
When building high-availability MySQL environments, the choice between MySQL Group Replication (GR) and Percona XtraDB Cluster (PXC) often comes down to how they handle the eternal database dilemma: data consistency versus performance. 
While both provide “synchronous-like” replication, they approach the problem of stale reads—reading data that has been committed on one node but not yet applied on another—in distinct ways. Understanding these differences, and the performance penalties associated with fixing them, is critical for any production environment.
MySQL Group Replication (GR)
Group Replication is the native, albeit more recent, high-availability solution built by Oracle for MySQL. It is based on a distributed state machine architecture and uses the Paxos consensus protocol.
Percona XtraDB Cluster (PXC)
PXC is an open-source enterprise solution based on Percona Server for MySQL and the Galera Replication library, which is the first and most mature virtually synchronous solution for MySQL.
The most critical distinction for developers is whether a SELECT query on Node B will immediately see the INSERT just performed on Node A.
In a distributed system, there is a microsecond-to-millisecond gap between a transaction being globally ordered (everyone knows it happened) and being locally applied (the data is physically readable in the table). Reading executed on a secondary during this gap results in a stale read.
While a stale read might just mean a user temporarily sees their old profile picture after updating it, in many business cases, it breaks the application’s core logic:
To prevent these scenarios, we must tell the database to enforce strict consistency. But how do GR and PXC handle this, and what does it cost?
