
“There’s no benchmark for how life’s “supposed” to happen. There is no ideal world for you to wait around for. The world is always just what it is now, it’s up to you how you respond to it.”
― Isaac Marion, Warm Bodies
At one time or another, most of us have heard some version of this question: “Sure the system does fine in the benchmarks, but can it perform in production?”. Benchmark software developers have tried to address this issue in their systems. Features such as configurable workloads and scripting interfaces help to tailor benchmarks to various scenarios, but still require an expert to properly implement them.
The LinkBench benchmark was developed by Tim Armstrong with the guidance and help of a team from Facebook during his internship there. It takes a different approach to the challenge of simulating the real world. LinkBench is designed from the ground up as a replica of the data operations of Facebook’s social graph. By implementing an identical data model along with business methods and workloads directly proportionate the those used in the production social graph, LinkBench can effectively duplicate the data load that will be seen in a production social networking application.
Anatomy of a Social Graph – The Data Model
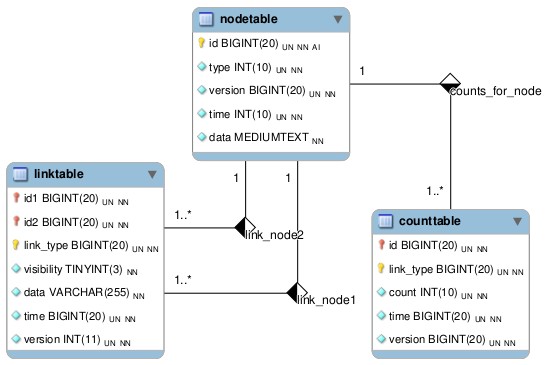
With this deceptively simple schema, a very robust application can be built.
The nodetable defines an object or end-point within the social graph. Examples of nodes include users, posts, comments, replies, albums, photos, groups, etc… The node’s type attribute is the magic that determines what the node represents and the data attribute contains the object itself (up to 16mb).
The linktable is a generic association or bridge table allowing any two nodes to be associated in some way. The secret sauce in this case, is the link_type attribute which represents a specific relationship between any two nodes. Examples of links include users being friends, a user liking a post, a user that is tagged in a photo and so on.
The third table, counttable is very important for performance and scalability in a social network. It maintains counts of a given link type for a node. Counts are transactionally updated whenever an operation that could potentially alter the count occurs. This small investment in the form of an additional write operation pays off by allowing for quick access to the number of likes, shares, posts, friends and other associations between nodes. Without the count table, the application would have to continuously query the database to retrieve up-to-date count information for various relationships creating a tremendous amount of system load.
The Social Graph Controller
As you can see, the model is very simple. The real magic in the social graph lies in the controller. LinkBench simulates the controller<->model interface through it’s workload configuration. The included configuration is based on actual production measurements of data payload size and distribution, node and link ‘temperature’ (popularity) and logged operation mix over a period of days.
A Social Graph In Use
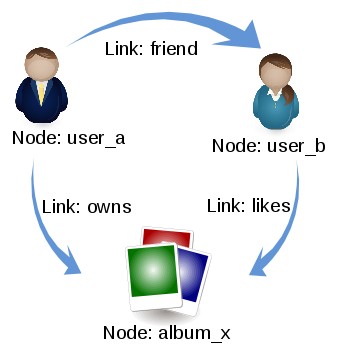
LinkBench is designed to be customizable and extensible in order to test new persistence technologies and architecture designs. A new database plugin can be developed by extending the abstract class com.facebook.LinkBench.LinkStore and/or implementing the interface com.facebook.LinkBench.NodeStore. There is also a combination com.facebook.LinkBench.GraphStore class that can be sub-classed for a combination of both LinkStore and NodeStore. One disadvantage of the current implementation is that it is up to the plugin developer to follow all of the business requirements of the social graph in the plugin. This requires careful auditing of each plugin to insure that it has been implemented to specification. To assure a 1-to-1 parity with the MySQL plugin, I used it as a base and converted the methods to MongoDB one at a time carefully translating each operation.
Along the way, I’ve learned a lot about NoSQL and MongoDB in particular and dispelled a few myths that I had about NoSQL. I will save that for another article. Let me talk about a few design decisions I made while implementing the plugin.
In Part 2 I will dive into the LinkBench Java code a bit to show the comparison between the MySQL plugin the MongoDB plugin.
Resources
RELATED POSTS





Thanks for doing this
Your welcome Mark, thanks for a great benchmark from you and your team.
Assuming that you had a very similar data model (but with some more FKs on nodetable) and that you had reasons to read from nodetable (especially with range queries) other than getting at the data column, would it be better to move the data column to its own table with the same ID column? The off-page storage is still confusing to me and I wish it was possible to control this when creating a table.
‘@Karl, If your goal is to retro-fit a social graph into an existing application then you could simply add a foreign key to the node that would reference the legacy object. You could also expose other fields into indexed columns or FT text column serialized in a format that would allow advanced searches.
For scalability, the white paper discusses sharding on node.id and link.id1 (they are kept together). Also, the controller has some flexibility to shard related objects together (for instance, a user and their photos). The replication strategy that is mentioned is single RW master with multiple RO instances that are organized geographically.
The risk of off-page storage for the data column is extra random storage reads to get to the data column. A big win many years ago for the production workload was to put the ‘data’ column into the secondary index on the linktable because range scans on it are very popular and adding the column made the index covering. That significantly reduce the random disk read load.