
In this blog post, we’ll look at some common MongoDB topologies used in database deployments.
The question of the best architecture for MongoDB will arise in your conversations between developers and architects. In this blog, we wanted to go over the main sharded and unsharded designs, with their pros and cons.
We will first look at “Replica Sets.” Replica sets are the most basic form of high availability (HA) in MongoDB, and the building blocks for sharding. From there, we will cover sharding approaches and if you need to go that route.
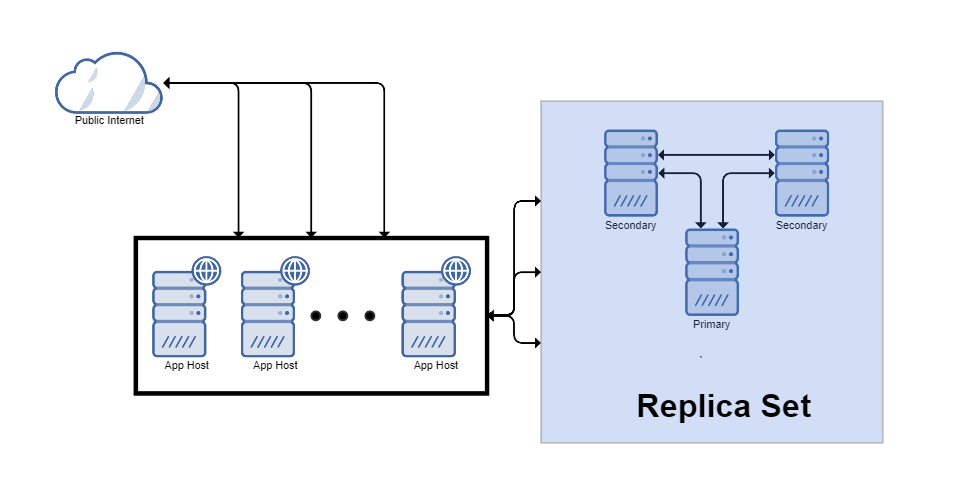
From the MongoDB manual:
A replica set in MongoDB is a group of mongod processes that maintain the same data set. Replica sets provide redundancy and high availability, and are the basis for all production deployments.
Short of sharding, this is the ideal way to run MongoDB. Things like high availability, failover and recovery become automated with no action typically needed. If you expect large growth or more than 200G of data, you should consider using this plus sharding to reduce your mean time to recovery on a restore from backup.
Pros:
Cons:
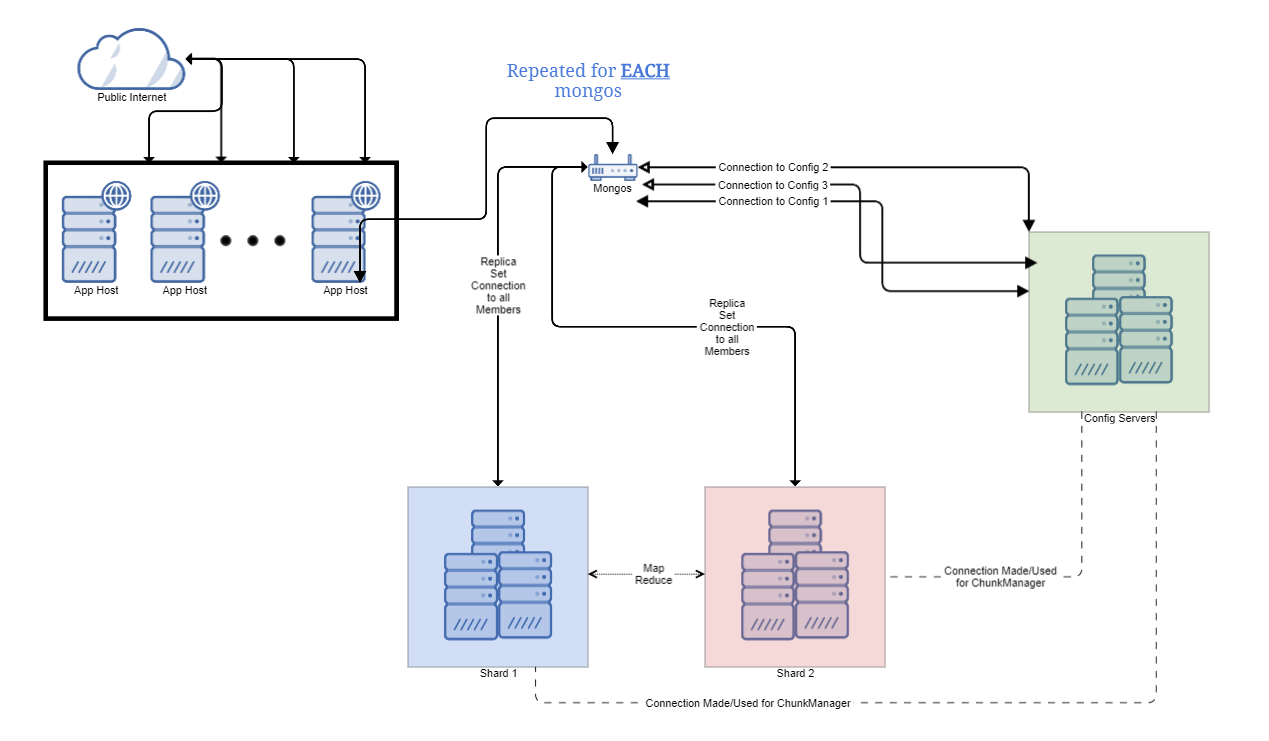
