
In this blog, we’ll review MongoDB 3.2 elections and how they work, as well as what is really new and different in the election protocol.
MongoDB 3.2 revamped its election protocol for increased stability! Exciting times, with smarter and faster elections are here! With this latest release, you will find that replication (and the election protocol) have been improved. Some of the changes include:
You’ll need to enable the Election Protocol when upgrading MongoDB from an earlier version, while new replSets get it enabled by default.
Mongo uses a consensus protocol. This means that all nodes must agree who is the most current when handing:
New updates allow for faster elections using an (term) electionId to prevent timeout between separate voting rounds. This guarantees there aren’t double (and conflicting) votes while also reducing the time to wait to know a vote completed.
Elections now have “term” or “vote” identifiers (ID). Terms are used to separate voting rounds. Every vote attempt increments the ID. The ID incrementation prevents a node from double voting in the same term, and makes it easier for nodes to know if a re-vote is needed where before it could be up to 5 minutes!
The protocol timeouts have some new features and behaviors:
Below I’m going to walk you through a typical replica set operation. The configuration looks like the following:
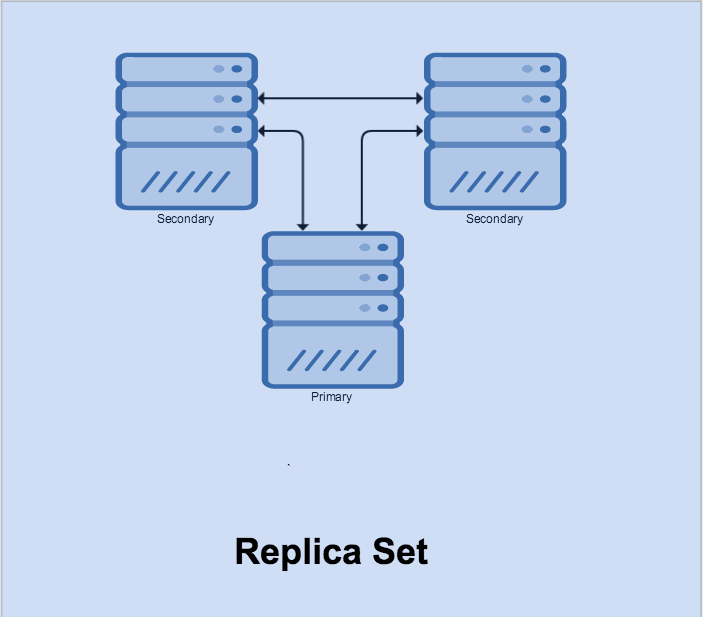
In this topology:
The following diagram provides a more detailed picture of the interactions:
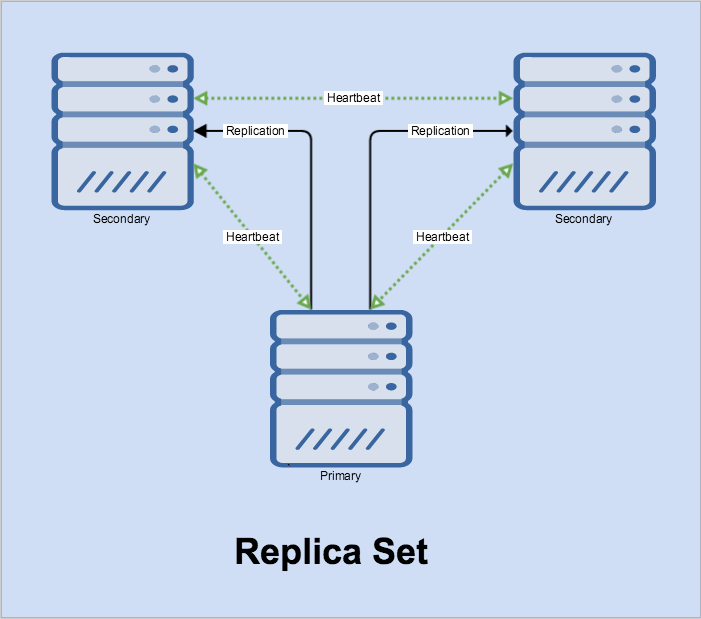
Notice how replication pulls from the primary to each secondary from the primary – the secondary does all the work. A heartbeat is still shared by all the nodes.
Now let’s see what happens when our primary crashes. It just did!
