
 This blog post will discuss what the Adaptive Hash Index in InnoDB is used for, and whether it is a good fit for your workload.
This blog post will discuss what the Adaptive Hash Index in InnoDB is used for, and whether it is a good fit for your workload.
Adaptive Hash Index (AHI) is one of the least understood features in InnoDB. In theory, it magically determines when it is worth supplementing InnoDB B-Tree-based indexes with fast hash lookup tables and then builds them automatically without a prompt from the user.
Since AHI is supposed to work “like magic,” it has very little configuration available. In the early versions there were no configuration options available at all. Later versions added innodb_adaptive_hash_index to disable AHI if required (by setting it to “0” or “OFF”). MySQL 5.7 added the ability to partition AHI by enabling innodb_adaptive_hash_index_parts. (FYI, this feature existed in Percona Server as innodb_adaptive_hash_index_partitions since version 5.5.)
To understand AHI’s impact on performance, think about it as if it were a cache. If an AHI “Hit” happens, we have much better lookup performance; if it is an AHI “Miss,” then performance gets slightly worse (as checking a hash table for matches is fast, but not free).
This is not the only part of the equation though. In addition to the cost of lookup, there is also the cost of AHI maintenance. We can compare maintenance costs – which can be seen in terms of rows added to and removed from AHI – to successful lookups. A high ratio means a lot of lookups sped up at the low cost. A low ratio means the opposite: we’re probably paying too much maintenance cost for little benefit.
Finally there is also a cost for adding an extra contention. If your workload consists of lookups to a large number of indexes or tables, you can probably reduce the impact by setting innodb_adaptive_hash_index_parts appropriately. If there is a hot index, however, AHI could become a bottleneck at high concurrency and might need to be disabled.
To determine if AHI is likely to help my workload, we should verify that the AHI hit and successful lookups to maintenance operations ratios are as high as possible.
Let’s investigate what really happens for some simple workloads. I will use a basic Sysbench Lookup by the primary key – the most simple workload possible. We’ll find that even in this case we’ll find a number of behaviors.
For this test, I am using MySQL 5.7.11 with a 16GB buffer pool. The base command line for sysbench is:
|
1 |
sysbench --test=/usr/share/doc/sysbench/tests/db/select.lua --report-interval=1 --oltp-table-size=1 --max-time=0 --oltp-read-only=off --max-requests=0 --num-threads=1 --rand-type=uniform --db-driver=mysql --mysql-password=password --mysql-db=test_innodb run |
Looking up a single row
Notice oltp-table-size=1 from above; this is a not a mistake, but tests how AHI behaves in a very basic case:
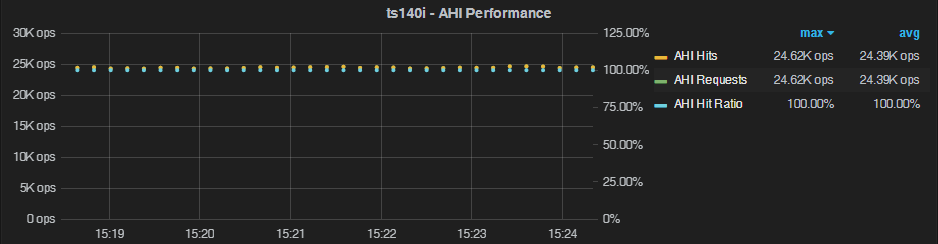
And it works perfectly: there is a 100% hit ratio with no AHI maintenance operations to speak of.
