
Many software developers find they need to store hierarchical data, such as threaded comments, personnel org charts, or nested bill-of-materials. Sometimes it’s tricky to do this in SQL and still run efficient queries against the data. In this blog, I’ll describe several solutions for storing and querying trees in an SQL database, including the design I call Closure Table.
In Closure Table, we store every path in a tree, not only direct parent-child references, but also grandparent-grandchild, and every other path, no matter how long. We even store paths of length zero, which means a node is its own parent. So if A is a parent of B, and B is a parent of C and C is a parent of D, we need to store the following paths: A-A, A-B, A-C, A-D, B-B, B-C, B-D, C-C, C-D, D-D. This makes it easy to query for all descendants of A, or all ancestors of D, or many other common queries that are difficult if you store hierarchies according to textbook solutions.
CREATE TABLE TreePaths (
ancestor CHAR(1) NOT NULL,
descendant CHAR(1) NOT NULL,
length INT NOT NULL DEFAULT 0,
PRIMARY KEY (ancestor, descendant)
) ENGINE=InnoDB;
Because there isn’t much written about using the Closure Table design, I periodically get questions about how to solve certain problems. Here’s one I got this week (paraphrased):
I’m using Closure Table, which I learned about from your book and your presentations. I can neither find nor invent a pure-SQL solution for moving a subtree to a new position in my tree. Right now, I’m reading the nodes of the subtree into my host script, deleting them and re-inserting them one by one, which is awful. Are you aware of a more efficient solution for moving a subtree in this design?
Moving subtrees can be tricky in both Closure Table and the Nested Sets model. It can be easier with the Adjacency List design, but in that design you don’t have a convenient way to query for all nodes of a tree. Everything has tradeoffs.
In Closure Table, remember that adding a node involves copying some of the existing paths, while changing the endpoint for descendant. When you’re inserting a single new node, you just have one descendant to add, joined to all the paths of its ancestors.
Here’s a diagram of a skinny tree lying on its side. A is the root of the tree, and C is the leaf. We want to add new node D.
A -> B -> C …add… D
The Closure Table already has paths A-A, A-B, A-C, B-B, B-C, C-C. You want new paths A-D, B-D, C-D, D-D. Basically you need to copy any path terminating with C (the immediate parent of D), and change the endpoint of that path to D.
That is, copying A-C, B-C, C-C and changing the right C to D gives A-D, B-D, C-D. Then add your reflexive path D-D manually.
INSERT INTO TreePaths (ancestor, descendant, length)
SELECT t.ancestor, 'D', t.length+1
FROM TreePaths AS t
WHERE t.descendant = 'C'
UNION ALL
SELECT 'D', 'D', 0;
The above is the simple case of adding a single new node.
When you insert a subtree, you’re inserting multiple nodes, and you want to create new paths for each one, as many new paths as the number of ancestors of the new location times the number of nodes in the subtree. Suppose A has another child F, and below F we have a subtree D -> E (see illustration):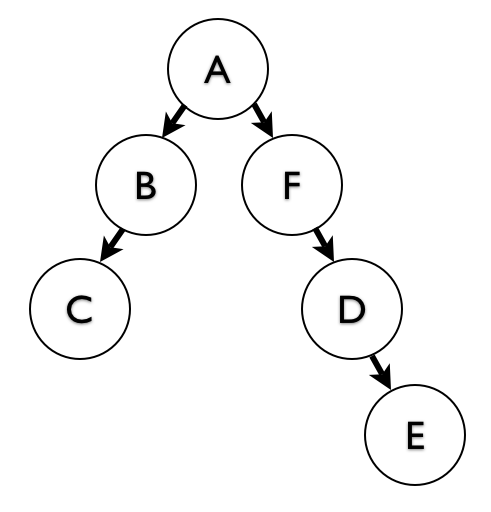
We want to move the subtree starting at D, and place it under B.
Before we move the subtree, we need to disconnect it from its old position in the tree. Delete the outdated paths for the old location of the D subtree (but not the intra-subtree paths). Conceptually, we might try the following SQL statement:
DELETE FROM TreePaths
WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = 'D')
AND ancestor NOT IN (SELECT descendant FROM TreePaths WHERE ancestor = 'D');
But MySQL complains: “You can’t specify target table ‘TreePaths’ for update in FROM clause.” We can’t DELETE and SELECT from the same table in a single query in MySQL. But we can use MySQL’s multi-table DELETE syntax, to find any path that terminate at a descendant of D, but only if the path’s start isn’t also a descendant of D. We do this by using an other join to try to find a third path, starting from D and terminating at the start of the path we want to delete. Only delete when no such third path is found.
DELETE a FROM TreePaths AS a
JOIN TreePaths AS d ON a.descendant = d.descendant
LEFT JOIN TreePaths AS x
ON x.ancestor = d.ancestor AND x.descendant = a.ancestor
WHERE d.ancestor = 'D' AND x.ancestor IS NULL;
That deletes paths that terminate within the subtree (descendants of D), but not paths that begin within the subtree (paths whose ancestor is D or any of descendants of D). So it deletes A-D, A-E, F-D, F-E, but not D-D, D-E, E-E.
To insert the subtree under its new location, we want new paths A-D, B-D, C-D, D-D as well as A-E, B-E, C-E, and D-E. We already have D-E, you just have to not lose that path in the process of moving (same applies to any other intra-subtree paths if it’s larger than just this simple example). We also already have D-D and E-E and any other reflexive paths.
If we were inserting just a single new node, we would hardcode ‘D’ as the id of the new node. But now we need to insert all the nodes of the subtree. We use a Cartesian join between the ancestors of B (going up) and the descendants of D (going down).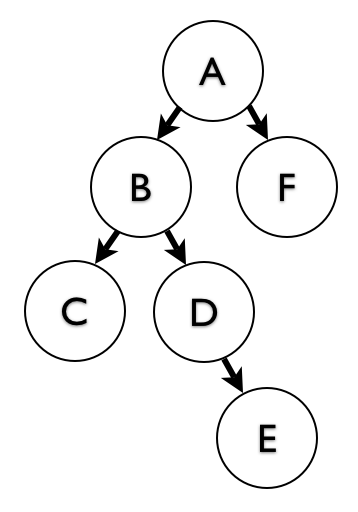
INSERT INTO TreePaths (ancestor, descendant, length)
SELECT supertree.ancestor, subtree.descendant,
supertree.length+subtree.length+1
FROM TreePaths AS supertree JOIN TreePaths AS subtree
WHERE subtree.ancestor = 'D'
AND supertree.descendant = 'B';
This inserts A-D, B-D, A-E, B-E. We already have D-D, D-E, E-E since we’re moving an existing subtree. See the second illustration for the result.
Basically, for both deleting outdated paths and adding new paths, we can imagine a kind of boundary separating the subtree from the rest of the tree. You’re concerned with changing paths that cross over that boundary. Everything else takes care of itself.
I also wrote about Closure Table in my book, SQL Antipatterns: Avoiding the Pitfalls of Database Programming.




