
Note: In the original version of this post, there were some issues missed. These have been addressed at the bottom of the post.
I’d like to introduce to you a very cool feature introduced in PostgreSQL, the Pipeline Mode.
So just what exactly is Pipeline Mode? Pipeline Mode allows applications to send a query without having to read the result of the previously sent query. In short, it provides a significant performance boost by allowing multiple queries and results to be sent and received in a single network transaction.
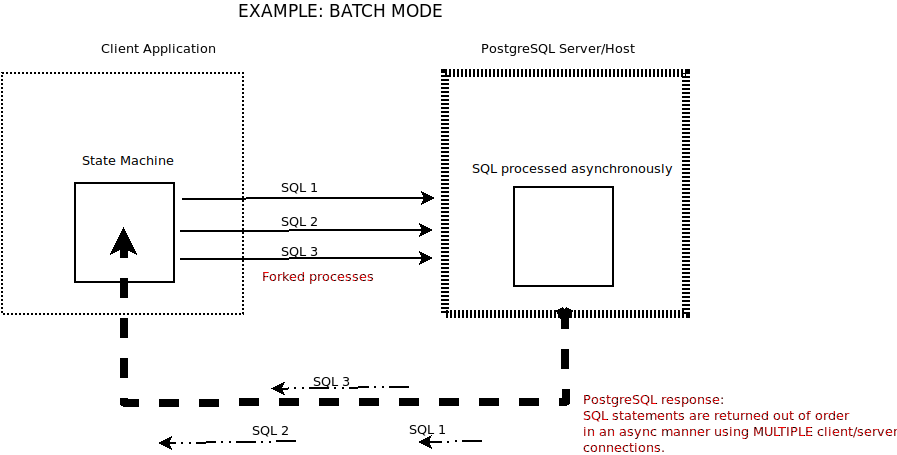
As with all good ideas, there is precedent: one can emulate such behavior with a little application code wizardry. Alternatively known as “Batch Mode”, running asynchronous communications between a client and its server has been around for some time. There are a number of existing solutions batching multiple queries in an asynchronous fashion. For example, PgJDBC has supported batch mode for many years using the standard JDBC batch interface. And of course, there’s the old reliable standby dblink.
What distinguishes Pipeline Mode is that it provides an out-of-the-box solution greatly reducing the application code’s complexity handling the client-server session.
Traditional BATCH MODE Operations
Pipeline Mode
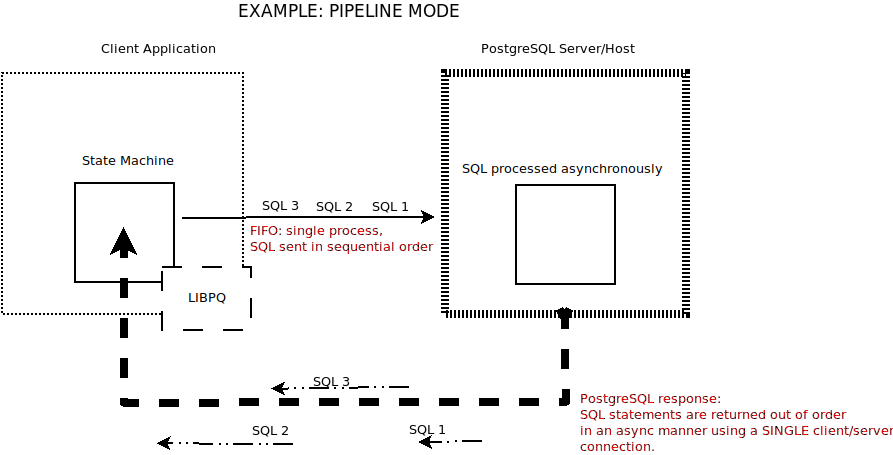
Although introduced in PostgreSQL 14, pipeline mode works against any currently supported version of postgres as the enhancement is in the LIBPQ which is used by the client and not the server itself!
And now for the bad news, of a sort; leveraging Pipeline Mode requires using “C” or an equivalent programming language capable of interfacing directly with LIBPQ. Unfortunately, there’s not too much out there yet in the way of ODBC development offering the requisite hooks taking advantage of this enhanced feature. Therefore, one is required to design and program the client-application session in the said programming language.