Both Group Replication and Percona XtraDB Cluster provide built-in mechanisms to enforce consistency and eliminate stale reads when your application demands it. However, they approach this problem using entirely different variables and distinct levels of granularity. The table below breaks down the specific controls each technology offers, highlighting exactly what it takes to force a node to serve fresh data.
| Feature | MySQL Group Replication | Percona XtraDB Cluster |
|---|---|---|
| Default Behavior | Reads on secondaries may be stale because the applier thread might be lagging after consensus. | Reads on secondaries may be stale due to asynchronous background applying. |
| Stale Read Fix | Uses the group_replication_consistency variable. | Uses the wsrep-sync-wait variable. |
| Consistency Levels | Offers EVENTUAL, BEFORE, AFTER, and BEFORE_AND_AFTER. | Offers granular levels from 0 (default, no checks) up to 7 (checks on all READ, UPDATE, DELETE, INSERT, and REPLACE statements). |
| The Fix | Setting to AFTER ensures the next read is fresh. | Setting to 7 ensures we have a comparable scenario with GR. However in PXC setting wsrep_sync_wait = 1 will be enough to avoid stale reads. |
If we know stale reads are bad, why don’t we just enforce strict consistency everywhere?
An image can help to understand:
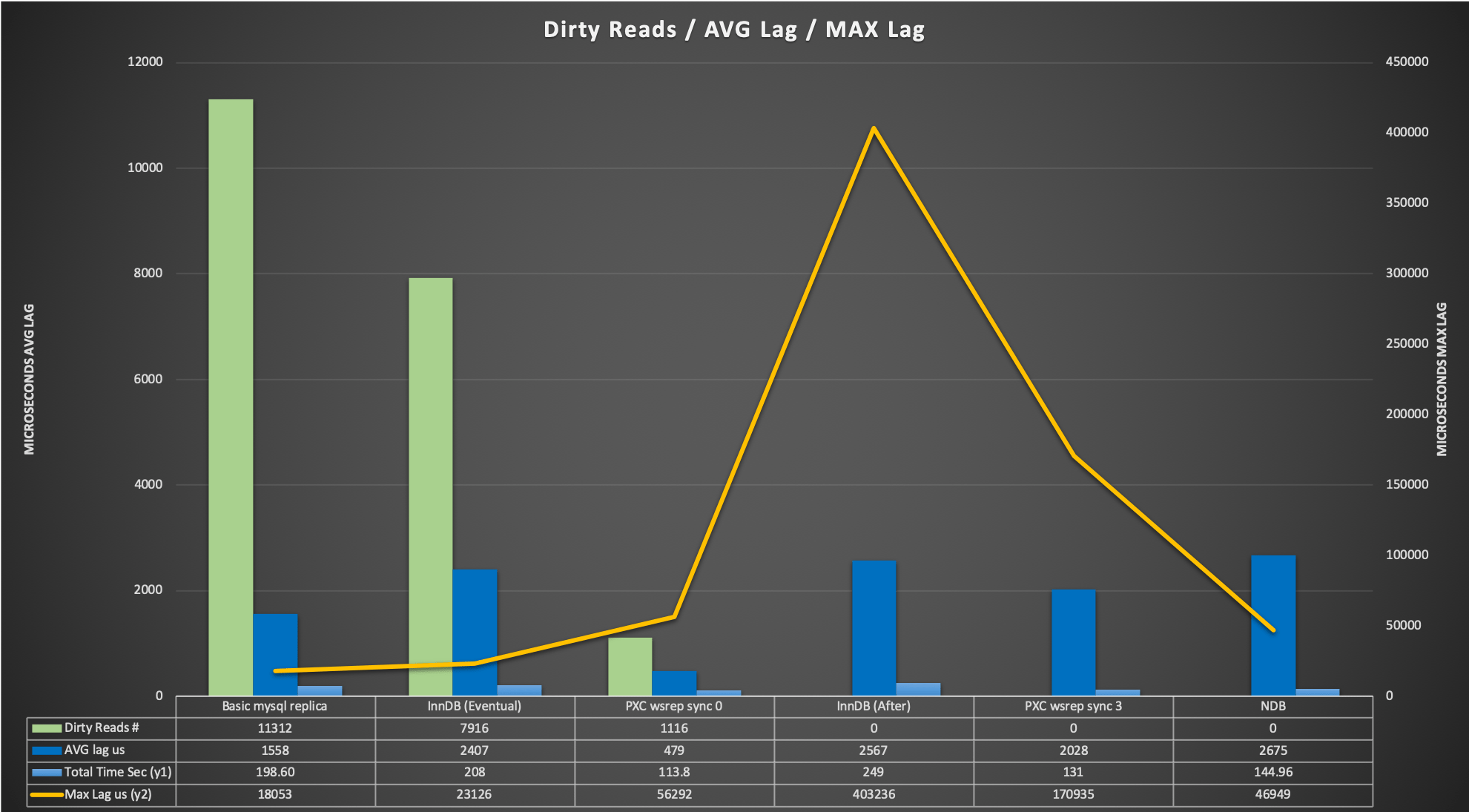
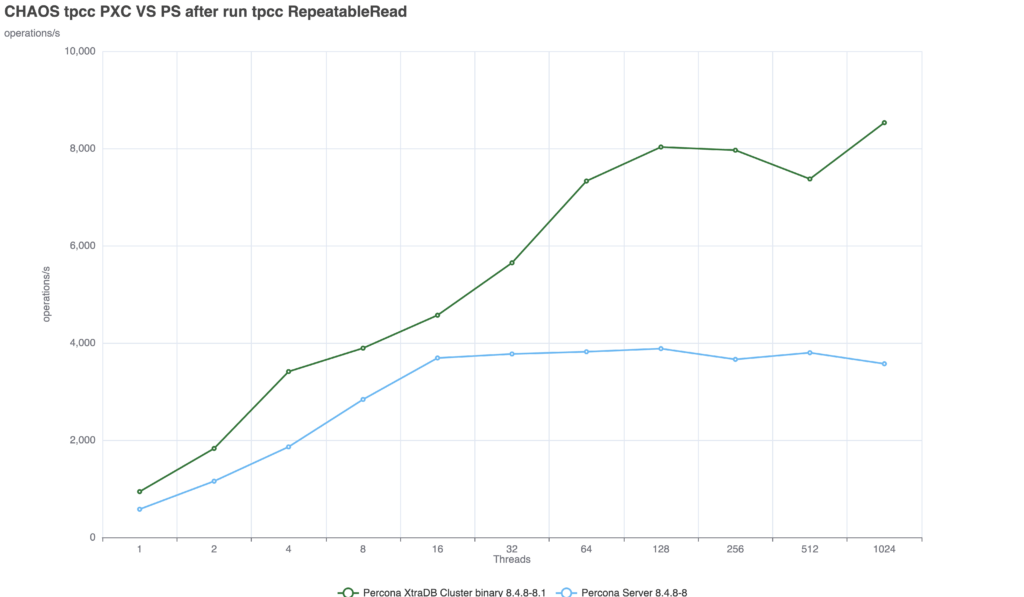
Because in distributed databases, consistency is incredibly expensive. To test this, we used a 3-node internal lab environment to run a Sysbench-based TPC-C derivative test (50/50 read/write split, running for 600 seconds, scaling from 1 to 1024 threads).
