
 MongoDB 3.2 was recently released with WiredTiger as the default storage engine.
MongoDB 3.2 was recently released with WiredTiger as the default storage engine.
In just over five years, MongoDB has evolved into a popular database. MongoDB 3.0 supported “pluggable storage engines.” The B-Tree-based WiredTiger should outperform IO-optimized RocksDB and PerconaFT in in-memory workloads, but it demonstrates performance degradation when we move into IO workloads.
There are reports that WiredTiger 3.2 comes with improved performance, so I ran a quick benchmark against WiredTiger 3.0.
My interest is in not only the absolute performance, but also how it performs during checkpointing. In my previous test we saw periodic drops: https://www.percona.com/blog/2015/07/14/mongodb-benchmark-sysbench-mongodb-io-bound-workload-comparison/.
For this test I am using iiBench by Mark Callaghan: https://github.com/mdcallag/iibench-mongodb.
WiredTiger command line:
|
1 |
<code>numactl --interleave=all ./mongod --dbpath=/mnt/i3600/mongo/ --storageEngine=wiredTiger --syncdelay=900 --wiredTigerCacheSizeGB=10 --wiredTigerJournalCompressor=none</code> |
Storage: Intel SSD DC P3600 SSD 1.6TB
Server: Bare Metal powered by Intel(R) Xeon(R) CPU E5-2680
For workload, I inserted 200 million records with 1 index.
The results (click on image to get higher resolution):
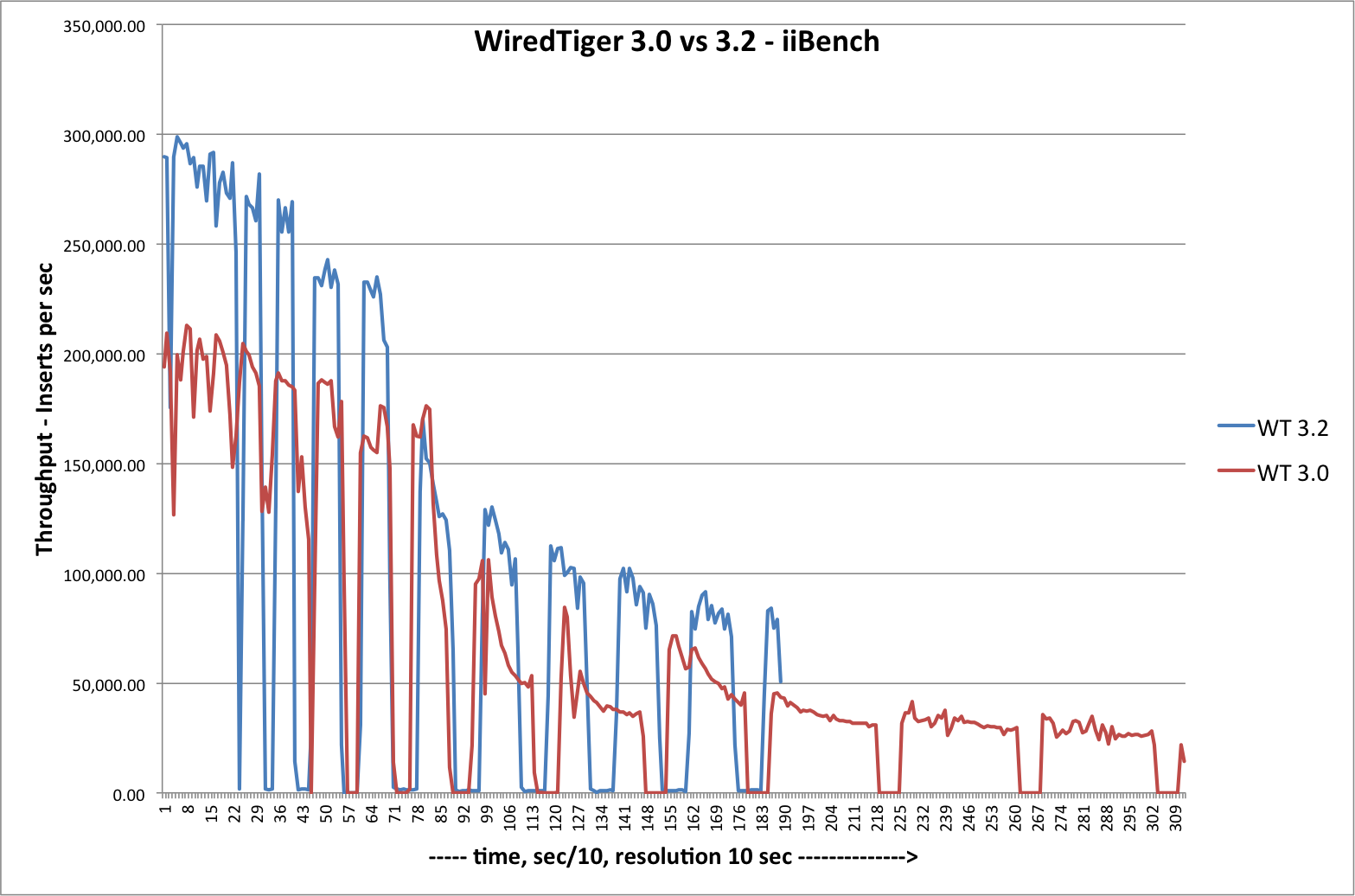
WiredTiger 3.2 is indeed faster. It finished in 31 min (compared to 51 min for WiredTiger 3.0).
