
This blog was originally published in June 2016 but was updated in February 2024.
In this blog post, we’ll look at various MySQL high availability (HA) solutions, detailing their advantages and disadvantages to equip you with the insight required for informed decision-making regarding your database infrastructure. HA is crucial for maintaining uninterrupted access to essential data; its absence can lead to severe outcomes such as data loss, downtime, and negative effects on customer satisfaction. Additionally, we will also explore 20 essential questions and considerations you should consider when choosing a solution.
High availability environments provide substantial benefits for databases that must remain available. A high availability database environment co-locates a database across multiple machines, any one of which can assume the functions of the database. In this way, a database doesn’t have a “single point of failure.”
There are many HA strategies and solutions, so how do you choose the best solution among a myriad of options? The first question to ask is, “What is the problem you are trying to solve?” The answers boil down to redundancy versus scaling versus high availability. These are not necessarily all the same!
When you are planning your database environment, it’s important to remember the CAP Theorem applies. The CAP Theorem breaks problems into three categories: consistency, availability, and partition tolerance. You can pick any two from those three, at the expense of the third.
Whatever solution you choose, it should maximize consistency. The problem is that although MySQL replication is great, it alone does not guarantee consistency across all nodes. There is always the potential that data is out of sync, since transactions can be lost during failover and other reasons. Galera-based clusters such as Percona XtraDB Cluster are certification-based to prevent this!
MySQL high availability refers to the practices, techniques, and technologies used to ensure that a MySQL database is continuously operational, minimizing downtime and ensuring data is always accessible. This involves configuring the database environment in a way that allows it to quickly recover from hardware failures, network issues, and other potential disruptions. Key components of MySQL HA include replication (such as master-slave or master-master setups), clustering solutions (like MySQL Cluster or Galera Cluster), automatic failover mechanisms, and load balancing. These strategies aim to provide redundancy, fault tolerance, and seamless failover capabilities to maintain service continuity and data integrity, even in the event of system failures.
MySQL databases are pivotal in storing, processing, and retrieving the vast amounts of data that many of us utilize every day. However, the reliance on databases brings to light the challenges associated with downtime. Even minimal periods of inactivity can lead to significant losses, tarnish brand reputation, and disrupt customer experiences. This underscores the critical need for MySQL HA solutions.
MySQL HA is crucial across various scenarios:
E-commerce relies on uninterrupted database access to process transactions, manage inventory, and provide customer support. High availability ensures that these platforms can handle not only daily traffic but also the surge of traffic during peak shopping seasons without faltering.
Financial services, including online banking and trading platforms, require consistent database availability to execute transactions, update account information, and comply with regulatory requirements. MySQL HA solutions safeguard these operations against potential data loss or service interruptions.
Healthcare systems use databases to manage patient records, appointments, and critical medical information. High availability is essential to ensure that healthcare providers have uninterrupted access to life-saving data.
Lacking high availability strategies in MySQL database environments can lead to severe operational disruptions and data integrity challenges. Businesses might face significant downtime, directly impacting revenue, customer satisfaction, and overall productivity, and the absence of HA practices like proper replication and failover mechanisms leaves critical data vulnerable during system failures.
Let’s look at a few potential consequences of lacking high availability in MySQL:
Downtime can significantly impact business operations, leading to lost productivity and opportunities. MySQL environments without high availability solutions are more prone to prolonged outages, directly affecting service continuity. See The Impact of Downtime on Your Business for more info.
Absent high availability, MySQL databases face a risk of data loss during hardware failures or software crashes. Such losses can be irrecoverable, affecting data integrity.
Customer experiences can be severely degraded by unavailable services or slow response times due to database issues. High availability ensures that MySQL databases remain accessible, maintaining service quality and customer satisfaction.
Not only do downtime and data loss disrupt operations, but they can also lead to direct financial losses. Businesses may incur costs from lost sales and damaged reputations.
A failure in a MySQL environment can halt critical business operations, affecting everything from inventory management to customer interactions.
Organizations subject to regulatory requirements may face compliance issues and legal ramifications if data availability and integrity are compromised.
Frequent outages and the need for manual interventions to restore services without HA increase maintenance costs.
The integrity of data stored in MySQL databases can be compromised when HA measures are not in place, leading to inconsistencies and errors in data retrieval and processing. High availability setups help preserve data accuracy and reliability, essential for trustworthiness and analytical precision.
MySQL HA solutions are necessary for database systems requiring uninterrupted access and real-time data processing. These solutions are designed to prevent downtime and data loss, thereby supporting a wide range of applications, from high-traffic websites to critical infrastructure systems. Below, we explore specific use cases where MySQL HA plays a crucial role in maintaining operational efficiency, customer satisfaction, and business continuity.
For websites that experience large volumes of traffic, MySQL HA ensures that database services remain online, even during high traffic loads or infrastructure failures. This is vital for maintaining user engagement and preventing potential revenue losses.