You can find the detailed machine specifications here. The benchmarks were executed using a TPC-C derivative test based on sysbench. Finally—and crucially—you can review the configuration files used for the tests. I maintained the same baseline MySQL configuration across the board, only adjusting the parameters specific to each replication technology.
(GR = EVENTUAL, PXC = wsrep-sync-wait 0)
I want to remind, that MySQL CE and Percona Server are running using Group Replication, while PXC is using galera.
With default settings, both systems allow stale reads.
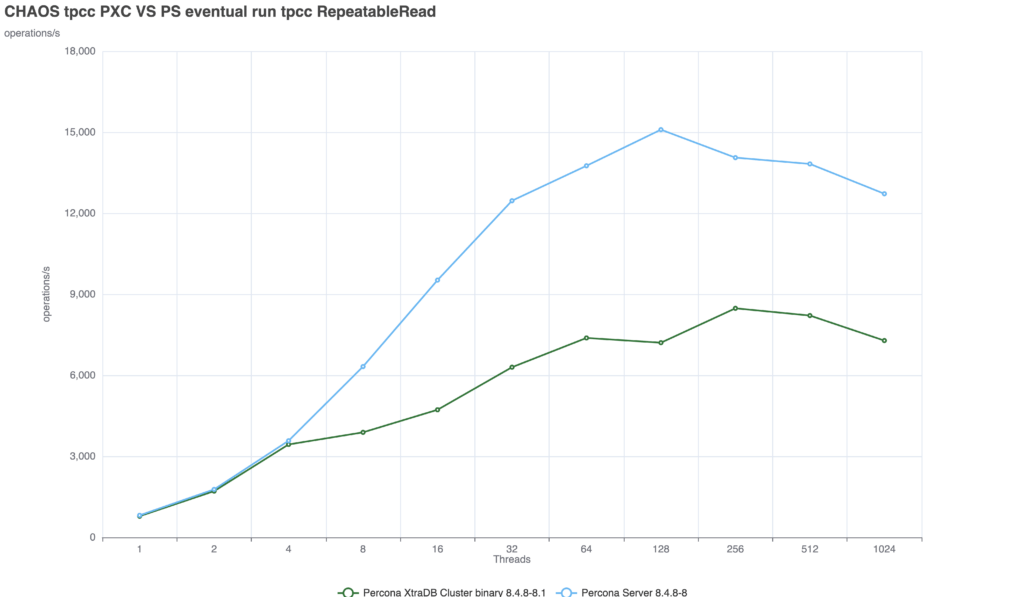
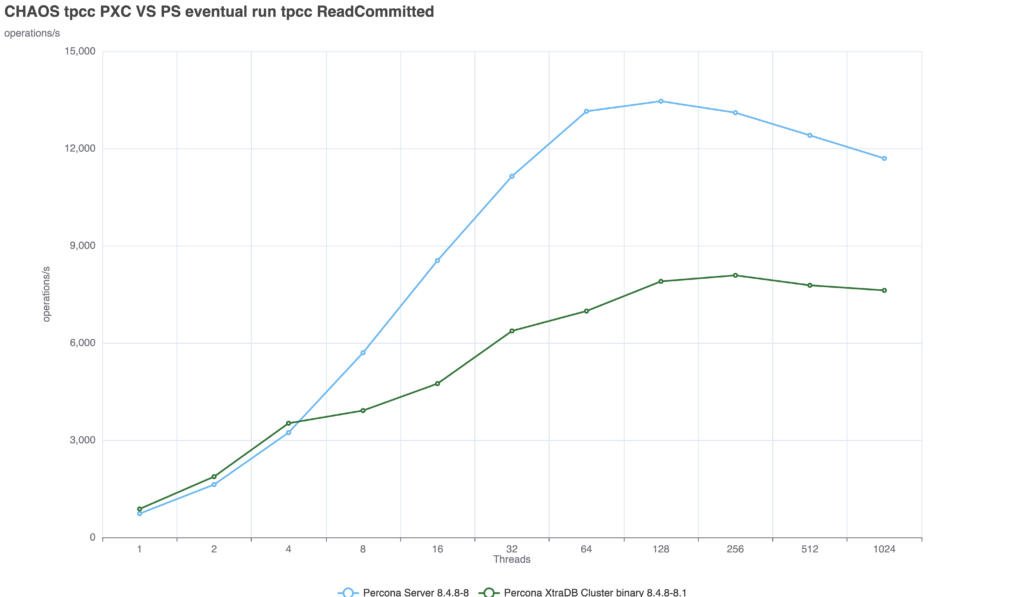
