

Percona Operator for MySQL PXC 1.20.0 is out today, and it addresses three long-requested operational headaches: storage that grows on its own before it fills up, TLS certificates that rotate without cluster downtime, and images that run natively on ARM64.
Disk-full incidents on PXC clusters often arrive at 2 AM when monitoring alerts fire, and someone has to manually expand PVCs before writes grind to a halt. Certificate rotations have traditionally meant a carefully timed series of kubectl edits with real downtime risk. And ARM64 hardware has been increasingly common in dev clusters and cost-optimized cloud node pools, where x86-only images created extra friction. 1.20.0 addresses all three in a single release.
In this post, you’ll learn about:
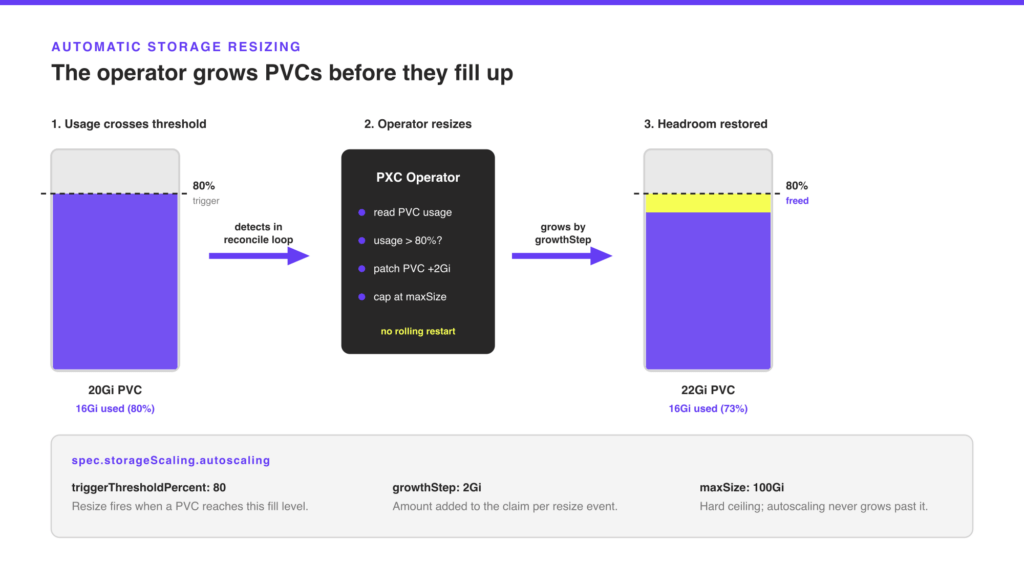
A full data volume is the most common cause of unplanned maintenance on a PXC cluster. Until now, avoiding it required external monitoring, manual kubectl patch pvc steps, and waiting for the storage class to honor the resize. Even with good alerting, the operator itself had no mechanism to react: it could only expand PVCs when you changed the spec by hand.
1.20.0 introduces built-in storage autoscaling. The operator polls each PVC’s actual disk usage, and when usage crosses a configured threshold, it automatically expands the claim. You set the trigger percentage, the step size per resize event, and an optional upper bound. The operator handles everything else.
The autoscaler runs inside the normal reconcile loop. It reads status.capacity.storage from each PXC PVC, compares current usage against triggerThresholdPercent, and issues a PVC resize when the threshold is crossed. It sets a percona.com/pvc-resize-in-progress annotation on the CR while an expansion is active. This annotation blocks concurrent rolling restarts or upgrades from starting, so nothing disrupts the cluster mid-resize.
You can also set enableExternalAutoscaling: true if an external tool, such as KEDA, already manages PVC sizes for your cluster. When you enable external autoscaling, the built-in loop skips its resize check entirely to avoid conflicts.