HINT: This is a great way for somebody to make a name for themselves and create a convenient interface to the LIBPQ Pipeline Mode.
Now that I’ve issued the requisite caveat, let’s talk about how this mechanism works.
Keeping things simple
Since each SQL statement is essentially idempotent it is up to the client logic to make sense of the results. Sending SQL statements and pulling out results that have no relation with each other is one thing but life gets more complicated when working with logical outcomes that have some level of interdependence.
It is possible to bundle asynchronous SQL statements as a single transaction. But as with all transactions, failure of any one of these asynchronously sent SQL statements will result in a rollback for all the SQL statements.
Of course, the API does provide error handling in the case of pipeline failures. In the case of a FATAL condition, when the pipeline itself fails, the client connection is informed of the error thus flagging the remaining queued operations as lost. Thereafter normal processing is resumed as if the pipeline was explicitly closed by the client, and the client connection remains active.
For the C programmer at heart, here’s a couple of references that I can share with you:
Remember to check with the postgres documentation which has more to say here.
Hello all, apologies for the tardy reply. I wrote this blog just before leaving on a company adventure into the Mountains of Ecuador at the beginning of February. It’s taken me a while to catch up since my return and I’d like to address some of the comments posted here as well as elsewhere.

The funny thing about blogged comments is although we’re always looking for approval that tells us that we’re doing our job, sometimes we realize that there are issues that have been missed and need to be addressed a little more in-depth.
The first thing that needs to be said is in the way of a correction to the blog posting i.e. after SQL statements have been sent, responses from the postgres server DO NOT come back out of sequence-based upon their completion. Although SQL statements can be sent in a non-blocking manner, once they arrive at the server they are handled and returned in a sequential manner.
Doing a little online research brought us to this little gem of a discussion, https://github.com/brianc/node-postgres/pull/2706, that says it quite nicely:
“Important: pipelining has nothing to do with query execution concurrency/parallelism. With or without pipe-lining mode, the PostgreSQL server is executing the queries sequentially (while using parallelism capabilities if enabled), pipe-lining just allows both sides of the connection to work concurrently when possible, and to minimize round-trip time.”
The pipeline essentially makes the network file descriptor non-blocking allowing the client to submit multiple requests in a non-blocking way. All the requests are going through the same SOCK_FD and the client needs now to monitor the associated SOCK_FD (select, poll, epoll, io_uring, kqueue, etc…).
Putting it another way “Pipeline mode allows us to send everything as a train” making pipeline mode a definite plus in situations where the Round-Trip Time (RTT) is significant.
We validated the observations using two methods; the first, and easy way, was running pgbench in pipeline mode and yes it does support it in postgres 14. The second method was looking into the libpq source code while running some simple queries.
Here’s an example of what I mean; suppose we send a series of queries with SELECT pg_sleep() having alternating values of one second and a higher value. Query 1, with a sleep of one second, returns right away, and query 2 returns twenty-seven seconds after that. But query 3 is blocked until after query two completes. The other ones follow the same execution pattern returning only after the previous query has fully cycled. And even though they are immediately sent to the server they still return sequentially:
|
1 2 3 4 5 6 7 8 9 |
Query 1: SELECT repeat('0', 10), pg_sleep(1) -- returns after 1 second Query 2: SELECT repeat('1', 10), pg_sleep(27) -- returns after 1+27 seconds Query 3: SELECT repeat('2', 10), pg_sleep(1) -- returns after 1+27+1 seconds Query 4: SELECT repeat('3', 10), pg_sleep(21) -- returns after 1+17+1+21 seconds Query 5: SELECT repeat('4', 10), pg_sleep(1) -- returns after 1+17+1+21+1 seconds |
Another way of putting it is to say that if the second SQL statement takes longer than all the other ones following it’s still going to be returned as the 2nd query and NOT the last one to return i.e. sequential rather than async.
I’ll be honest and say that this was a fast investigation so it’s easy to have missed something.
In conclusion, I’d like to compliment Alvarro and the team working on this technology. It holds great promise but overall, at this point in time at least, deciding to use this mechanism makes sense for very specific use cases.