Businesses having a global reach must ensure that their databases are always available to support operations across many time zones. MySQL HA solutions help such businesses to provide consistent, uninterrupted services to clients worldwide.
Organizations that use real-time data analytics for decision-making require highly available databases to enable quick data processing and insights. MySQL HA installations enable the continuous flow of data, facilitating analytics tools to provide accurate, up-to-date analysis.
As web and mobile applications grow, they must scale without compromising performance or availability. HA strategies support this scalability, ensuring that applications remain available and performant as they expand.
For essential systems such as financial transaction platforms or healthcare records systems, MySQL HA is crucial. It ensures that these critical systems remain operational, safeguarding against data loss and service interruptions that could have severe repercussions.
In exploring high availability and disaster recovery strategies for databases, it’s important to address common challenges and questions that arise. Below, we take a look at 20 key questions and considerations, ranging from data loss prevention and scaling needs to choosing the right storage engines and managing failover processes.
The first question you should ask yourself is, “Can I afford to lose data?”
This often depends on the application. Apps should check status codes on transactions to be sure they were committed. Many do not! It is also possible to lose transactions during a failover. During failover, simple replication schemes have the possibility of losing data
Inconsistent nodes are another problem. Without conflict detection and resolution, inconsistent nodes are unavoidable. One solution is to run pt-table-checksum often to check for inconsistent data across replication nodes. Another option is using a Galera-based Distributed Cluster, such as Percona XtraDB Cluster, with a certification process.
What is watching your system? Or is anything standing ready to intervene in a failure? For replication, take a look at MHA and MySQL Orchestrator. Both are great tools to perform failover of a Replica. There are others.
For Percona XtraDB Cluster, failover is typically much faster, but it is not the perfect solution in every case.
Many MySQL DBAs worry about setting innodb_flush_log_at_trx_commit to 1 for ACID compliance and sync_binlog, but then use replication with no consistency checks! Is this logically consistent? Percona XtraDB Cluster maintains consistency through certification.
All solutions must have some means of conflict detection and resolutions. Galera’s certification process follows the following method:
Another important consideration is whether you should have a failover or a distributed system. A failover system runs one instance at a time, and “fails over” to a different instance when an issue occurs. A distributed system runs several instances at one time, all handling different data.
Another question is should your failover be automatic or manual?
A further question is how fast does failover have to occur? Obviously, the faster it happens, the less time there is for potential data loss.
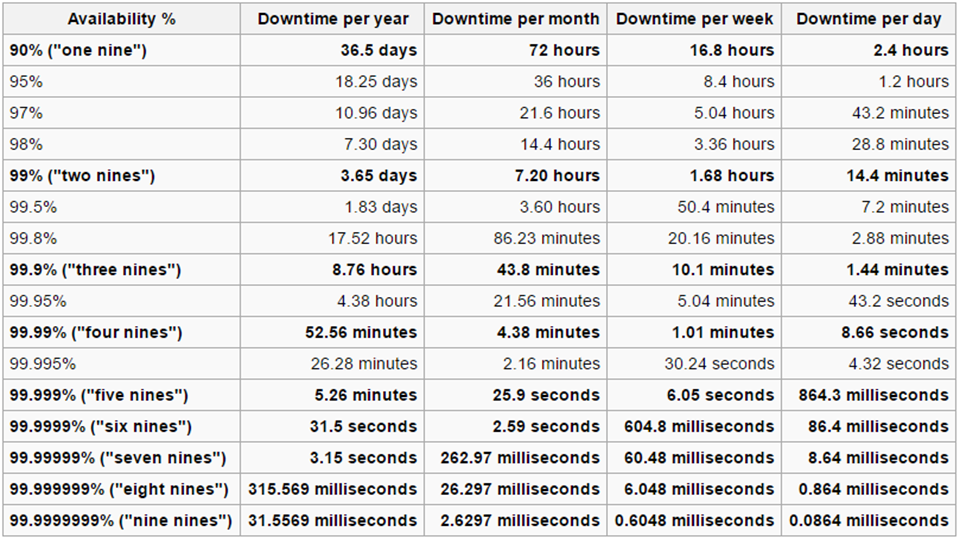
The “9” measure of accuracy is a standard for how perfect a system is. When it comes to “how many 9s,” each 9 is an order of magnitude more accurate. 99.99 is four nines, while 99.999 is five nines.
Every manager response to the question of how many nines is always “As many as I can get.” That sounds great, but the reality is that tradeoffs are required! Many applications can tolerate a few minutes of downtime with minimal impact. The following tables shows downtime as correlated to each “9”:
When looking at your environment, it’s important to understand your workload. Is your workload heavy on reads, writes, or both? Know whether you’re going to need to scale reads or writes is important to choosing your HA solution:
What about provisioning new nodes?
With Percona XtraDB Cluster, try to have three of everything. If you span a data center, have three data centers. If your nodes are on a switch, try to have three switches.
Percona XtraDB Cluster needs at least three nodes in the cluster. An odd number is preferred for voting reasons. Forget about trying to keep a cluster alive during failure with only two data centers. You are better off making one a DR site. Forget about custom weighting to try to get by on two data centers. The 51% rule will get you anyway!