However, the performance stalls are still there. There are periods of one minute or longer when WiredTiger refuses to process data.
Resources
RELATED POSTS





iibench-mongodb is from Tim, not sure he has merged all of my changes
https://github.com/tmcallaghan/iibench-mongodb
‘@Mark, I know iibench-mongodb is originally from Tim, I mean that I use your modifications (practically I use your tree)
Why the syncdelay was increased to that high?
WiredTiger also support LSM-Tree besides B-Tree,while LSM-Tree seems have better IO performance;So you should also have a test with LSM-Tree
The WiredTiger LSM is not officially supported (yet). The current choices for write-optimized engines are RocksDB (MongoRocks) and Toku.
‘@Attila
Default syncdelay is 60 sec which I find is too small, so in a write-heavy workload the engine ends up doing checkpointing all the time non-stop.
I think 900 sec is a reasonable compromise that still gives acceptable recovery time and engine does not need to be in checkpointing state all the time.
In this benchmark I however tried syncdelay=60 and the result is practically the same.
If the result was the same with 60 sec. it means that the checkpointing plays no role here (maybe worth to try a low number instead). Would be interesting to see the IO stats of the OS. It could be OS or HW level issue. Filesystem, volume manager, blockdevice settings or OS dirty cache flush driven direct IO. In your previous test linked in the post, the performance is constant, (still with the drops, but constant.) There are/were BUGs in wiredTiger around bad throughput but they are related to oplog functionality, how wiredTiger is mocking capped collections, this part mostly should be worked around in mongodb 3.2 but the ticket you linked supports this. Still i would say this is OS related.
‘@leafonsword
If you can point to an official MongoDB documentation how to enable LSM mode for WiredTiger and more interesting how to tune it for an insert intensive workload
that would be much helpful.
Vadim, I am willing to bet a large amount of beer that the “stall periods” that you are seeing are not on MongoDB side but rather represent a bottleneck in your SSD. I would recommend you to run an iometer load test on the same hardware with a similar stress pattern (aggressive random writes), and you will see that the load test will periodically stall because your SSD gets overwhelmed and takes a time out.
There were several bugs opened for WT stalls in the 2.6/3.0 release cycle. Here is one still open for 3.2.
https://jira.mongodb.org/browse/SERVER-16575
‘@Dennis,
Soon I will show benchmarks with RocksDB and PerconaFT where under the same workload there is no stalls.
‘@Dennis,
In addition to that, you really need to try very hard to overwhelm Intel SSD DC P3600 with writes. It is not some consumer grade cheap SATA SSD.
So, I invite you to come to https://www.percona.com/live/data-performance-conference-2016/ and let’s talk about large amount of beer there.
Based on the specs, this Intel PCI flash can do like 56.000 random writes a second (peak in a well distributed workload, with many threads, i assume). Which is a lot, though at least in the beginning of the tests you are doing a lot more than that in MongoDB. And we can say that is by design behavior of MongoDB,(arguably unlucky it is doing lots of random ios), but for sure at 300k ops, you saturate the SSD card.
An iops on a disk is not necessarily what mongo/os/filesystem is doing when it processes and batches writes. I would bet large amount of sparkling water that checking iostat -x 1 would show the drive not really being saturated.
Why no details? What was your iibench config? Not even any info about how many threads were doing insert? Nothing about how disk was configured? xfs? ext4 is not recommended by mongodb docs and xfs is. was journal on separate device? why did you turn off journal compression? If results are practically the same with default settings, why not measure default settings that the rest of the world use?
Vadim, Can you post the /etc/mongod.conf that you used for the test involved WiredTiger ?
Van,
I do not use mongo.conf
My command line is
numactl –interleave=all ./mongod –dbpath=/mnt/i3600/mongo/ –storageEngine=wiredTiger –syncdelay=900 –wiredTigerCacheSizeGB=10 –wiredTigerJournalCompressor=none
Was the size of the inserted collection + indexes larger than ram? We typically see these kinds of things when the working set (used% and/or dirty% via mongostat) get above 80%, which is where the default config stutters. Interestingly enough in my testing the disk is not the limiting factor in the sense that a 4k write benchmark via fio or whatever can push the disk quite a bit more.
(crossposted from the dzone article too)