10000 rows in the table
When we change the OLTP table setting to oltp-table-size=10000 , we get the following picture:
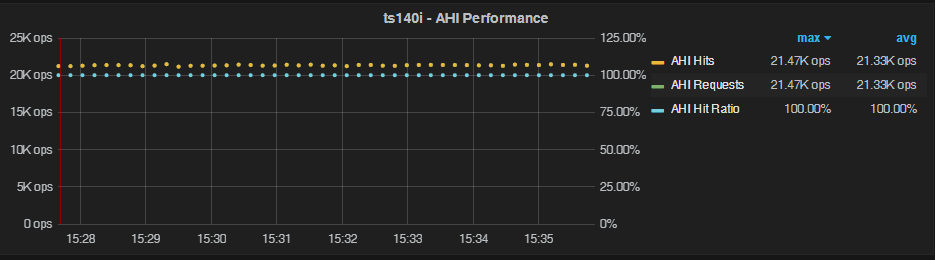
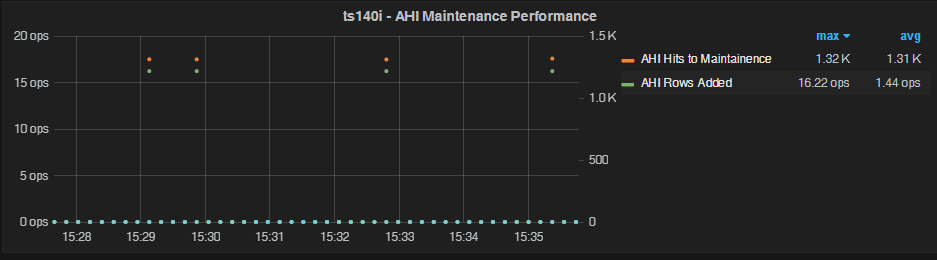
Again, we see almost no overhead. There is a rare incident of 16 rows or so being added to AHI (probably due to an AHI hash collision). Otherwise, it’s almost perfect.
10M rows in the table
If we change the setting to oltp-table-size=10000000, we now have more data (but still much less than buffer pool size):
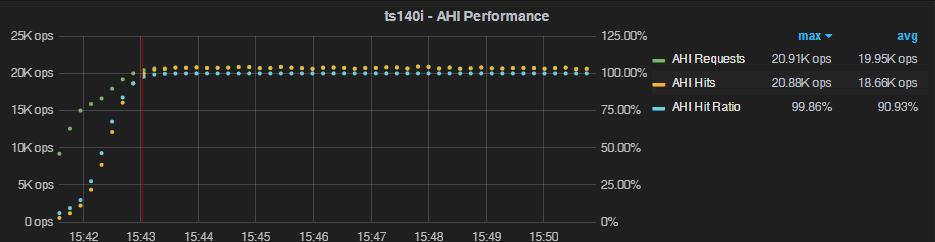
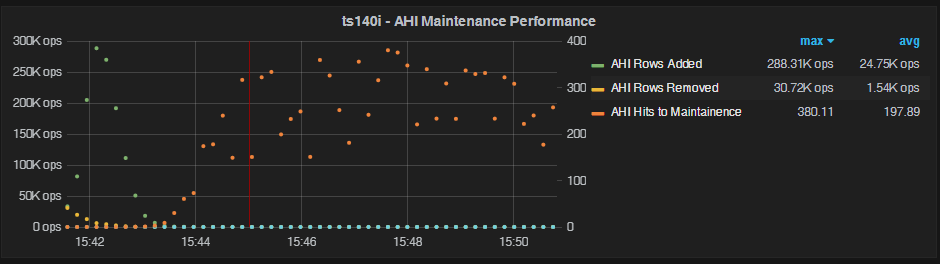
In this case, there is clearly a warm-up period before we get close to the 100% hit ratio – and it never quite hits 100% (even after a longer run). In this case, maintenance operations appear to keep going without showing signs of asymptotically reaching zero. My take on this is that with 10M rows there is a higher chance of hash collisions – causing more AHI rebuilding.
500M rows in the table, uniform distribution
Let’s now set the OLTP table size as follows: oltp-table-size=500000000. This will push the data size beyond the Innodb buffer pool size.