Add storageScaling to your PerconaXtraDBCluster spec:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
apiVersion: pxc.percona.com/v1 kind: PerconaXtraDBCluster metadata: name: cluster1 spec: crVersion: 1.20.0 storageScaling: enableVolumeScaling: true autoscaling: enabled: true triggerThresholdPercent: 80 # resize when a PVC is 80% full growthStep: 2Gi # add 2Gi per resize event maxSize: 100Gi # never grow beyond 100Gi per PVC # enableExternalAutoscaling: false |
Any PVC expansion requires enableVolumeScaling: true, whether the autoscaler or a manual spec change triggers it. Setting autoscaling.enabled: true enables the threshold-based path on top of that. Leave the autoscaling block out if you only want to permit manual spec-driven resizes.
Storage expansion requires a StorageClass with allowVolumeExpansion: true. Check before enabling:
|
1 2 |
kubectl get storageclass \ -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.allowVolumeExpansion}{"\n"}{end}' |
Autoscaling applies only to PXC data volumes. If your storage class or CSI driver handles expansion externally, use enableExternalAutoscaling: true to prevent the two mechanisms from racing.
Rotating TLS certificates on a live PXC cluster has always carried risk. The Galera protocol requires all nodes to trust each other’s CA simultaneously. Swap the CA on one node before the others accept it, and inter-node communication breaks. The safe approach requires a three-phase CA swap with rolling restarts between each phase: a process that is easy to get wrong under time pressure.
1.20.0 formalizes this into a first-class operator workflow. Create a Secret named <ssl-secret>-new containing the replacement credentials, and the operator runs the full three-phase rotation automatically, pausing for rolling restarts between each step.
The rotation proceeds in three steps that the operator coordinates:
When step 3 completes, the operator automatically deletes the -new Secret. The cluster never loses TLS connectivity between nodes during the process.
Given a cluster named cluster1 using the default SSL Secret cluster1-ssl, create the replacement:
|
1 2 3 4 |
kubectl create secret generic cluster1-ssl-new \ --from-file=ca.crt=new-ca.crt \ --from-file=tls.crt=new-server.crt \ --from-file=tls.key=new-server.key |
You do not need to change the PerconaXtraDBCluster CR. The operator detects the -new Secret on the next reconcile and starts the rotation. No kubectl patch on the CR, no operator restart.
The operator does not yet surface rotation progress in .status.conditions. Monitor the rotation by watching PXC pods restart in sequence and checking that the -new Secret is eventually gone:
|
1 2 |
kubectl get pods -w -l app.kubernetes.io/component=pxc kubectl get secret cluster1-ssl-new # should 404 when rotation is complete |
AWS Graviton3, Google Axion, and Azure Cobalt100 instances deliver better price-to-performance on memory-intensive workloads like PXC. Previously, running the operator on ARM64 nodes required cross-architecture scheduling workarounds or explicit node exclusions for operator pods. All PXC operator images now publish native linux/arm64 layers alongside nodeSelector
Every image in the PXC operator stack ships multi-arch manifests in 1.20.0:
This release also fixes a logrotate crash on ARM64 (K8SPXC-1821) that a missing dependency in the ARM64 container layer caused. 1.20.0 ships the fix.
You do not need any configuration change. Pull the 1.20.0 operator image and Kubernetes schedules it on whichever architecture is available. To pin PXC pods explicitly to ARM64 nodes, add a nodeSelector or node affinity in the spec.pxc block:
|
1 2 3 4 |
spec: pxc: nodeSelector: kubernetes.io/arch: arm64 |
Deprecation notice: PMM2 monitoring integration is deprecated in 1.20.0. Migrate to PMM 3 before version 1.22.0, when PMM2 support will be removed.
PXC Operator 1.20.0 turns three previously manual steps into operator-managed concerns: disk growth, certificate rotation, and ARM64 scheduling. Combined with PITR validation improvements and configurable leader election, this release reduces the operational surface area for clusters running under production pressure. If you run into edge cases with automatic storage resizing or TLS rotation, the community forum is the right place to share them.
Resources
RELATED POSTS