Both technologies scales well up to 128 threads:
At this level, the lag between the moment of commit and the moment the server returns the answer is minimal. But we are entirely exposed to stale reads.
(GR = AFTER, PXC = wsrep-sync-wait 7)
When we configure the servers to prevent stale reads, the systems must wait for transactions to be fully applied before returning a read. This is where the architectural differences become glaringly apparent:
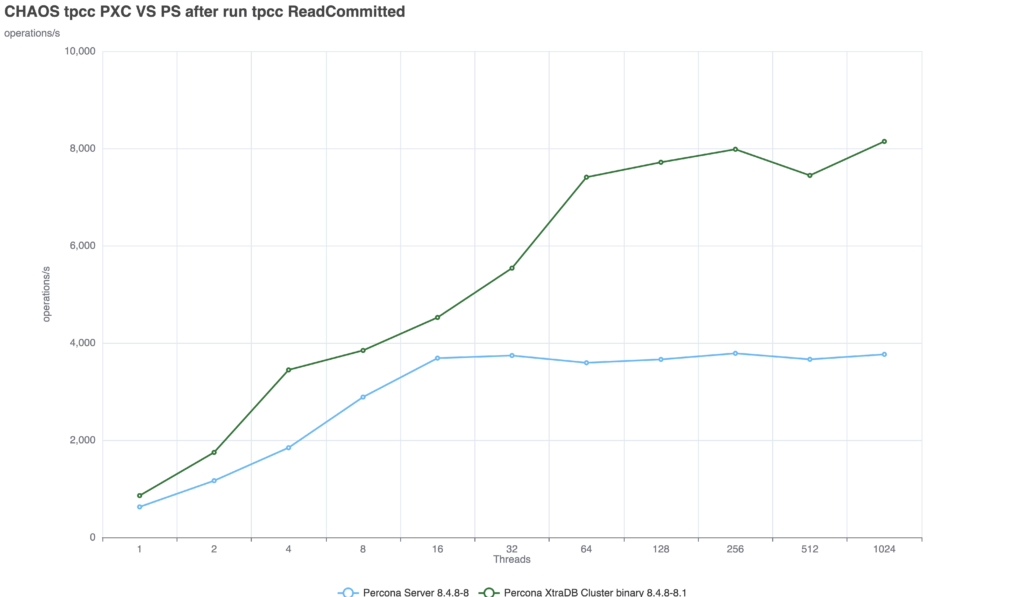
Enforcing strict consistency in Group Replication results in a massive ~75% performance penalty. The latency between the commit and the server response increases significantly compared to PXC.