Does this work with the extended query protocol or only with the simple query protocol? For some reason I was thinking that only the simple query protocol supported multiple statements, which – if accurate – would mean there are a bunch of additional caveats (eg. it would be incompatible with bind var usage of that requires extended protocol).
https://www.postgresql.org/docs/current/protocol.html
> For some reason I was thinking that only the simple query protocol supported multiple statements
This is partially accurate. The “Parse” message only supports one SQL statement but the extended protocol supports multiple parse messages and this is the “trick” used by libpq. Every SQL statement is enclosed in its own “Parse, Bind, portal Describe, Execute, portal Close” but without the “Sync”. Libpq will concatenate all the SQL statements sent via “PQsendQuery” and will add the “Sync” message in the end of the string as the last message/command. It’s quite a smart trick I would say.
Switching the connection to PIPELINE mode is something that the backend is aware of (For example sending an additional command) or completely handled in the client side? I hope my question is clear
Not really. Switching to pipeline mode is mostly about the client *not* sending SYNC messages (at the protocol level) after each SQL statement. See https://www.postgresql.org/docs/current/protocol-flow.html
That’s not totally accurate. The client protocol always send the SYNC (“S”) message. What happens is that the “PQpipelineSync” command from libpq dispatches the queries in memory. For example, if I have the below code it will send the whole message with every single time:
char fmt[40] = "INSERT INTO t2 VALUES(%d)";
char sql[40];
for (int i = 0; i < 5; i++)
{
sprintf(sql, fmt, i);
printf("Query: %sn", sql);
fflush(stdout);
if (!PQsendQuery(conn, sql))
{
printf("Failed to send statement "%s" to database", sql);
continue;
}
if (!PQpipelineSync(conn))
{
printf("Failed while running PQpipelineSync");
continue;
}
}
If I remove the "PQpipelineSync" from the loop and put it outside then it will behave like you described but with one detail, the libpq will send all the queries in one single call with a big SQL, something like:
INSERT INTO t2 VALUES(0);INSERT INTO t2 VALUES(1);INSERT INTO t2 VALUES(2);INSERT INTO t2 VALUES(3);INSERT INTO t2 VALUES(4
);
Which should be something like below at the protocol level:
Well it shouldn’t be a problem and as we are sending multiple statements at the same time we are saving network round trip so always preferable right? Not really. When we aggregate those statements we are sending them all in a single transaction, and if for example the ID=3 is duplicated they will all fail causing a full rollback. This is not a problem in itself, but it can be very harmful to the application if the application was expecting them to work as individual isolated transaction. The former option, sending them individually, will not have this issue and only the failed one will be rolled back. Note that it’s not the case of one be better than another, they are just different and have different implications, and it’s very important for the developers/designers take them into consideration while using either option.
In time, the ability to send queries asynchronously has been around for a long time and one can easily use them and completely bypass pipeline mode with similar results.
Pipelining works only with the extended query protocol. You’re right that only the simple query protocol allows multiple statements in the same query (separated by semi-colons). But pipelining is a different way of sending multiple statements efficiently, without stringing them together in the same query. Each statement is distinct but they’re grouped as a series at the network level.
Not sure I understood what you mean here when you say: “But pipelining is a different way of sending multiple statements efficiently, without stringing them together in the same query. Each statement is distinct but they’re grouped as a series at the network level”. Pipeline does exactly the oposite if we don’t call “PQpipelineSync” at every query execution.
What it does is to use the PGconn->outBuffer to concatenate all the queries we send through “PQsendQuery” and then when we call “PQpipelineSync” it will invoke “PQflush” which will send all the concatenated queries inside “PGconn->outBuffer”.
Also, not sure what exactly the “grouped as a series at the network level” means. Do you mean packets? I can’t really see how that would be possible as the libpq isn’t only the origin of the communication but operates in a higher level protocol-wise than the packets, and if we want to do something at the network level we need to intercept and work with the packets at the transmission protocol level. But again, I don’t think I understood what you said and I’m just speculating here.
Please note that the pipeline diagram showing and saying that “SQL statements are returned out of order” is incorrect. The doc says: “The server executes statements, and returns results, in the order the client sends them”.
Got it. So it will only work with the extended query protocol, right? Thanks
Sorry, I meant to respond to your answer of my previous comment