This is one of MongoDB’s more suggested deployment designs. To understand why, we should talk about the driver and the fact that it supports a CSV list of mongos hosts for fail-over.
You can’t distribute writes in a single replica set. Instead, they all need to go to the primary node. You can distribute reads to the secondaries using Read Preferences. The driver keeps track of what is a primary and what is a secondary and routes queries appropriately.
Conceptually, the driver should have connections bucketed into the mongos they go to. This allowed the 3.0+ driver to be semi-stateless and ask any connection to a specific mongos to preform a getMore to that mongos. In theory, this allows slightly more concurrency. Realistically you only use one mongos, since this is only a fail-over system.
Pros:
Cons:
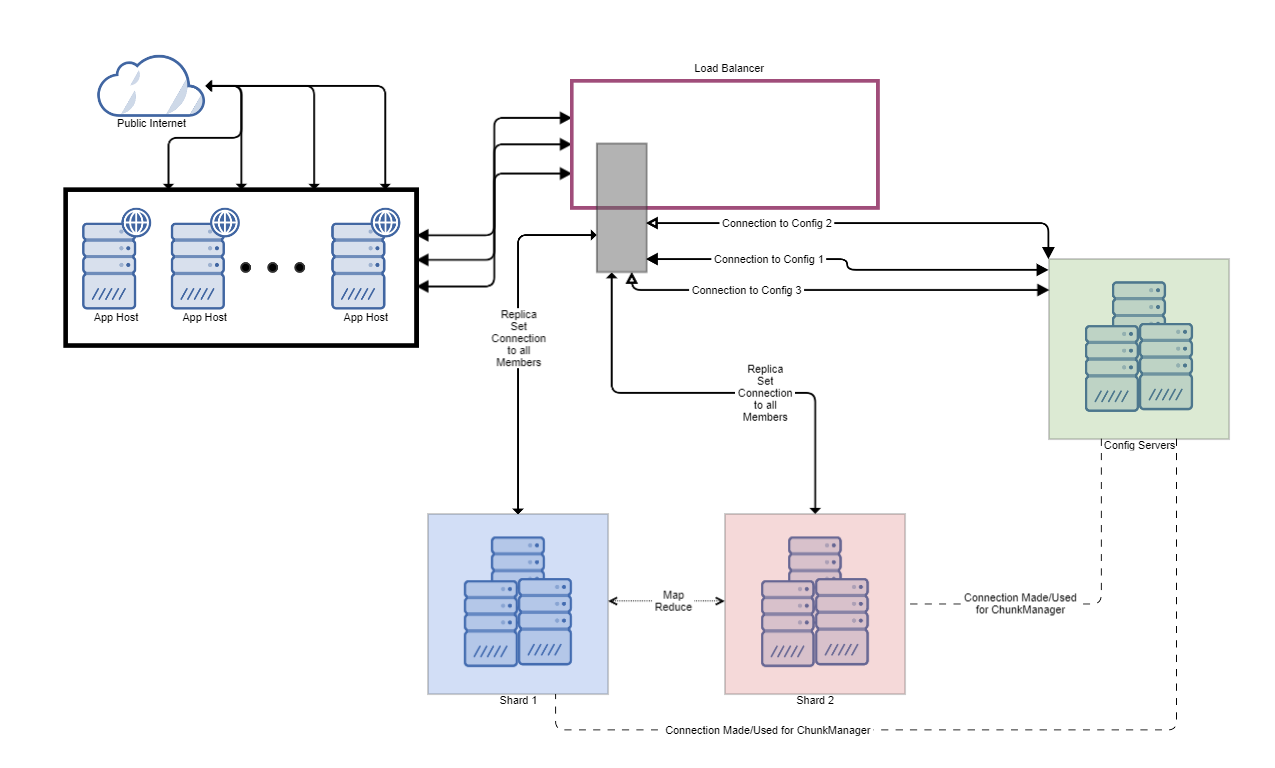
According to the Mongo docs:
You may also deploy a group of mongos instances and use a proxy/load balancer between the application and the mongos. In these deployments, you must configure the load balancer for client affinity so that every connection from a single client reaches the same mongos.