There is another approach which is to inject the higher consistency only when it is really needed.
The Solution: Session-Level Consistency You do not need, and should not use, full consistency at the global level for general cases. Instead, force consistency only when and where it is critical.
While for Group Replication there is no support for SQL injection hints like SELECT /*+ SET_VAR(…) */, you can enforce this at the session level right before a critical read:
|
1 2 3 |
SET SESSION group_replication_consistency = 'AFTER'; -- OR for PXC: SET SESSION wsrep_sync_wait = 7; |
To note that PXC offers more flexibility and you can use hints:
|
1 2 3 4 5 6 |
select /*+ SET_VAR(wsrep_sync_wait=7) */ @@session.wsrep_sync_wait ,@@global.wsrep_sync_wait; +---------------------------+--------------------------+ | @@session.wsrep_sync_wait | @@global.wsrep_sync_wait | +---------------------------+--------------------------+ | 7 | 0 | +---------------------------+--------------------------+ |
By isolating these variables to specific sessions (like the immediate redirect after a password change or a checkout process), you ensure data integrity exactly where the business requires it, while allowing the rest of your application to enjoy the high-speed performance of relaxed consistency.
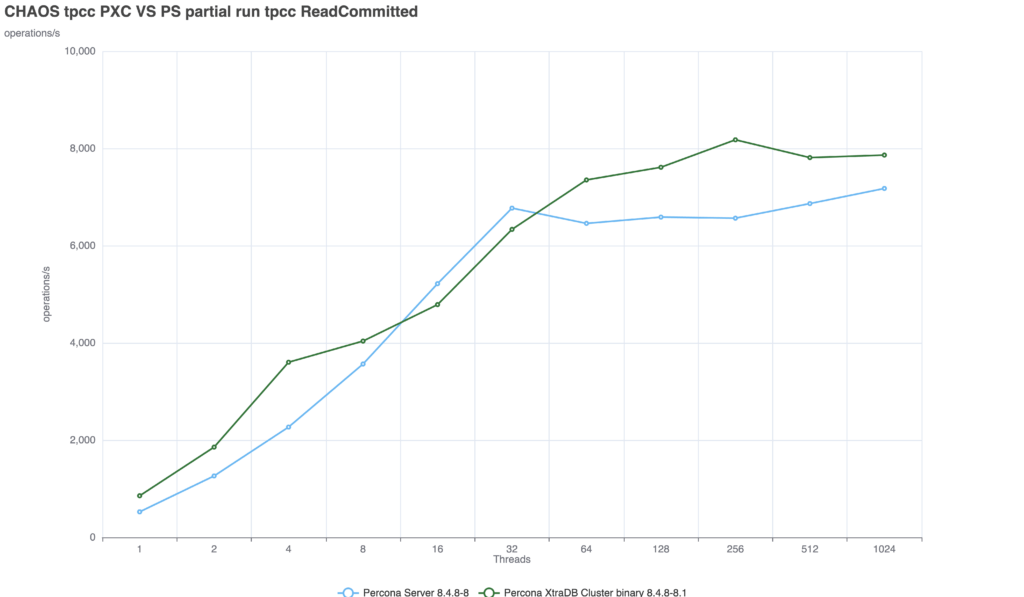
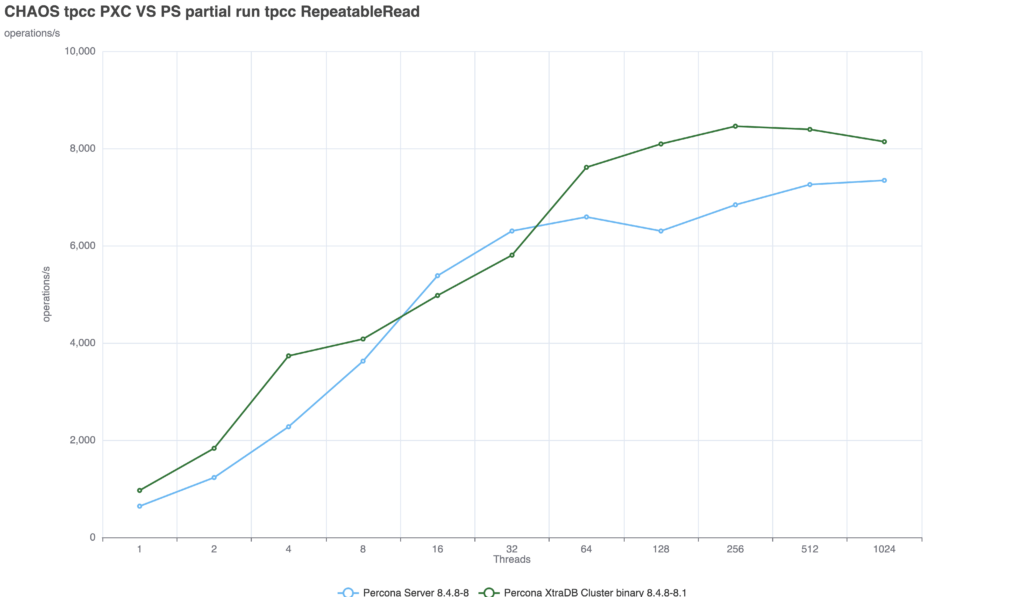
PXC: The performance drop is minimal and the solution is able to provide a consistent delivery with nice scalability up to 256 threads.
Group Replication: The solution suffers from a significant drop, not as if we set the AFTER condition at global level, but still we see a drop of ~52%.
Comparing the two solutions we can see that PXC is able to deal with the additional requested consistency better.
But these are not the only differences we can immediately see.
Performing a comparison about resources utilization, we can see that while both solutions move the same amount of data as IO operations:
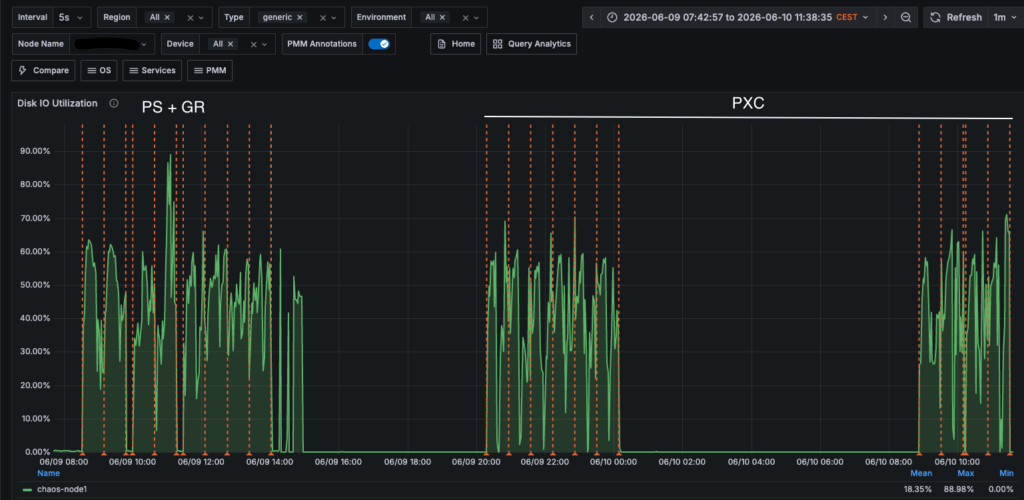