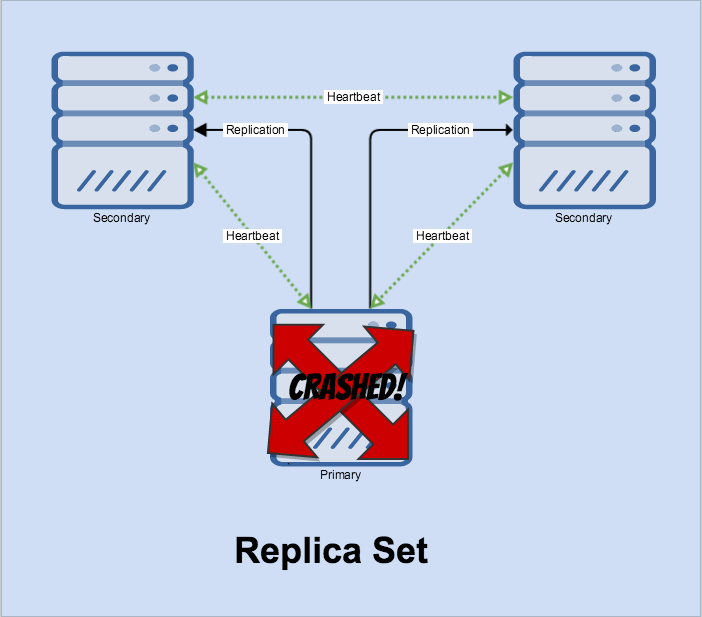
Nodes will still try to heartbeat to it until two have failed in a short period.
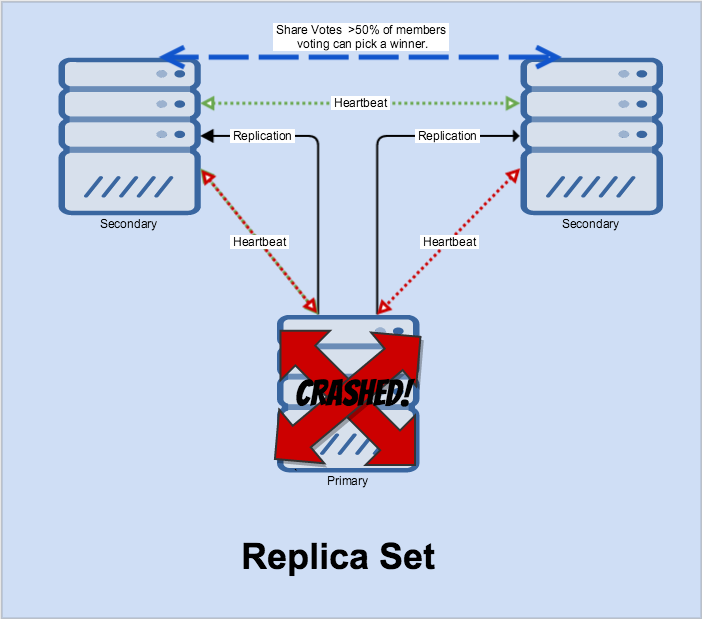
After the failure, things happen quickly.
A new Primary is selected, and the heartbeat system is cleaned up.
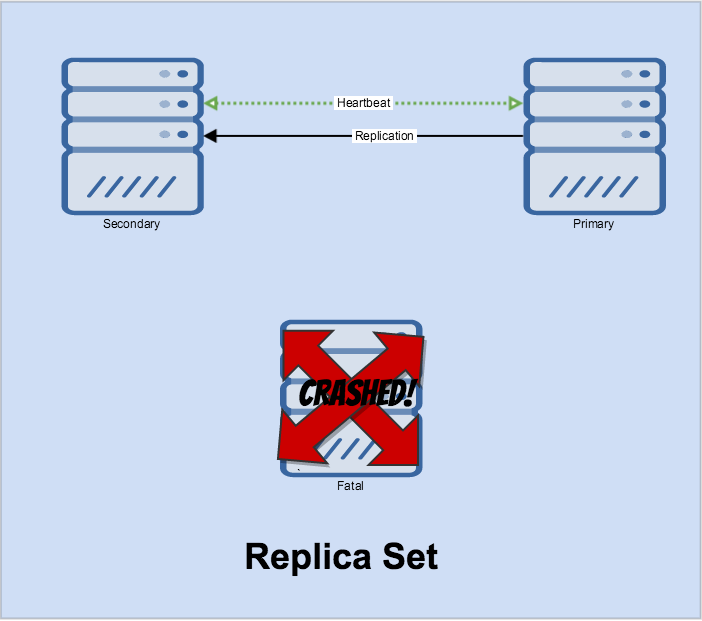
Replication now gets restarted. If the fatal node comes back online, it’s treated as a secondary once it “catches up” via the oplog.
The stepdown election process is the same as above, with the following caveats:
Generally speaking, you should always try to use the stepdown election process. Timeouts are for crashes and failures, not general
Resources
RELATED POSTS





Can you explain with more detail about ‘Network split’, ‘Time shifts’ ? Does MongoDB replica set election occur even if each server has a good health? Yours Sincerely
Mind structure flow diagram for databeses navigate in logical environement and not only one bit becouse sometime record information must be example: cascade – mixed. Vote increased poll – is idea.