This is the model used by platforms such as ObjectRocket. In this pattern, you move mongos nodes to their own tier but then put them behind a load-balancer. In this design, you can even out the use of mongos by using a least-connection system. The challenge, however, is new drivers have issues with getMores. By this we mean the getMore selects a new random connection, and the load balancer can’t be sure which mongos should get it. Thus it has a one in N (number of mongos) chance of selecting the right one, or getting a “Cursor Not Found” error.
Pros:
Cons:
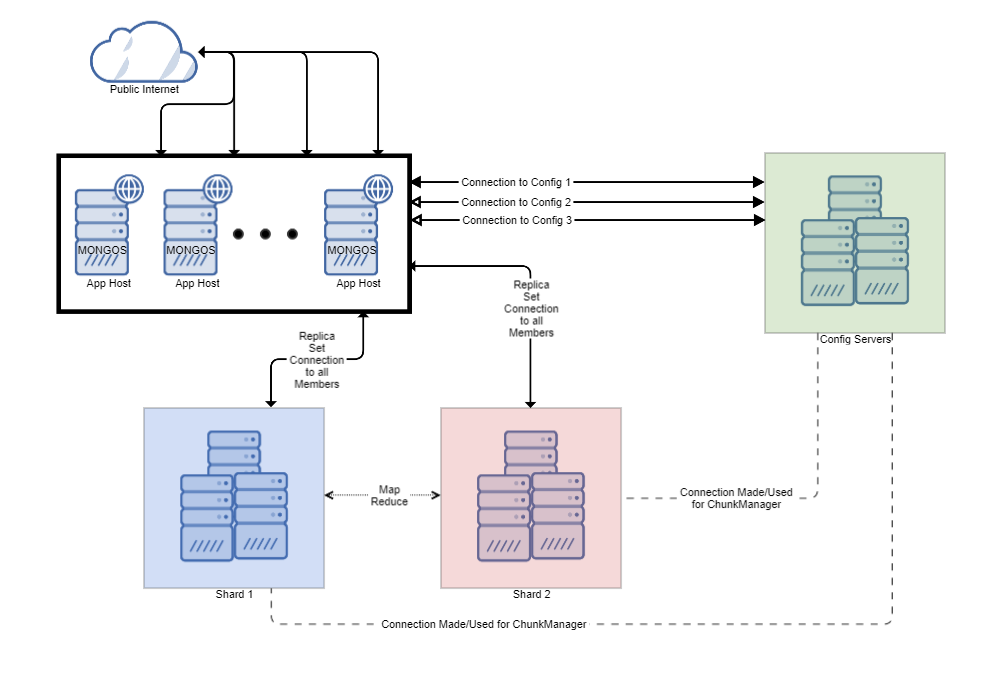
By and large, this is one of the most typical deployment designs for MongoDB sharding. In it, we have each application host talking to a mongos on the local network interface. This ensures there is very little latency to the application from the mongos.
Additionally, this means if a mongos fails, at most its own host is affected instead of the wider range of all application hosts.
Pros:
Cons:
The topologies are above cover many of the deployment needs for MongoDB environments. Hope this helps, and list any questions in the comments below.





very very thank you