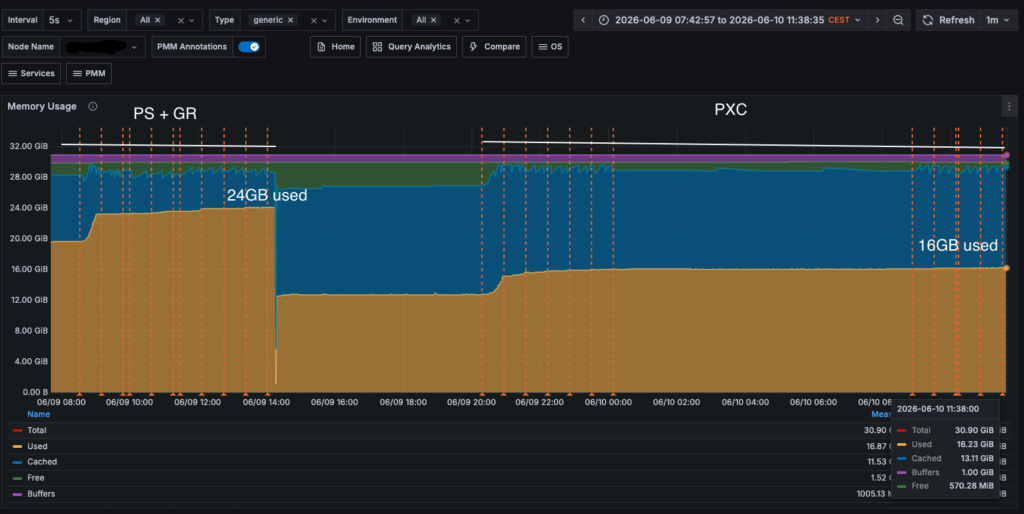
Yes, for exactly the same load and traffic Group Replication consumes 8GB more than PXC, which in this environment represents 26% memory more, over total available.
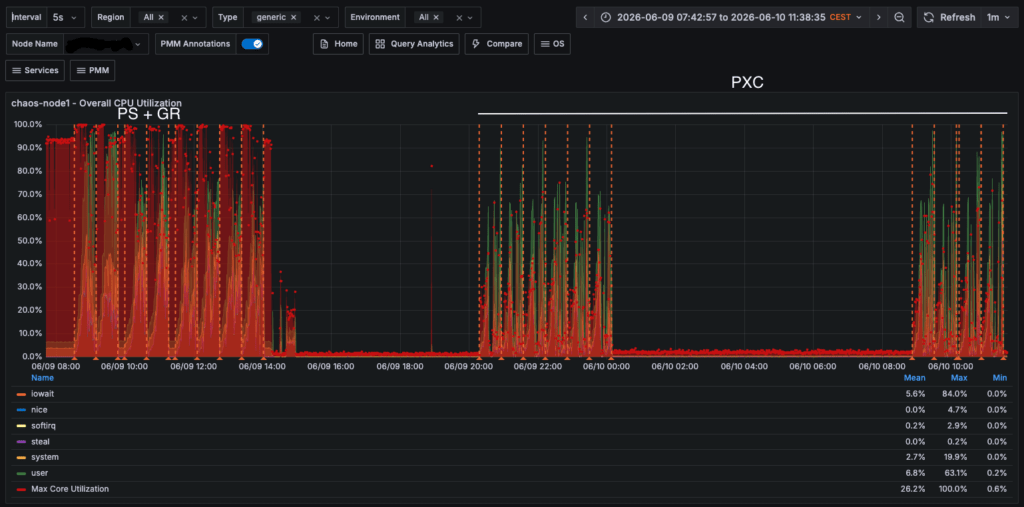
Cost that is reflected also as CPU utilization.
How impactful is enforcing strict consistency at a global level in a production environment? Massively. If you blindly enforce strict consistency globally without understanding your architecture, you will decimate your database throughput. Here is the reality of how the two solutions handle that tax:
The Final Verdict Modifying consistency values at the global server level should only be done after rigorous load testing and a complete understanding of the performance tax you are about to pay.
Ultimately, it comes down to choosing the right tool for your specific SLA:
https://docs.percona.com/percona-xtradb-cluster/5.7/wsrep-system-index.html#wsrep_sync_wait
Resources
RELATED POSTS