Knowing how many data centers are involved in your environment is a critical factor. Running multiple data centers has implications for the HA solution you adopt.
What if I only have one data center? You can gain protection against a single failed node or more, depending on cluster size. If you have two data centers, you should probably be considering the second data center as a DR solution. Having three or more data centers is the most robust solution when using Galera-based clusters such as Percona XtraDB Cluster.
Planning for disaster recovery is crucial in your HA environment. Make sure the DR node(s) can handle the traffic, if even at a minimized performance level.
Learn more: The ultimate guide to database high availability
Nowadays especially, there is a multitude of storage engines available for a database environment. Which one should you use for your HA solution? Your solution will help determine which storage engine you can employ.
Load balancers provide a means to distribute your workload across your environment resources so as not to create a bottleneck at any one particular point. The following are some load balancing options:
Some changes require that the cluster be rebooted for the changes to be applied. For example, changing a parameter value in a parameter group is only applied to the cluster after the cluster is rebooted. A cluster could also reboot due to power interruption or other technology failures.
Asynchronous Replication does not guarantee consistent views of data across nodes. Percona XtraDB Cluster offers causal reads. Replica will wait for the event to be applied before processing additional queries, guaranteeing a consistent read state across nodes.
In the recent past, it was conventional wisdom to use replication in such scenarios over Percona XtraDB Cluster. MTS does help if data is distributed over multiple schemas but is not a fit for all situations. Percona XtraDB Cluster is now a viable option since we discovered a bug in Galera which did not properly split large transactions.
Split Brain occurs when a cluster has its nodes divided from one another, most often due to network blip, and nodes form two or more new and independent (and thus divergent) clusters. Percona XtraDB Cluster is configured to go into a non-primary state and refuse to take traffic. A newer setting with XtraDB Cluster will allow for dirty reads for non-primary nodes
Newer approaches to replication allow for parallel threads (Percona XtraDB Cluster has had this from the beginning), such as Multi-Thread Slaves (MTS). MTS allows a replica to have multiple SQL threads all with their own relay logs. It enable GTID to make backups via Percona XTRABackup safer due to not being able to trust SHOW SLAVE STATUS to get relay log position.
Some Distributed solutions such as MySQL Cluster require a lot of RAM, even with file-based tables. Be sure to plan appropriately. XtraDB Cluster works much more like a stand-alone node.
Networks are never really 100% reliable. Some “Network Problems” are due to outside factors such as system resource contention (especially on virtual machines). Network problems cause inappropriate failover issues. Use LAN segments with Percona XtraDB Cluster to minimize network traffic across the WAN.
Using cloud-based solutions for HA typically offers greater flexibility, scalability, and cost-effectiveness, with the ability to leverage the cloud provider’s infrastructure and services for redundancy and failover mechanisms. On-premise solutions, while offering more control over the environment, require significant upfront investment in hardware and expertise to achieve similar levels of HA.
In conclusion, making the right choice MySQL high availability depends on:
Discover the secrets to achieving superior MySQL High Availability in our detailed whitepaper, “Percona Distribution for MySQL: High Availability with Group Replication.” This expert guide not only offers Percona’s specialized recommendations for HA architecture and deployment but also provides an in-depth technical overview of solutions designed to deliver exceptional availability. Tailored for environments with high read/write demands, this whitepaper is your roadmap to implementing a robust HA strategy with Percona Distribution for MySQL. Download now to empower your applications with unparalleled reliability. You can also get some great insights by watching these videos on our high availability video playlist.
MySQL High Availability (HA) encompasses a series of methodologies and technological solutions aimed at maintaining continuous access and operational status of a MySQL database with little to no downtime, even amidst hardware malfunctions, scheduled maintenance, or unforeseen problems.
High availability is critical for MySQL databases because it assures ongoing access to data, which is required for business operations, user satisfaction, and data integrity. In contexts where data-driven decisions and real-time access are crucial, high availability reduces the risk of data loss and operational disruption due to downtime.
MySQL replication contributes to high availability by copying data from a primary server to one or more secondary servers, allowing for automatic failover in case the primary server fails, ensuring that data remains accessible. Replication also facilitates load balancing by directing read queries to secondary servers, enhancing availability.
Choosing the best high availability solution for your MySQL database requires considering your individual requirements, such as uptime requirements, economic constraints, and operational complexity. Consider the scale of your operations, the importance of your data, and your team’s experience with HA technologies. Consulting with database professionals or MySQL-focused vendors can provide specialized solutions based on your specific needs.
Yes, MySQL may achieve high availability with minimal downtime by carefully planning and implementing appropriate HA strategies like as replication, clustering, and automatic failover solutions.





Its one of the nicest presentations and the information is too good.
How about big schema changes, especially those that are not backwards compatible (when you cannot use RSU)? For mysql, you can use online alters, what about galera/pxc?