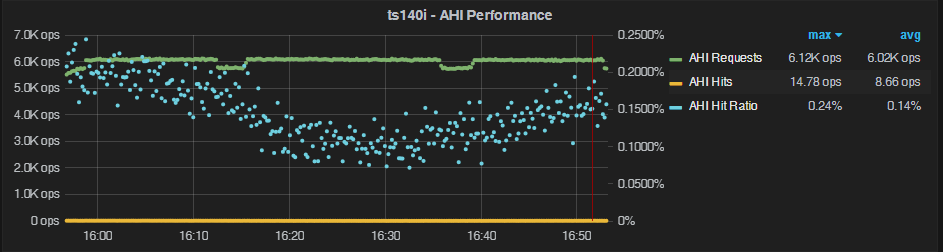
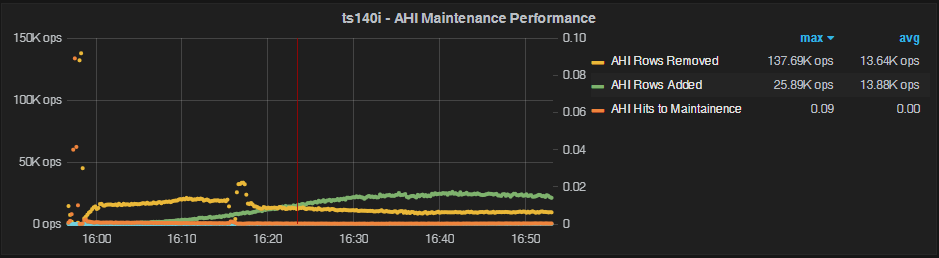
Here we see a lot of buffer pool misses, causing the a very poor AHI hit ratio (never reaching 1%). We can also see a large overhead of tens of thousands of rows added/removed from AHI. Obviously, AHI is not adding any value in this case
500M rows, Pareto distribution
Finally, let’s use the setting oltp-table-size=500000000, and add --rand-type=pareto. The --rand-type=pareto setting enables a skewed distribution, a more typical scenario for many real life data access patterns.
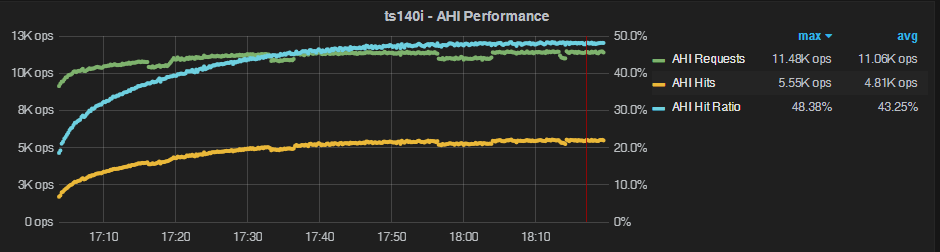
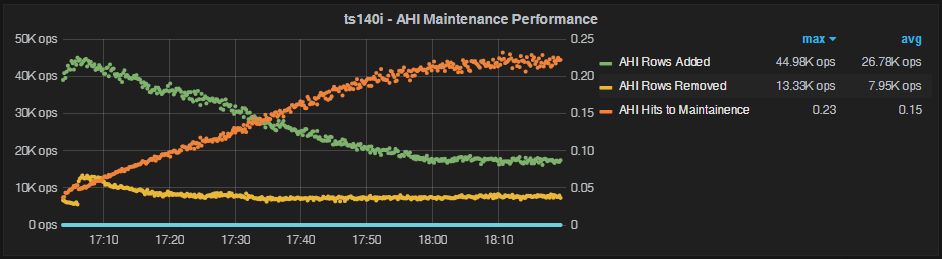
In this case we see the AHI hit ratio gradually improving, and reaching close to 50%. The AHI maintenance overhead is going down, but never reaches anything that suggests it is worth it.
It is important to note in both this and the previous case that AHI has not reached a “steady state” yet. A steady state condition shows the number of rows added and removed becoming close to equal.
As you can see from the math in the workloads shown above, the Adaptive Hash Index in InnoDB “magic” doesn’t always happen! There are cases when AHI is indeed helpful, and then there are others when AHI adds a lot of data structure maintenance overhead and takes memory away from buffer pool – not to mention the contention overhead. In these cases, it’s better that AHI is disabled.
Unfortunately, AHI does not seem to have the logic built-in to detect if there is too much “churn” going on to make maintaining AHI worthwhile.
I suggest using these numbers as a general guide to decide whether AHI is likely to benefit your workload. Make sure to run a test/benchmark to be sure.
Resources
RELATED POSTS





what type of graphing software are you using?
Hi Dathan,
This is Grafana + Prometheus. We will share more details on the conference next week!
so cool
Hi!
Could you specify where did you take the metrics – AHI Requests/AHI Hits to maintenance etc.? It isn’t clear from the article and I don’t see any similar in the mysqladmin extended-status output.
Vadym, These are available in Percona Monitoring and Management https://www.percona.com/software/database-tools/percona-monitoring-and-management In Innodb Metrics Advanced dashboard – you can check in the graph settings what specific formula was used
Thank you for the reply.
FYI
It seems that the email notification doesn’t work properly here – I’d already subscribed to the notifications, but didn’t see you answer in my mailbox.