consistent backup on a working system unless your node is in a replicaset. (You could even have a single node replicaset for this to be accurate.) Why? Consistency requires an operations log to say what changes occurred from the first point in the backup to the last point. This lets us ensure we are consistent to the end timestamp of the backup. We are unable to verify consistency when the MongoDB backup started without the ability to take a “snapshot” of data and then save the data while other changes occur. MongoDB does not have ACID-like isolation in this way. However, it can be consistent to the backup endpoint by applying any deltas at the end of the backup restore process.
You might say, “but mongodump already provides --oplog for this feature.” You are right: it does, and it works great if you only have a single replicaset to backup. When we bring sharding into the mix, however, things get vastly more complicated. It ignores that flag and hits your primaries:
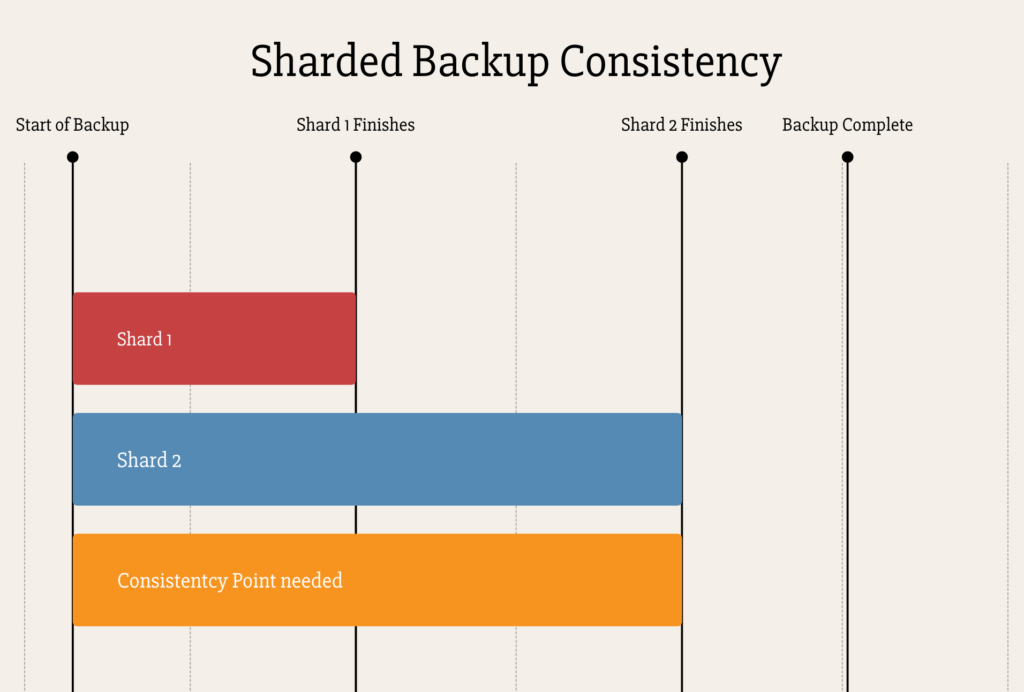
In the diagram above you can see the backup and oplog recording for the first shard ended long before the second shard. As such, the consistency point needed is nowhere close to being covered by the red line. Even if all your shards are the same size, there would be some level of variance due to network, disk, CPU and memory speeds. The new tool helps you here by keeping track of the dumps, but also by having a thread recording the oplog for all shards until the last shard finishes. This ensures that all shards can be synced to the point in time where the last shard finished. At that moment in time, we have a consistent backup across all the shards. As you can see below, the oplog finished watching both shards after the last shard finish. On recovery, they remain in sync.
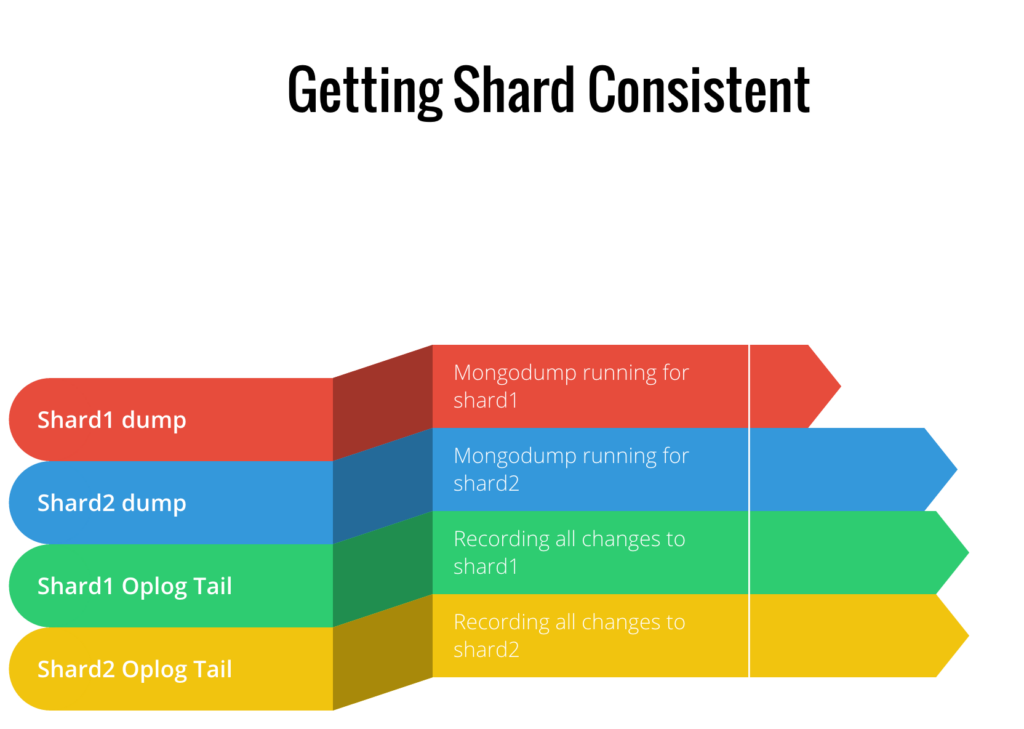
You might ask, “well what about the meta-data stored in the config servers.” This is a great quest, as the behavior differs in our tool depending on if you’re using MongoDB 3.2’s new Config Servers as a replica set feature, or a legacy config server approach.
In the legacy mode, we fsyncAndLock the config servers just long enough to record a server config data dump. Then we stop the oplog tailer threads for all the shards. After that, and after the oplog tailers finish, we unlock the config server. This ensures we remove the race conditions that could occur if it took longer than expected to close an oplog cursor. However, if we run in 3.2 mode, the config servers act just like another shard. They get dumped at the same time, and the oplog just gets tailed until we complete the data shard dumps. The newest features available to MongoDB Community, MongoDB Enterprise, and Percona Server for MongoDB 3.2 make the process much simpler.
Key Takeaways from new tool
Desired Roadmap
Please be sure to check out the GitHub @mongodb_consistent_backup and log any issues or features requests.
Feel free to reach out to me on Twitter @dbmurphy_data or @percona with any questions or suggestions as well.
Resources
RELATED POSTS





does it backup in native format or in bson format?